¶ 1. 长文本编写需求
¶ 1.到底什么时候需要长文本?
长文本不是“字数越多越好”,而是当结构复杂、语义跨段、需要持续一致性时才有价值。典型需求:
-
叙事类创作
- 长篇小说、剧本、漫画设定书、游戏世界观文档。
- 关键难点:人物弧线、伏笔回收、时间线一致、世界观规则不自相矛盾。
-
商业与研究写作
- 行业研究报告、白皮书、竞品分析、市场洞察。
- 难点:章节逻辑递进、跨图表引用、结论与数据相互校验、参考文献管理。
-
企业知识与规范化输出
- 产品手册、实施方案、SOP、合规文档、FAQ 大库。
- 难点:术语统一、版本管理、政策/条款引用准确、跨章节一致性。
-
教学与培训内容
- 课程讲义、分级教案、试题解析、案例库。
- 难点:同一知识体系多层展开(入门→进阶→实战),跨章节衔接。
-
多轮交互驱动的生成
- “先确定大纲→部分试写→风格/受众确认→逐章产出→回收反馈修订”。
- 难点:每一次确认都要影响后续内容,必须“记住且贯彻”。
-
汇编/整合类输出
- 会议周报/月报、客户调研洞见、CS 工单沉淀、研发里程碑总结等。
- 难点:多来源信息合并、冲突消解、命名与口径统一。
结论:当你需要跨段逻辑、跨章一致性、跨轮决策传导时,就是“真正需要长文本”的时刻。
¶ 2.为什么有“大上下文(几十 K、甚至上百 K tokens)”还不够?
**上下文窗口 ≠ 可靠记忆 ≠ 可控流程。**实际落地会遇到这些硬问题:
-
注意力稀释与“中段遗忘”
- 窗口再大,注意力也会分散;越长越容易“前后用不上”,模型对关键约束“记不牢”。
- 结果:风格漂移、设定遗失、出现矛盾。
-
错误累积不可逆
- 一次性生成长文,中途出错难以回滚;后面再改会牵一发动全身。
- 工作流的“逐章-校验-修订”能把风险局部化。
-
成本与延迟不可控
- 超长提示一次塞入,费用与时延成倍上升;还难以复用中间结果。
- 分块生成+滚动摘要,能把成本按“章节/阶段”控制。
-
工具与事实约束无法插入
- 长文常需要查数据、调 API、检索材料、风格校准;
- 纯上下文里塞不进这些“行动”,需要流程级的工具调用与决策节点。
-
可观测性与可维护性差
- 一次吐出两万字,你很难知道“它为什么这么写”“哪段逻辑有问题”。
- 流程把“思考路径”拆成节点,可审计、可复现、可 A/B。
-
团队协作与版本控制
- 长文往往多人配合;整块生成难以在章节或任务层面协作。
- 流程化能按章节/子任务划分责任与验收标准。
因此,大上下文适合“参考更多材料”,但不解决“过程控制与长期一致性”。这正是工作流存在的意义。
¶ 3. 哪些具体场景“最好用工作流”来做长文本?
¶ 场景 A:长篇小说 / 剧本
-
目标:多卷本叙事、人物成长线、伏笔呼应。
-
痛点:设定丢失、人物性格跑偏、时间线错位、反复重写成本高。
-
为什么工作流:可把“世界观卡”“角色卡”“时间线卡”作为会话变量;逐章生成→每章摘要→用摘要喂下一章;每章出厂前经过“逻辑校验/风格统一”子流程。
-
流程骨架:
- 主题与世界观 → 2) 角色卡生成 → 3) 大纲与章设 → 4) 逐章循环:写作→一致性校验→风格校对→摘要固化 → 5) 全书汇编 → 6) 目录/引文/彩蛋。
¶ 场景 B:行业研究报告 / 白皮书
-
目标:结构化论证、数据支撑、统一术语、可追溯引用。
-
痛点:数据口径不一致、图表与文字不匹配、结论与证据脱节。
-
为什么工作流:RAG 检索事实、HTTP 调数据、代码节点做单位/口径标准化;章节级校验“论据-论点一致性”,统一术语表。
-
流程骨架:
- 提纲与指标定义 → 2) 数据抓取/清洗(代码/HTTP)→ 3) 逐章生成(引用片段+表格校对)→ 4) 术语与风格统一 → 5) 附录与参考文献自动汇编。
¶ 场景 C:产品手册 / SOP / 合规文档
-
目标:可执行、可审计、版本化维护。
-
痛点:不同作者口径不一致、改动处难以追踪、法条引用易出错。
-
为什么工作流:条款/步骤作为结构化变量;校验节点检查“禁止词”“高风险语句”;对版本差异做自动比对与变更日志。
-
流程骨架:
- 模板规范加载 → 2) 逐章节填充 → 3) 合规用语校验(代码/LLM)→ 4) 交叉引用检查 → 5) 版本打包发布。
¶ 场景 D:课程讲义 / 训练营讲义
-
目标:分层进阶、案例驱动、作业/答疑联动。
-
痛点:章节跨度大、同一案例在不同难度层面复用、风格易飘。
-
为什么工作流:先固化教学目标与难度分层卡;每章产出后摘要关键知识点,再统一风格卡;可插“问答生成”子流程形成练习题。
-
流程骨架:
- 教学目标卡 → 2) 大纲与层级 → 3) 逐章生成(案例+练习)→ 4) 关键点摘要 → 5) 风格统一/排版 → 6) QA 题库生成。
¶ 场景 E:多源信息汇编(周报/月报/竞品)
-
目标:从多渠道抓信息,统一口径形成长文。
-
痛点:来源不一致、重复/冲突信息多、人工筛选成本高。
-
为什么工作流:HTTP 拉取多源 → 代码去重与冲突合并 → 模型聚合抽象 → 统一风格输出;错误点能回到对应节点修正。
-
流程骨架:
- 数据拉取 → 2) 预清洗(代码)→ 3) 聚合摘要 → 4) 章节编排 → 5) 风格与口径统一 → 6) 导出/推送。
¶ 4.工作流做长文本的“关键设计要点”
-
分层结构化记忆
- 全局卡:世界观/术语表/角色表/受众画像。
- 局部记忆:每章“摘要+关键事实+未决问题”。
- 使用策略:后续只喂摘要与关键点,避免整章回灌导致稀释与昂贵。
-
迭代与校验闭环
- 每章节:内容生成 → 逻辑校验(人物设定、时间线、因果)→ 风格统一(语体、节奏、禁用词)。
- 校验可用 LLM 自评+代码检测双通道,必要时回滚修订。
-
工具与数据接入
- RAG:事实引用;
- HTTP:拉实时指标/价格/政策;
- 代码:数据清洗、度量统计、术语规范检查。
- 通过节点把“事实/规则”嵌进写作过程,而非事后修补。
-
成本与时延管理
- 章节化生成、滚动摘要、只携带必要上下文;
- 关键节点设定“短模板+刚性约束”,减少来回重写。
-
可观测与可回放
- 每个节点保留输入/输出与参数,定位“哪一步引入矛盾”;
- 重要节点打“版本号”,便于回滚与对比。
-
协作与验收
- 把“审稿标准/打分 Rubric”写成提示词或代码校验,机器先过一遍;
- 人只看“有风险/低分项”,把人工时间投入到关键处。
¶ 5. 什么时候“可以不必用工作流”?
- 只要一页文案、一个段落、没有前后一致性要求;
- 一次性写作,人工稍微润色即可;
- 对事实准确性、流程可复现性要求不高。
此时直接一个 LLM 节点(或 Chatflow 单轮)够用。
凡是跨段一致、跨轮传导、可审计与可维护的需求,就该上工作流。
¶ 结论
- 长文本的“必要性”来自结构复杂性、跨段一致性与可审计性,而不是单纯的“篇幅”。
- 大上下文解决“看更多材料”,工作流解决“如何稳、如何控、如何复用”。
- 用 Dify 把长文本写作拆成“可控的节点链”,把记忆、检索、工具调用、校验与回滚嵌进路径里,才能做出可维护、可升级、可交付的内容生产线。
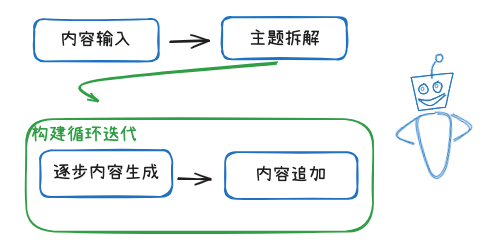
¶ 2. 长文本工作流实战
¶ Dify 里,长文本工作流的最小可行
-
开始节点(输入)
- 主题、目标受众、风格卡、约束项(禁用词/引用要求)、目标字数或篇幅。
- 初始化会话变量:
global_style,world_rules,character_bible,glossary,acc_outline,acc_chapters.
-
大纲节点(LLM)
- 产出章节列表(含每章摘要/关键点/依赖)。
- 写入:
acc_outline;生成术语初稿写入glossary。
-
迭代节点(按章节列表)
- 子流程:
a) 取“全局卡 + 该章摘要 + 之前章的滚动摘要” → 生成正文草稿;
b) 逻辑校验(LLM 或 代码):人物/设定/数据/引用;
c) 产出“本章摘要+关键事实”写入滚动记忆;
d) 将合格章节追加到acc_chapters。
- 子流程:
-
整书汇编节点(代码/LLM)
- 合并章节、生成目录、交叉引用检查、图表占位;
- 统一风格再走一遍;导出 Markdown/Docx/HTML。
-
发布/回写(HTTP)
- 推送到文档库/知识库;版本号/变更摘要记录。
¶ 3. 基础安装准备
目前使用的是优云智算的分时租赁方式 https://www.compshare.cn/
可以选择自行下载指定版本的dify
git clone --depth 1 --branch v1.9.1 https://github.com/langgenius/dify.git
也可以直到github中下载安装压缩包上传后进行解压安装
sudo apt install unzip
sudo apt install lrzsz
使用docker进行安装
cd dify
cd docker
cp .env.example .env
docker compose up -d

sudo usermod -aG docker $USER
启动新窗口

原有docker 配置文件 如果网络顺畅不需要进行额外的修改
/etc/docker/daemon.json :
{
"registry-mirrors": [
"https://dockerproxy.com",
"https://docker.m.daocloud.io",
"https://cr.console.aliyun.com",
"https://ccr.ccs.tencentyun.com",
"https://hub-mirror.c.163.com",
"https://mirror.baidubce.com",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://github.com/ustclug/mirrorrequest",
"https://registry.docker-cn.com"
]
}

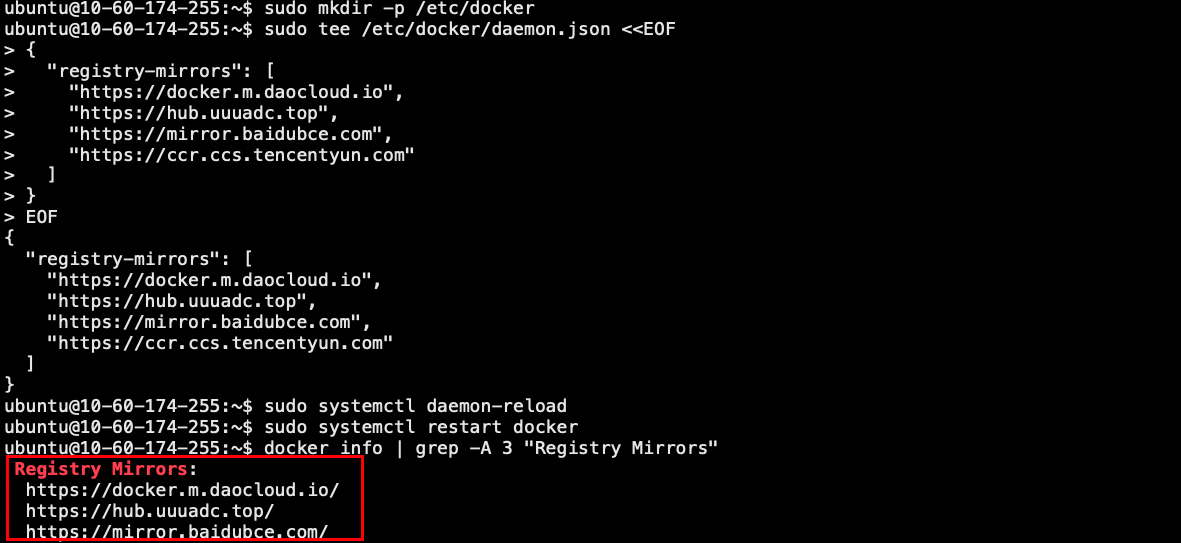
网络不好更改默认镜像
sudo rm -f /usr/bin/docker/daemon.json
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://hub.uuuadc.top",
"https://mirror.baidubce.com",
"https://ccr.ccs.tencentyun.com"
]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
docker info | grep -A 3 "Registry Mirrors"
docker compose ps

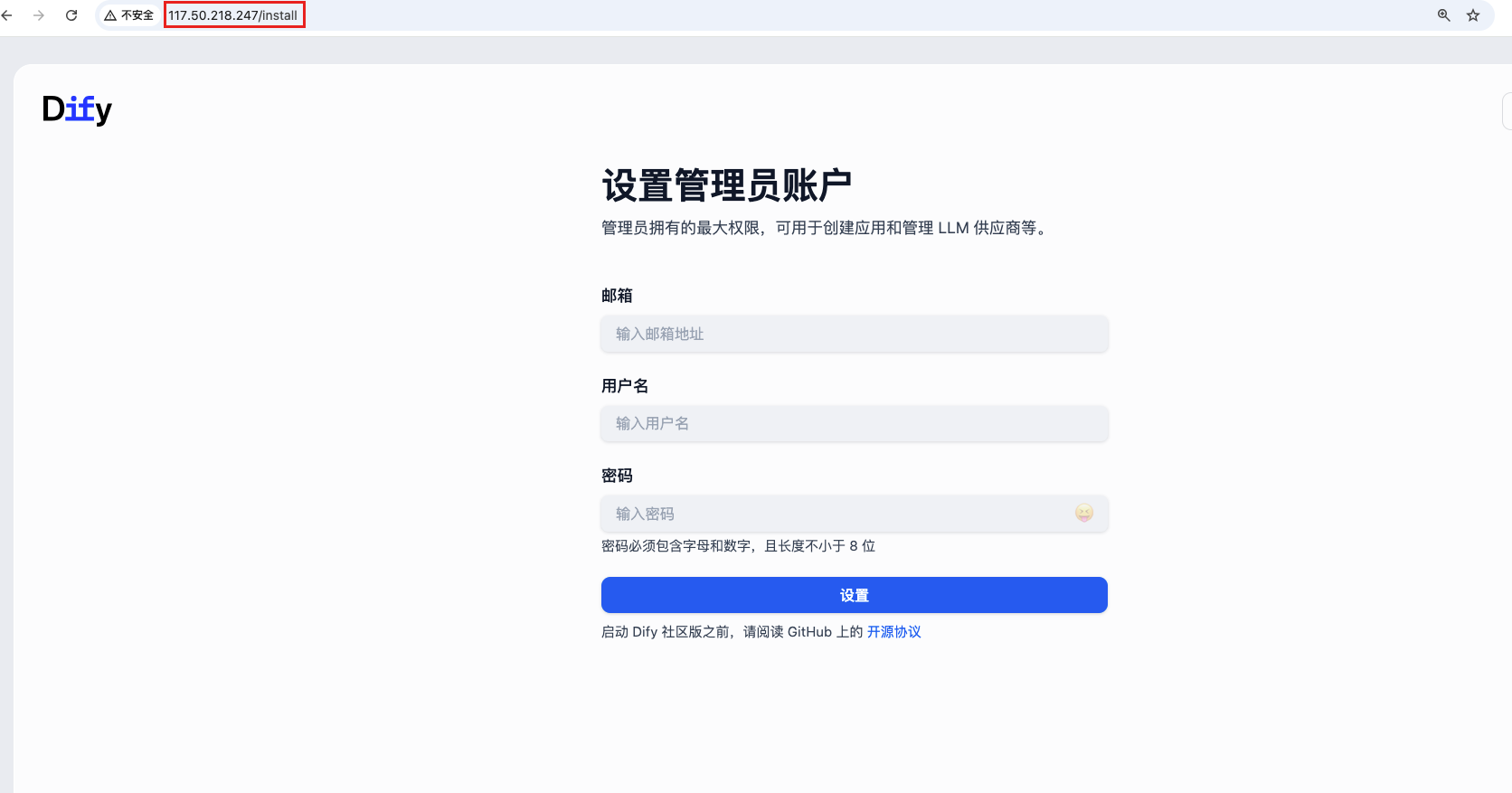
链接服务器IP访问初始化界面
配置模型供应商
原生自带供应商安装
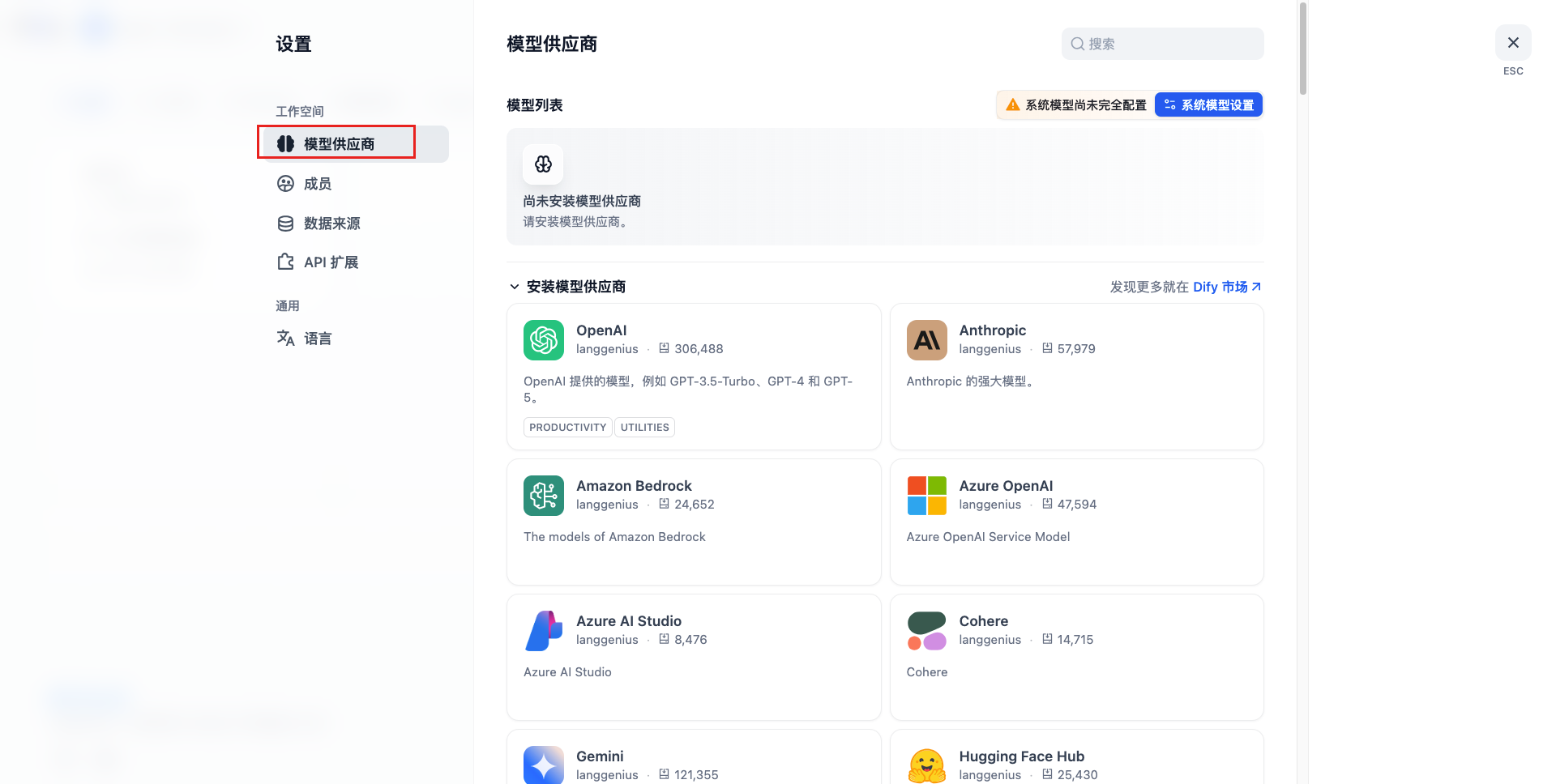
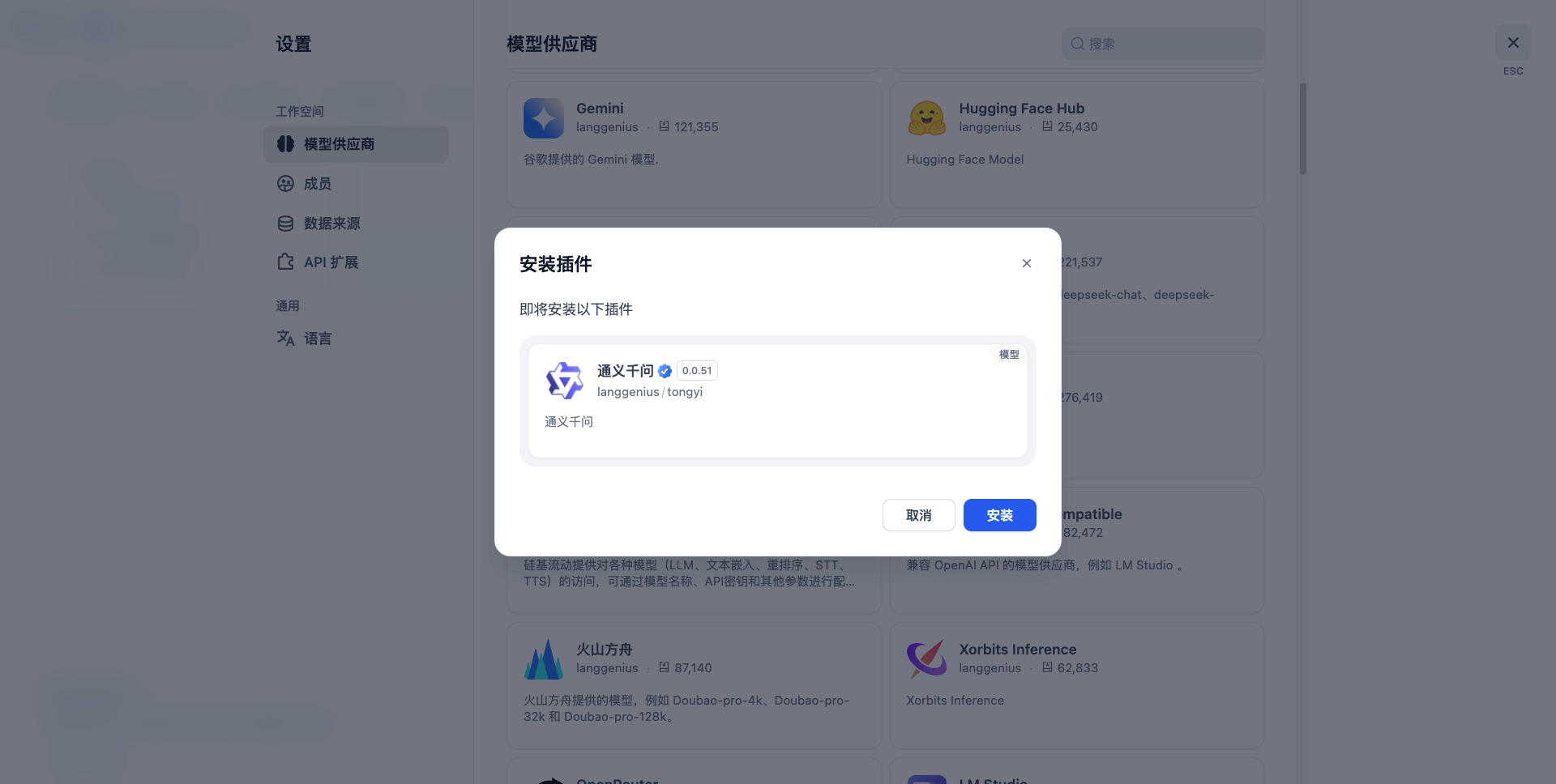
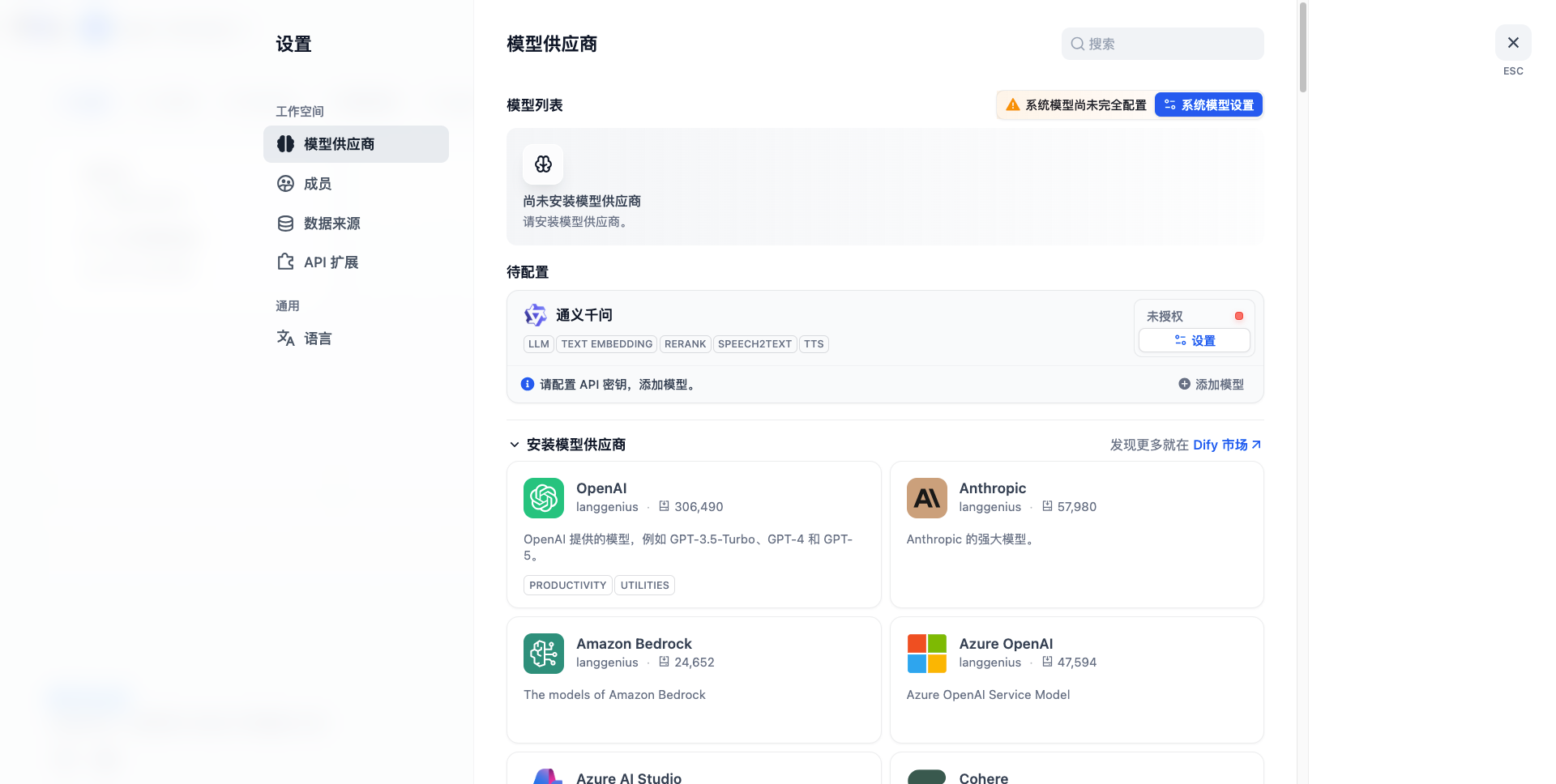
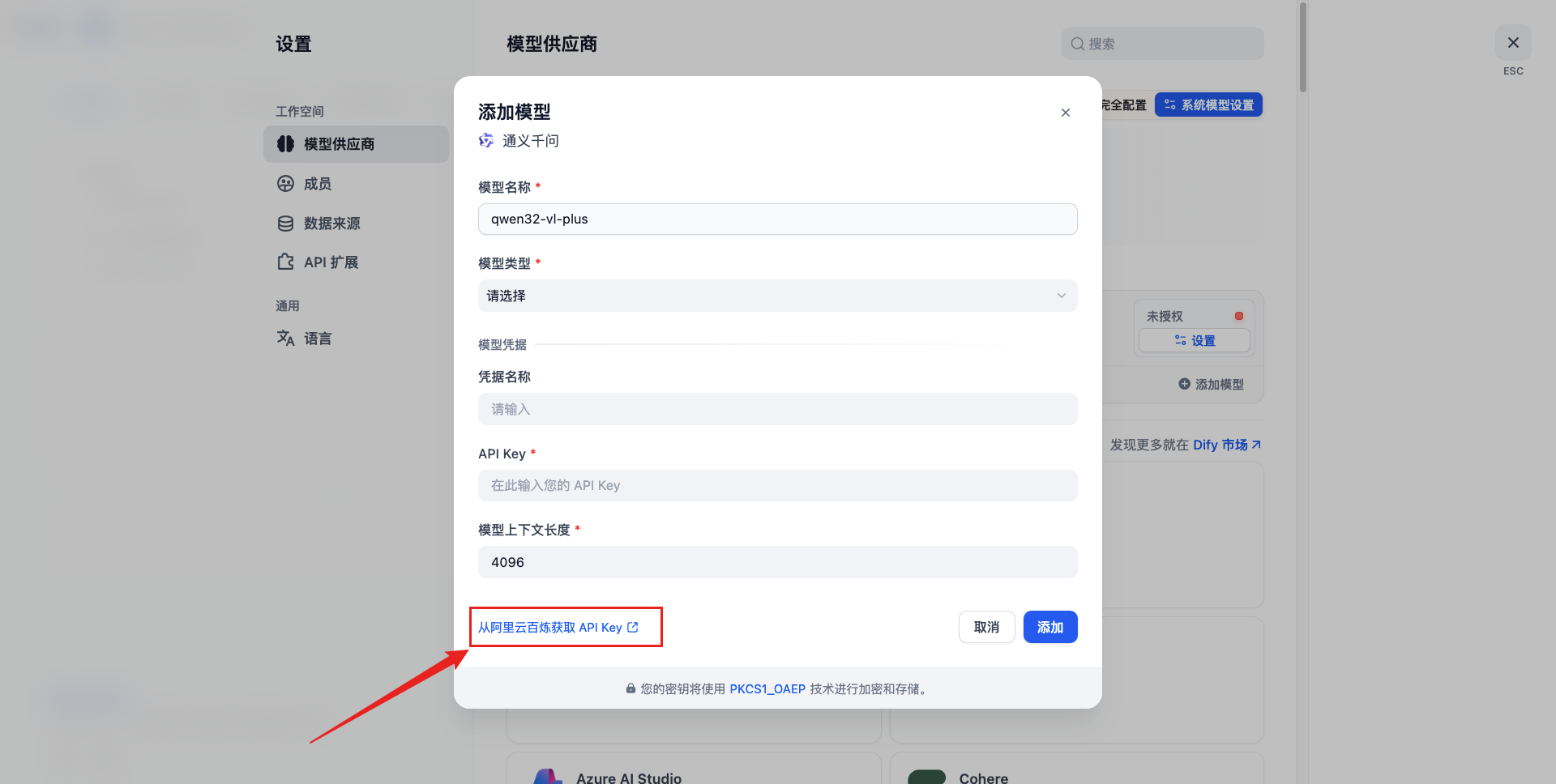
dify市场安装指定软件
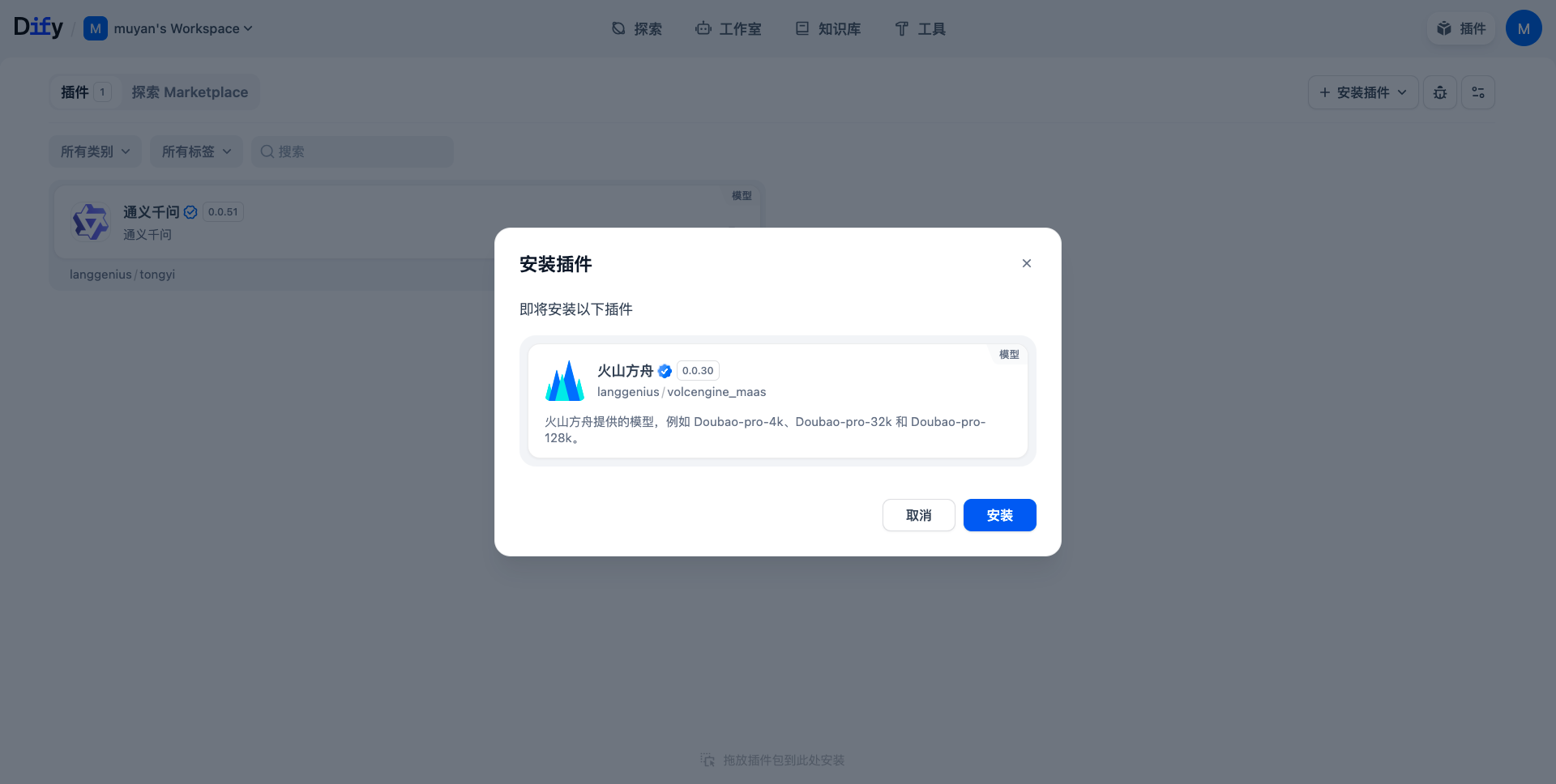
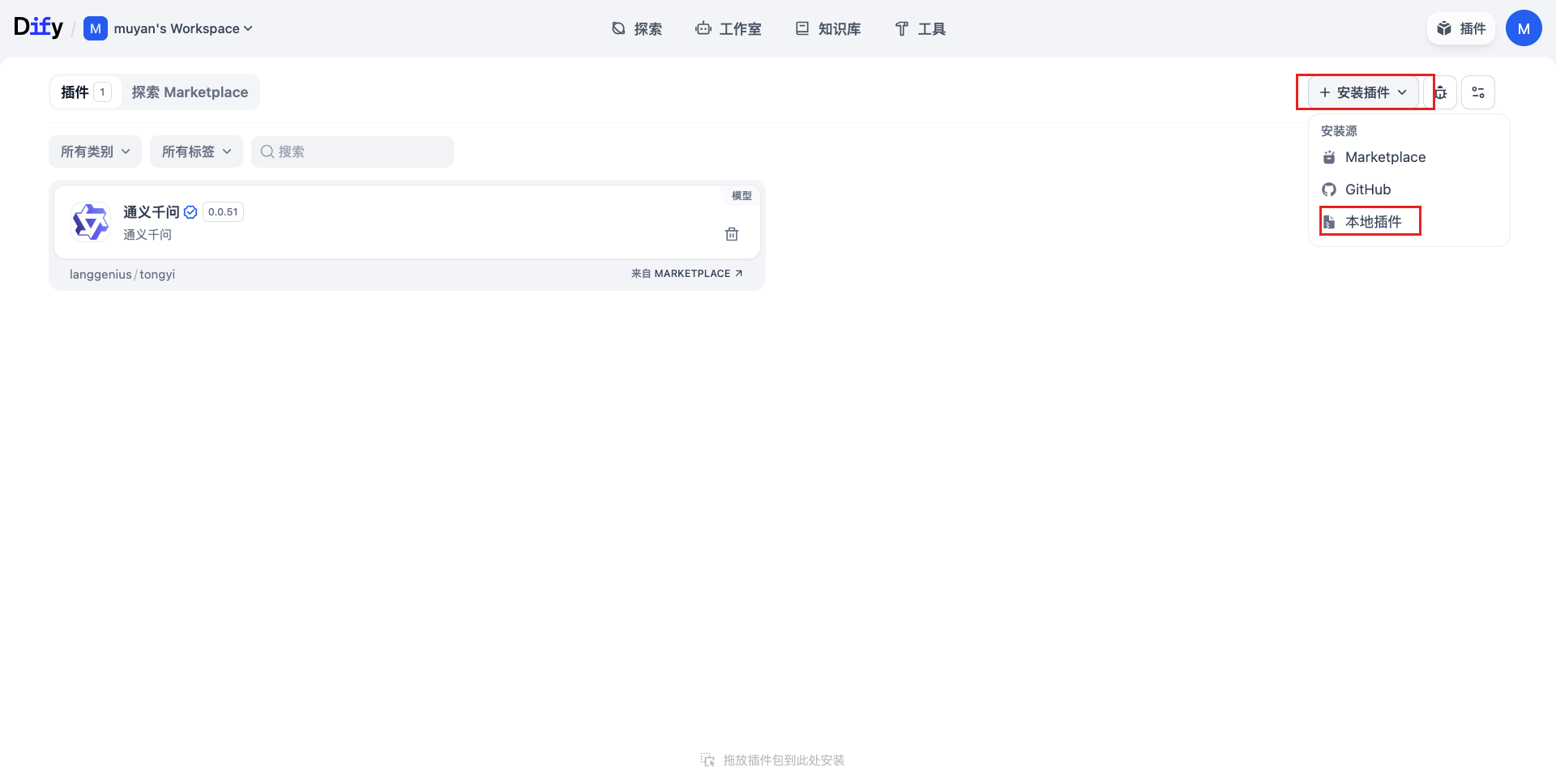
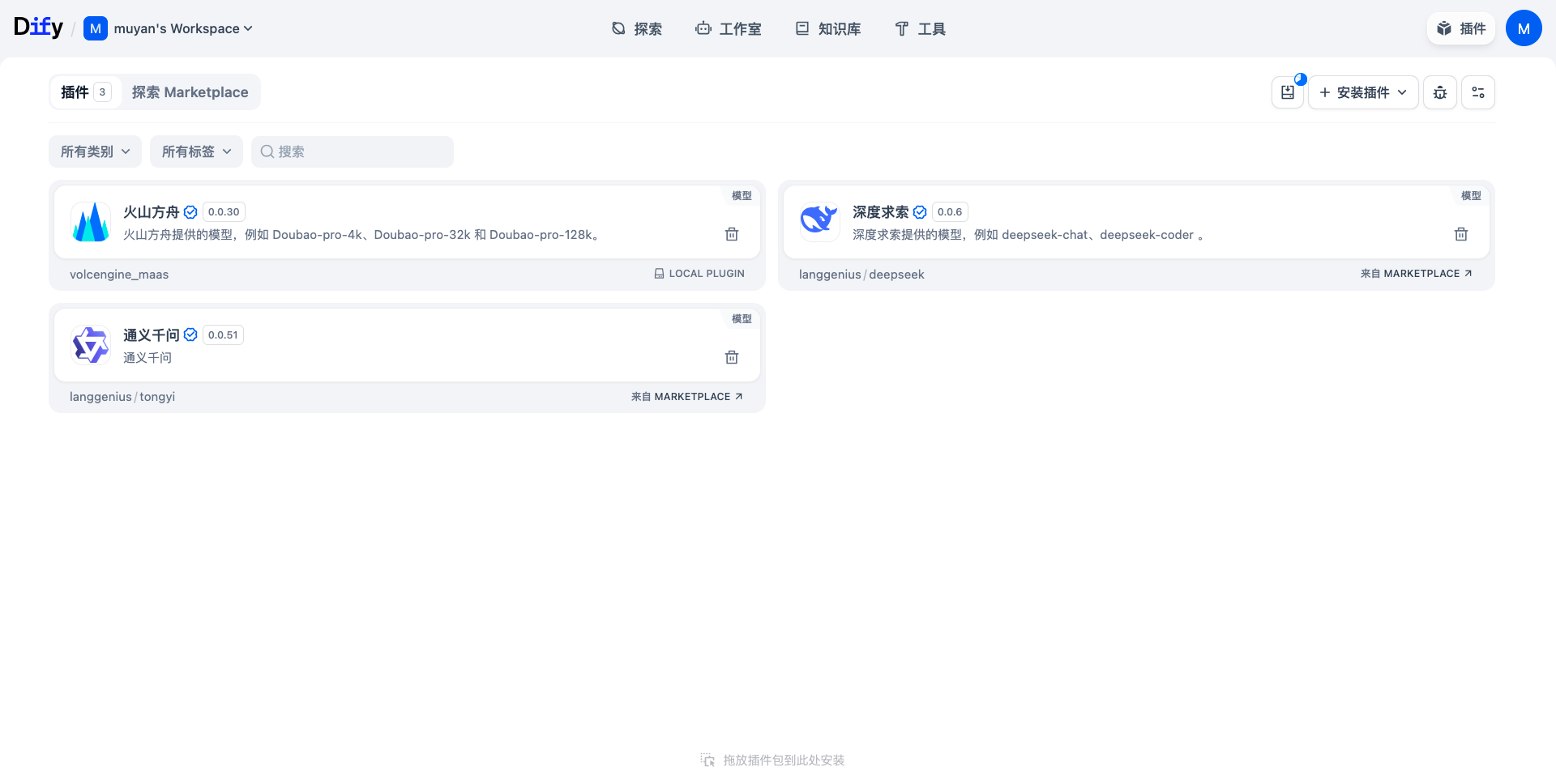
使用本地插件形式安装(推荐)
¶ 4. 工作流实战
¶ 1.为什么要把 Workflow / Chatflow 发布为工具 / 接口
在复杂长文本流程中,常常要做到下面几点:
- 复用流程:某些子流程(如“章节扩写”、“摘要生成”、“风格统一”)可在多个 Agent 或多个场景中复用。把它们做成 API 工具后,主流程里就能像调用函数一样按需调用,不用重复构图。
- 解耦与模块化:主流程尽量专注于“整体逻辑结构”,把具体执行细节抽成工具(子流程接口)。这样修改子流程时不破坏主流程。
- 分布式与权限管理:接口化后可以独立部署、分权、监控。工作流工具作为“微服务”被多个 Agent 或服务访问。
- 跨模型 / 跨入口:你可以从 Chatflow 调用工作流 API,也可以从 Agent 节点 HTTP 调用,还可以从外部系统、前端 UI 调用同一个流程。接口化让入口多元化。
因此,在 Dify 构建长文本系统时,把“核心子流程”封装成工具 / 接口是工程级的好实践。
¶ 2. Dify 中如何发布 Workflow / Chatflow 为“工具 / API 接口”
¶ 1 在 Dify 控制面板配置可对外调用的流程
-
启用发布 / 接口选项
在 Workflow 或 Chatflow 的设置中,有 “暴露为 API / 工具” 的选项(或“Deploy / Publish”按钮)。这一步会让该流程具备 HTTP 接口、工具插件(Tool)能力。 -
定义输入 / 输出 Schema
- 给流程入口定义固定的请求字段(如:
theme,chapter_id,history,style_card等) - 定义流程最终输出格式(通常 JSON 或特定结构)
- 确保流程里所有节点都基于这些标准字段操作
- 给流程入口定义固定的请求字段(如:
-
注册为工具 / 插件
- 发布后,流程会出现在 Dify 的“工具市场”或“插件”列表中
- 你可以在另一个流程 / Chatflow / Agent 节点里以“工具调用”方式引用它
- 工具调用节点通常只需传入一组参数,接收接口返回结果(JSON/文本/结构化)
-
生成 API 文档 / SDK
- Dify 通常会自动暴露接口文档(endpoint 路径、入参/出参格式、认证方式)
- 有时还可下载 SDK(如 JS/TS/HTTP 简易调用示例)以供前端或服务器调用
¶ 2 在 Agent 节点 / Chatflow 对话中调用流程接口
¶ A. HTTP 调用工具节点
- 在 Agent 的子策略里配置一个 HTTP 节点,向刚才发布的流程接口发 POST 请求
- 把 Chatflow / Agent 当前状态变量(如主题、历史、章节等)作为请求 body 入参
- 接口返回结果(如扩展后的段落 / 新章节 JSON),Agent 接收后继续下一步处理 / 回传用户
这种方式适合你已经把流程“封装成 API”的场景。
¶ B. 直接内部工具节点调用
- 如果你在同一个 Dify 实例里发布了流程工具,则可以在另一个流程 / Chatflow 中将它作为“节点”拖入(类似调用子函数)
- 传入必要变量,节点内部会执行该工作流并返回结果供后续节点使用
- 优点:调用更直接、权限控制可在内部,延迟较低
¶ C. 客户端 SDK / Webhook 调用
- 在流程被发布为 REST API 后,你的客户端(前端、服务层)也可以直接调用它,生成或扩充文本
- 这适合你把 Dify 作为“后端写作服务”部署在业务系统里
- Agent 节点也可作为桥梁:客户端发请求给 Chatflow,Chatflow 再内部调用子工作流接口
¶ 3.技术上的注意点与坑
-
接口稳定性与版本管理
- 当子工作流被多重调用,不要轻易改入参/出参结构,否则破坏兼容性
- 建议给每个流程工具设定版本号(如
v1.0、v1.1) - 对外接口文档要写清楚字段含义、必填/选填、返回错误码
-
权限与认证
- 对外 API 接口要有鉴权(API key / Token / JWT)
- 内部工具调用也要限制访问级别,避免流程被滥用
- 如果流程包含敏感信息或公司机密,要做 IP 白名单或内网限定
-
超时与降级策略
- 子流程接口可能因模型响应慢、网络延迟导致超时
- 推荐在调用节点配置 fallback(例如部分返回简版、降温写作、返回错误提示)
- 使用 streaming 模式逐步返回部分产出,而不是等全部写完
-
上下文与变量同步问题
- Chatflow → Workflow 的接口调用要把所有必要上下文(风格卡、历史摘要、角色卡、已写章节摘要…)打包完整
- Workflow 执行后的返回要带上新变量(例如新写章节的摘要 + 写作内容)
- 注意“变量名一致性”与“数据格式一致性”
-
错误传播与审计
- 子流程发生错误要有明确报错信息(HTTP 状态码 + 错误 JSON)
- Chatflow / Agent 调用要捕获错误并可 fallback,不能让用户看到内部异常堆栈
- 在日志 / 审计系统里记录“流程调用栈 + 输入/输出快照”,便于事后问题排查
-
资源隔离与负载控制
- 子工作流可能被高并发调用,要避免“写作爆炸”导致模型资源被拖死
- 可以给子工具流程加并发限制、排队队列或异步触发
- 对于“大写章节”任务,考虑拆块异步写作 + 汇总
¶ 工作流实操
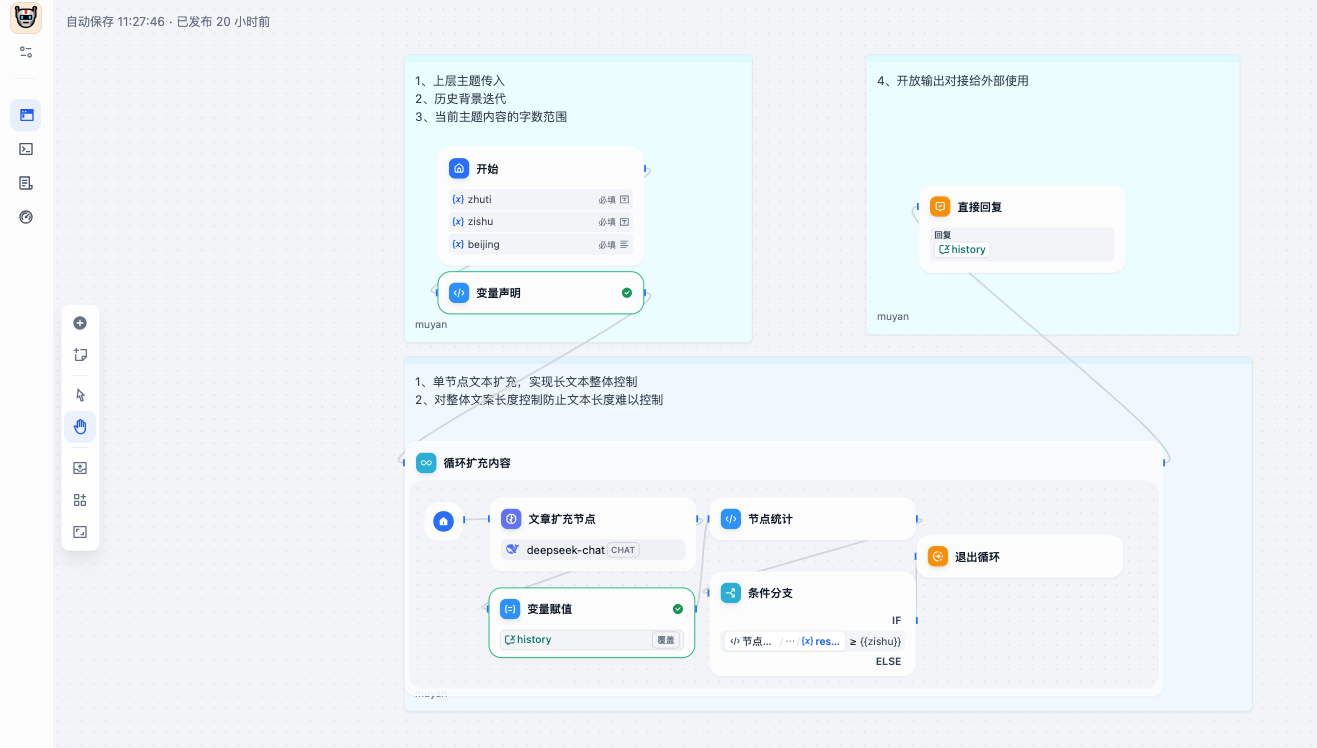
¶ 主工作流讲解
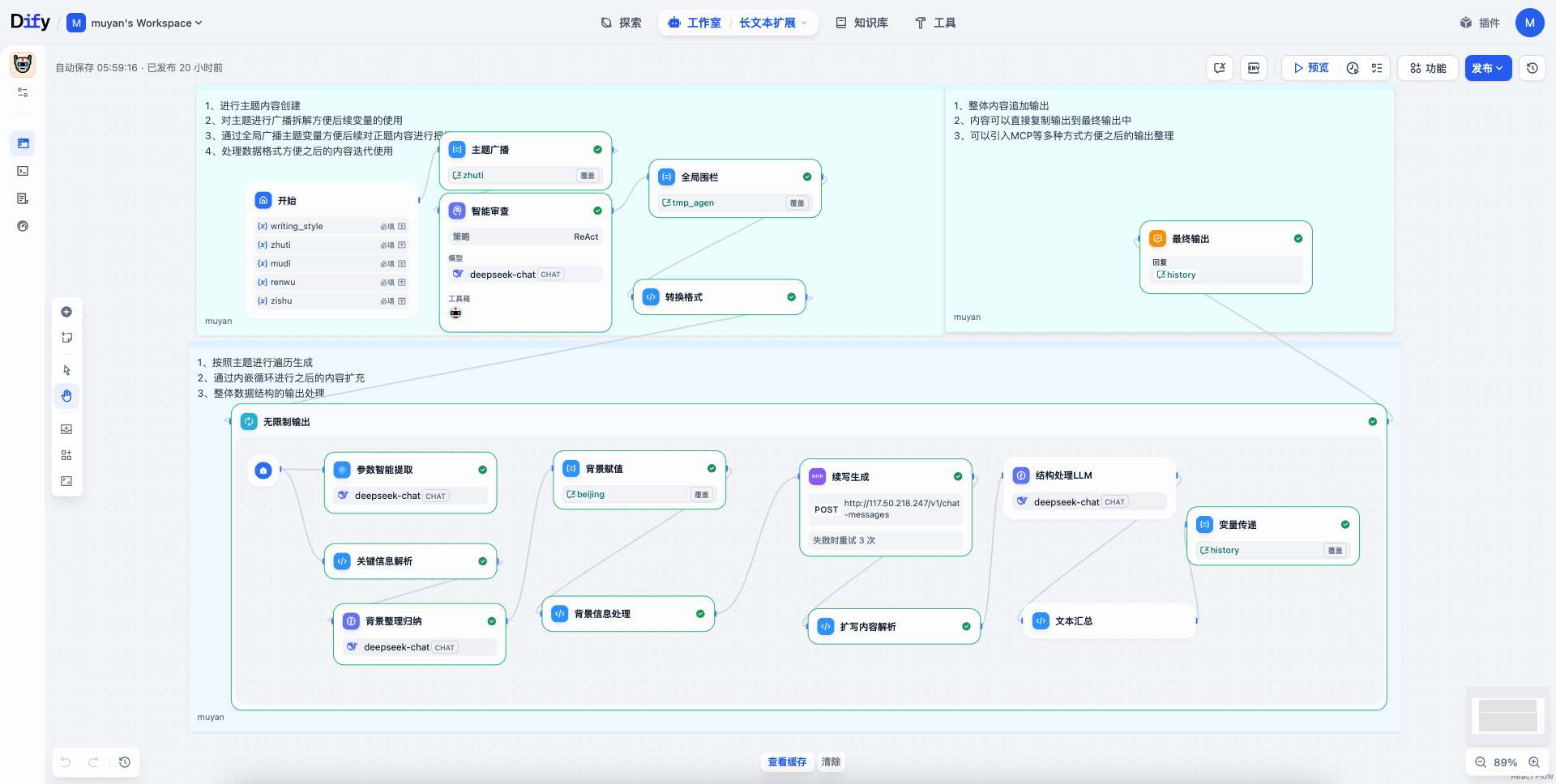
¶ 长文本工作流创建
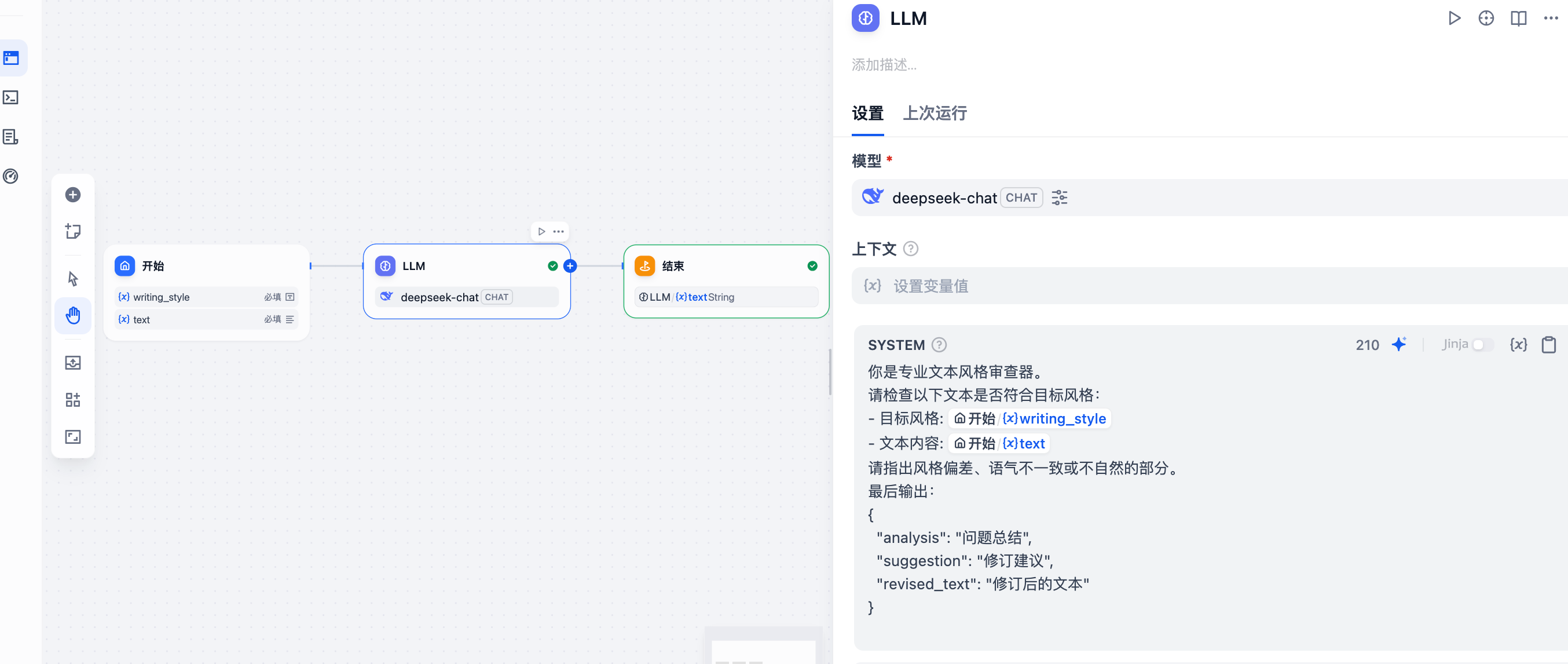
¶ dify内部工具创建
¶ 5. 跨行业长文本核心
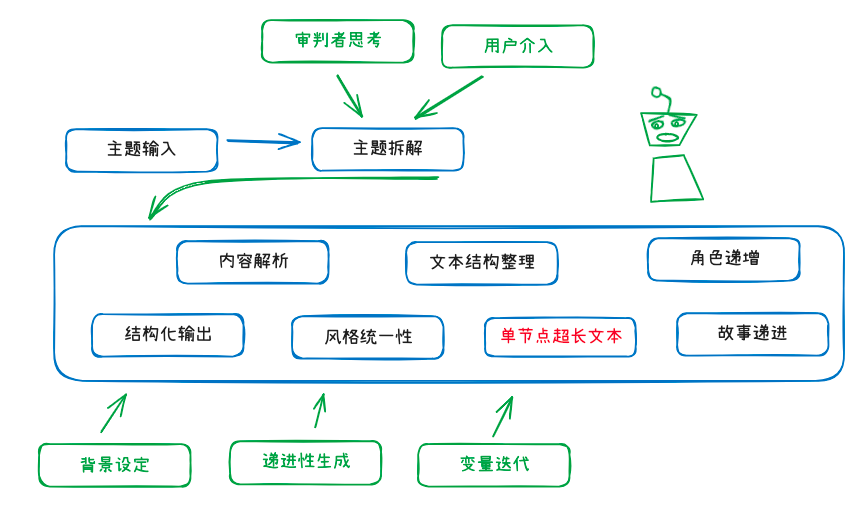
¶ 通用工作流骨架(适用于全部行业)
-
主题拆解 Agent(Planner)
输入:{{zhuti}}、目标文种、受众、{{zishu}}。
输出:结构化outline(数组),含每节目的、关键要点、所需证据/素材、预估字数。 -
审判者(Regulator / Reviewer)
对outline或分节草稿进行:体裁合规、逻辑一致、事实/引用与格式检查。输出打分 + 必改清单。 -
迭代扩写(Writer per item)
按{{item}}扩写,严格遵循体裁模板与“必须修改”清单;生成正文与本节摘要、关键事实。 -
风格/术语统一(Style Harmonizer)
按{{writing_style}}与术语表{{glossary}}做最小幅度改写;输出定稿。 -
可选:引用与附录生成(Citations/Appendix)
将{{refs}}格式化为参考文献或法规条款附录。
¶ A.「指定格式的行业报告」场景(市场/战略/研究报告)
¶ 角色 1:主题拆解 Agent(Planner)
系统指令
你是资深行业研究员。目标是把“{{zhuti}}”拆解为可执行的行业报告大纲。
约束:
- 体裁:行业研究报告(摘要、背景、市场规模与增速、供需格局、竞争格局、产业链、政策与风险、趋势与建议)
- 受众:业务/管理层
- 输出必须是 JSON,字段见 schema。
- 每一节给出:写作目的、关键结论要点(bullet)、需要的证据类型(数据/报告/法规)、建议图表类型、预估字数(整数)。
调用指令(用户提示)
请基于主题“{{zhuti}}”,目标字数上限 {{zishu}},给出全报告大纲。
若历史上下文存在,需保证与 {{history}} 一致。
写作风格参考:{{writing_style}}。
期望输出(JSON Schema)
{
"core_goal": "string",
"sections": [
{
"title": "string",
"purpose": "string",
"bullets": ["string"],
"evidence_needed": ["宏观数据","公开年报","第三方测算","政策原文或权威解读"],
"chart_suggestion": ["柱状图","折线图","堆叠面积","桑基图"],
"estimated_words": 800
}
],
"global_constraints": {
"terminology": ["统一术语1","统一术语2"],
"forbidden": ["夸大性词汇","不确定却肯定的断言"]
}
}
¶ 角色 2:审判者(Regulator/Reviewer)
系统指令(大纲评审)
你是报告总编,依据以下 Rubric 为大纲打分并给出“必须修改项”:
维度:
- 结构完备(0-5):是否覆盖摘要、市场规模、供需、竞争格局、产业链、政策风险、趋势建议
- 逻辑递进(0-5):从现状→问题→分析→建议是否清晰
- 可证据性(0-5):每节是否给出可验证的证据类型
- 与历史一致(0-5):是否与 {{history}} 关键假设一致
仅输出 JSON:
{
"scores": {"structure":0,"logic":0,"evidence":0,"consistency":0},
"must_fix": ["..."],
"suggestions": ["..."],
"verdict": "pass | revise"
}
系统指令(分节草稿评审)
你是事实与体裁审稿官。检查【本节草稿】:
- 是否匹配本节 purpose 与 bullets
- 是否给出可证据化陈述(用“可验证标记”标注,如 [需要数据-人口渗透率])
- 禁用词与夸张表达是否出现
- 字数在 estimated_words±15%
仅输出 JSON(同上),并给出 “must_fix”。
¶ 角色 3:分节扩写(Writer)
系统指令
你是行业报告撰写人。请在不虚构具体数据的前提下,先写结构,再留证据位。
要求:
- 段首给出“本节结论一句话”
- 正文结构:现状→驱动/阻力→对比→结论→建议
- 用占位符标注证据位,如【证据-市场规模近三年CAGR】、【证据-TOP5份额】
- 字数目标:{{item.estimated_words}}±15%
- 仅输出 Markdown,禁止无关说明。
调用指令
本节标题:{{item.title}}
写作目的:{{item.purpose}}
关键要点:{{item.bullets}}
风格:{{writing_style}}
术语表:{{glossary}}
历史对齐:{{history}}
¶ 角色 4:风格/术语统一(Harmonizer)
系统指令
根据“风格卡”和“术语表”对文本做最小幅改写:
- 不改变事实与结构
- 统一口吻、句长、标点
- 术语替换为首选项
输出 Markdown 正文。
¶ 行业必要工具
- HTTP 数据拉取:统计局、第三方数据 API(返回 JSON 后在代码节点清洗单位、口径)
- RAG 检索:年报、研报、政策原文向量库,返回证据片段
- 代码节点:字数/格式/禁用词/“证据占位符”是否齐全、图表数据校验
- 引用生成器:把证据位与
{{refs}}合并成参考文献区
¶ B.「政务/公文」场景(通知、请示、报告、方案等)
¶ 角色 1:主题拆解 Agent(Planner)
系统指令
你是机关文字秘书。把“{{zhuti}}”拆解为符合《党政机关公文处理工作条例》与通用公文体例的大纲。
体裁:请指定(如“请示/报告/通知/方案/通报”等),若未指定由你根据意图推断并给出理由。
每节包含:功能定位、核心信息点、依据信息(法规/上级精神/会议纪要)、需落款/时间/附件清单、预估字数。
输出 JSON,见 schema。
调用指令
请为主题“{{zhuti}}”生成公文大纲,目标字数 {{zishu}},风格“{{writing_style}}”。
若有历史上下文 {{history}},需保持政策口径一致。
期望输出(JSON)
{
"doc_type": "请示 | 报告 | 通知 | 方案 | 通报",
"sections": [
{
"title": "string",
"function": "背景/目的/依据/措施/落实/结语",
"bullets": ["string"],
"policy_basis_needed": ["条例/意见/会议精神"],
"estimated_words": 500
}
],
"footer": {"issuer":"单位","date":"自动生成","attachment_list":["..."]}
}
¶ 角色 2:审判者(体裁与合规)
系统指令
你是政务公文审稿官,请根据体裁规则检查结构与表述是否合规:
- 体例检查:标题、主送、正文结构、成文日期、印发范围、落款
- 用语检查:不得出现口语化、情绪化、商业化词汇;引用法规需注明全称与文号占位
- 政策一致:与 {{history}} 的上级精神/既有口径不冲突
- 字数符合约束
输出 JSON:scores、must_fix、verdict。
¶ 角色 3:分节扩写(Writer)
系统指令
你是机关公文写作者。按体裁与功能定位写作:
- 每节先给“一句话要点”
- 用“依法依规”“经研究,拟提出如下意见”等规范表述
- 对法规引用用占位符【法规-名称-文号-条款】
- 严禁夸张形容词与不确定承诺
- 字数 {{item.estimated_words}}±10%
输出为公文体 Markdown。
¶ 角色 4:风格/术语统一(Harmonizer)
与上类似,但词表需加入“政务用语规范表”。
¶ 行业必要工具
- RAG/法规库:法规原文、文号、条款检索
- 格式检查代码:是否含主送/抄送/印发/落款/成文日期;禁用词扫描
- 编号生成器:文号、自增编号、附件清单生成
- 审批流对接(可选):HTTP 推送到 OA/协同系统
¶ C.「数据报告 / BI 报告」场景(指标解读、可视化说明)
¶ 角色 1:主题拆解 Agent(Planner)
系统指令
你是数据分析项目负责人。围绕“{{zhuti}}”,给出数据报告大纲。
每节需明确:
- 指标集合与口径定义(分子/分母/时间窗/维度/排除项)
- 需要的图表类型与最重要的切片维度
- 业务假设与验证方法(AB/对照/回归/分层)
- 风险与数据质量关注点
输出 JSON。
调用指令
请在 {{zishu}} 字数上限内,生成可执行的数据报告大纲。风格 {{writing_style}},历史一致性 {{history}}。
期望输出
{
"sections": [
{
"title": "核心指标与口径",
"metrics": [
{"name":"DAU","formula":"UV 日活","window":"D","dimension":["渠道","地区"],"exclusion":["内测账号"] }
],
"charts": ["时序折线","分渠道柱状"],
"analysis_plan": ["分层对比","显著性检验"],
"estimated_words": 600
}
]
}
¶ 角色 2:审判者(指标/口径与因果)
系统指令
你是分析规范审稿官,检查本节草稿:
- 指标口径是否与定义一致(分子/分母/时间窗/去重规则)
- 结论是否仅基于可观察相关,而未误导为因果(如无实验设计)
- 图表描述是否与指标匹配(如累计 vs 日、均值 vs 中位数)
- 数据质量声明是否充分(缺失/异常/截尾说明)
输出 JSON:scores、must_fix、verdict。
¶ 角色 3:分节扩写(Writer)
系统指令
你是数据分析师。生成本节正文:
- 先给“结论摘要(要点列表)”
- 逐条解释图表应展示的故事与预期验证方式
- 严禁虚构数据;用占位符【数据-指标-时间窗-维度】标注数据位
- 若可能存在“选择偏差/混杂”,需显式注明“风险与限制”
- 字数 {{item.estimated_words}}±15%
输出 Markdown。
¶ 角色 4:风格/术语统一
- 统一“指标命名/英文缩写/符号”,长度单位、金额单位、百分号格式,中文/英文空格规范。
¶ 行业必要工具
- HTTP 数据接口:指标服务/仓库 API
- 代码节点:指标口径校验、单位与小数位格式化、图表数据整理
- 图表生成器(可选):将返回的数据生成可视化链接/图片占位
- 数据质量扫描:缺失率/极值/异常点提示
¶ 通用「审判者 Rubric」
系统指令(共用)
你是审稿官。请针对【候选文本】与【任务约束】进行评审,输出 JSON:
维度与分值:
- 结构匹配(0-5)
- 目的达成(0-5)
- 证据可验证性/口径一致(0-5)
- 风格与术语一致(0-5)
- 历史一致(0-5)
阈值:任意一项 <3 或平均 <4 则 verdict=“revise”
输出:
{
"scores": {...},
"must_fix": ["逐条、可操作的修改点"],
"suggestions": ["可选优化"],
"verdict": "pass | revise"
}
仅输出 JSON。
¶ 网盘资料
https://pan.baidu.com/s/10FFRqK16UxRNn8d2Y1mgyg?pwd=dkq2 提取码: dkq2