¶ 1 开场:从智能体⼤普及到驾驭难题
¶ 1.1 智能体的奇点时刻
2026 年的 AI 模型,已经强⼤到让⼈重新定义"可能"这个词。
GPT-5.4 在 3 ⽉ 5 ⽇发布,⽀持 100 万 token 上下⽂窗⼜和原⽣ Computer Use(计算机操控)能⼒,推理效率⽐前代提升 33%。Claude Opus 4.6 在 2 ⽉ 5 ⽇上线,同样拥有 100 万 token 上下⽂、12.8 万 token 的超长输出,以及被 Anthropic 称为"有史以来最⾼智能体编码分数"的实⼒。这两个模型代表了当前⼤语⾔模型的能⼒天花板——它们不只是"能聊天",⽽是真正具备了长时间⾃主⼯作的基础能⼒。
但模型的强⼤,要有⼈把它变成⽣产⼒。
Claude Code:编码智能体率先突破
Anthropic 内部做了⼀个疯狂的实验:让 16 个 Claude Agent 并⾏协作,在⼀个共享代码仓库⾥从零编写⼀个 C 语⾔编译器——⽤ Rust 实现,整整 10 万⾏代码。这个编译器能编译 Linux 6.9 内核(跨x86、ARM、RISC-V 三个架构)、能编译 QEMU、FFmpeg、SQLite、PostgreSQL、Redis,在 GCC 测试套件上达到 99% 的通过率。全程没有⼈类写⼀⾏代码,花费约 2 万美元 API 费⽤。
这件事的意义不在于"AI 能写编译器"——⽽在于16 个 Agent 并⾏协作写出了 10 万⾏⾼质量代码。这是 Agent 能⼒从"辅助⼯具"跨⼊"独⽴⽣产⼒"的标志性时刻。
更夸张的是,Anthropic ⽤ Claude Code 的 vibe coding(氛围编程——⽤⾃然语⾔描述需求,AI全程编写代码)模式,在⼀周半时间内设计并实现了 Cowork 这个全新产品的全部代码。对,你没看错——⼀个完整的商业产品,代码全部由 AI 编写,⼈类零⾏⼿写代码。
Claude Cowork:从开发者到知识⼯作者
2026 年 1 ⽉底,Anthropic 发布了 Claude Cowork 的研究预览版。如果说 Claude Code ⾯向的是开发者,Cowork 则把智能体的能⼒推向了更⼴泛的知识⼯作者——项⽬管理、数据分析、⽂档撰写、邮件处理,那些占据我们每天⼤量时间但并⾮"写代码"的⼯作。
2026 年 4 ⽉ 1 ⽇,Bloomberg 报道了 Anthropic ⾼管的判断:Cowork 的市场空间将⽐ ClaudeCode 更⼤。这个判断的逻辑很直接——全世界的开发者可能只有⼏千万,但知识⼯作者有数亿。智能体从代码世界⾛向⽇常⼯作,这是⼀个量级的跃迁。
OpenClaw:开源引爆通⽤智能体
但真正让智能体"飞⼊寻常百姓家"的,不是⼤⼚的商业产品,⽽是⼀个开源项⽬——OpenClaw。

OpenClaw 的故事颇具传奇⾊彩。它最早是奥地利开发者 Peter Steinberger(PSPDFKit 创始⼈,公司以约 8 亿美元出售)的个⼈项⽬。2025 年 11 ⽉开源后迅速⾛红,到 2026 年 1 ⽉底已经⽕遍全球开发者社区。Steinberger 随后加⼊ OpenAI,并将项⽬转交给⼀个独⽴的 501(c)(3) 基⾦会运营。
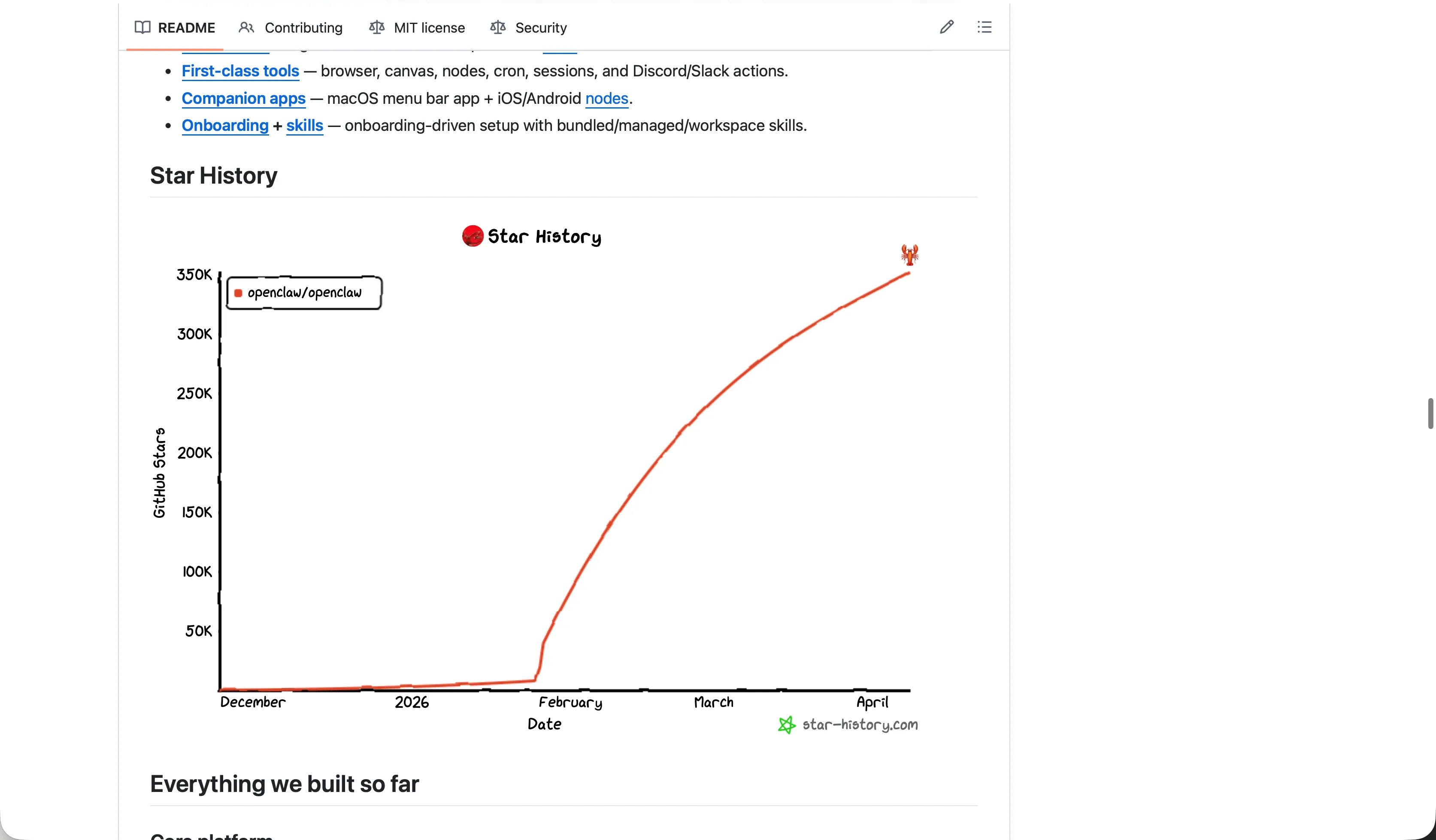
数据说明⼀切:OpenClaw 在 GitHub 上拥有 346K+ Stars,超越 React 成为 GitHub 历史上Stars 最多的软件项⽬。React 花了⼗年多才积累到约 24.3 万 Stars,OpenClaw 在 60 天内就突破了25 万。它⽀持 20+ 消息渠道(WhatsApp、Telegram、Slack、飞书、微信等),让任何⼈——不只是开发者——都能拥有⼀个随时在线的个⼈ AI 助⼿。
这是⼀个标志性的时刻:智能体不再是开发者的专属⼯具,⽽是每个⼈的⽇常助⼿。 Claude Code和 Cowork 证明了 Agent 的能⼒天花板,OpenClaw 则证明了 Agent 的普及速度。两件事叠加在⼀起,我们正在经历的,是智能体的奇点时刻。
¶ 1.2 简单上⼿,难以驾驭
通⽤智能体的⼤普及看起来⼀⽚光明——安装简单,上⼿即⽤,让 AI 帮你处理⽇常琐事。但⽤过⼀段时间之后,⼏乎每个认真使⽤智能体的⼈都会撞上同⼀堵墙:"上⼿"很容易,"驾驭"才是真正的挑战。
复合失败:成功率的数学陷阱
让我们做⼀道简单的数学题。假设 Agent 执⾏每⼀步操作的成功率是 95%——这已经相当⾼了。但如果⼀个任务需要 20 步才能完成呢?
端到端成功率 = 0.95^20 = 0.358 = 35.8%
每⼀步都"很靠谱",但串起来只有三分之⼀的概率能⾛完全程。这不是某个模型的问题,这是概率论的铁律。⽽现实中的复杂任务——部署⼀个服务、配置⼀套监控、迁移⼀个数据库——动辄就是 20步以上。
上下⽂溢出:Agent 会"忘事"
即使单步都没出错,Agent 还有另⼀个结构性弱点:它会在长任务中"忘记"早期⽬标。当对话进⾏到第 50 轮,上下⽂窗⼜被中间产物、⼯具调⽤结果、错误⽇志填满时,最初设定的任务⽬标和约束条件早已被"挤"到了注意⼒的边缘。Agent 不是"不想记住",⽽是上下⽂管理机制没有帮它区分"什么重要、什么可以丢弃"。
质量退化:没有⼈类审美厌恶的后果
还有⼀种更隐蔽的失败模式:质量的⽆声滑坡。让 Agent 持续维护⼀个项⽬,你会发现代码规范在悄悄退化——变量命名开始随意,死代码悄悄堆积,注释从详细变成潦草。为什么?因为 Agent 缺少⼈类与⽣俱来的两个质量守护机制:对丑陋代码的"审美厌恶",以及对同事评审的"社会问责"。没有这两层压⼒,质量在没有任何显式错误的情况下持续下滑。
问题不在模型
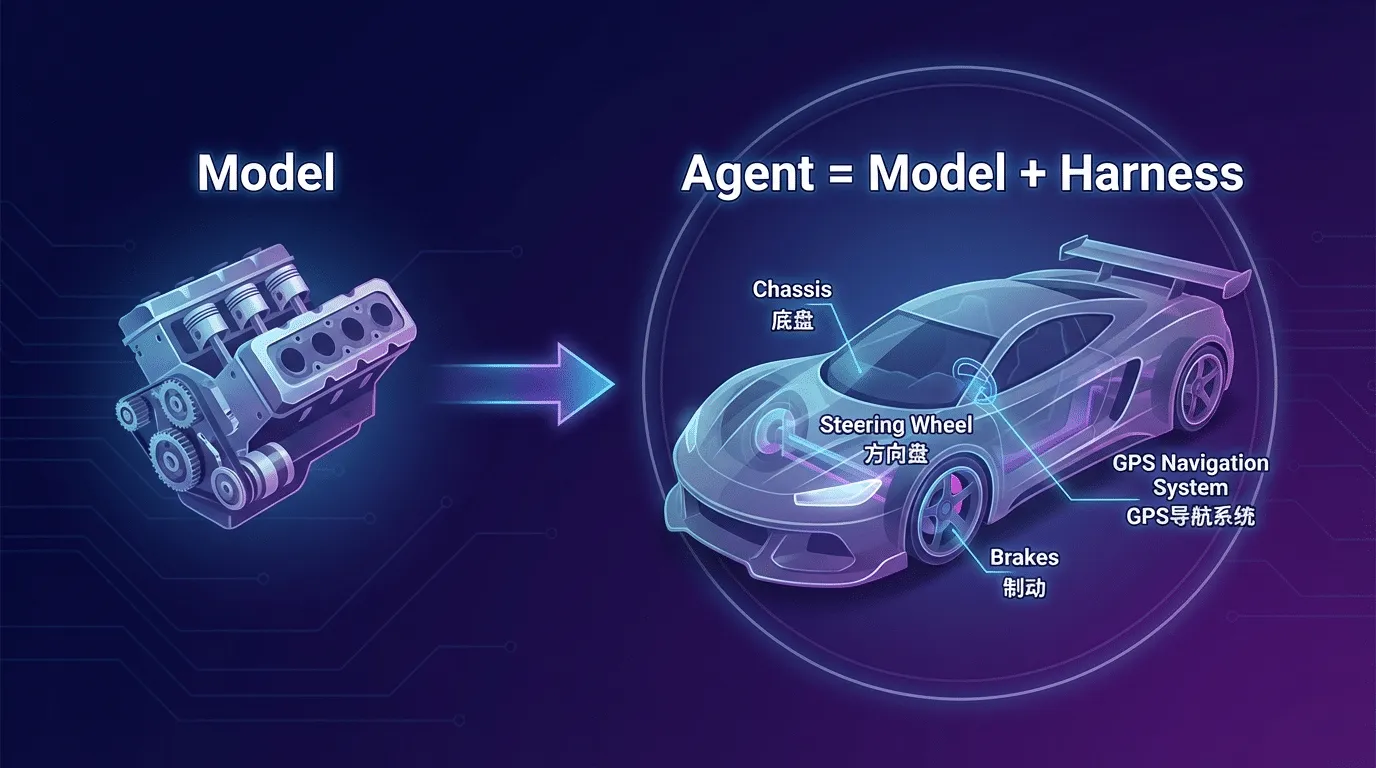
以上三个问题的共同特征是什么?它们都不是"模型不够聪明"导致的。 GPT-5.4 的推理能⼒⾜够强,Claude Opus 4.6 的上下⽂窗⼜⾜够⼤。问题不在模型本⾝——问题在模型之外的⼀切:⼯具如何编排、上下⽂如何管理、错误如何恢复、质量如何验证、记忆如何持久化。
模型是发动机,但光有发动机跑不了。你还需要底盘、刹车、⽅向盘和导航系统。
¶ 1.3 Harness Engineering 应运⽽⽣
2026 年 2 ⽉ 5 ⽇,⼀篇博⽂给这个问题起了⼀个精准的名字。

Mitchell Hashimoto——HashiCorp 联合创始⼈、Terraform 的作者——在他的博⽂ "My AI Adoption Journey" 中,提出了⼀个影响深远的公式:
Agent = Model + Harness
"Harness"直译是"缰绳"。Hashimoto 的核⼼观点朴素但深刻:不是让 AI 更聪明,⽽是系统性地改进模型之外的⼀切——⼯具编排、上下⽂管理、错误恢复、验证闭环、安全防护。这些模型周围的基础设施,统称为 Harness(驾驭层)。
他的实践⽅法论更是直击要害:
"Every time the agent makes a mistake, take the time to engineer a solution so it never makes that mistake again."
"每当 Agent 犯错,就花时间⼯程化⼀个⽅案,让它不再犯同样的错。"
这不是什么⾼深的理论——就是把软件⼯程⾥"发现 Bug 就写测试"的思路,迁移到了 Agent 的驾驭层。但正是因为朴素,它才具有普适性。
⾏业共识:不是⼀家之⾔
Hashimoto 命名后仅 6 天,2 ⽉ 11 ⽇,OpenAI 发表了⼀篇⼯程博客 "Harness engineering:leveraging Codex in an agent-first world",分享了他们的实践:⼀个⼩团队在五个⽉内,⽤ Codex Agent 交付了⼀个包含约 100 万⾏代码的内部产品——没有⼿动编写⼀⾏源代码。他们的核⼼发现和Hashimoto 如出⼀辙:当代码不再由⼈类编写时,⼯程师的⼯作就变成了"设计环境、明确意图、构建反馈循环"。

随后,Anthropic 在 3 ⽉ 24 ⽇的⼯程博客中发表了 "Harness design for long-running application development",分享了他们从多 Agent 到单 Agent 的 Harness 架构演进经验。Martin Fowler 站点也在 2 ⽉ 17 ⽇发布了备忘录、4 ⽉ 2 ⽇发表了完整的 Harness ngineering 分析⽂章,将其拆解为上下⽂⼯程、架构约束和垃圾回收三个维度。

当 HashiCorp 创始⼈、OpenAI、Anthropic、Martin Fowler 在两个⽉内先后就同⼀个概念发声时,这已经不是⼀家之⾔——这是⾏业共识。2026 年智能体领域最重要的认知转变,就是从"让模型更聪明"转向"让模型周围的⼀切更⼯程化"。
¶ 1.4 从⽅法论到落地:百花齐放
Harness Engineering 给了我们⼀个思考框架,但光有⽅法论还不够——如何落地,才是当前智能体前沿⼯程师们热议的核⼼问题。2026 年第⼀季度,⼀批项⽬⼏乎同时涌现,各⾃从不同⾓度尝试将Harness 思路变成可运⾏的代码。
Gstack:⽤ SKILL.md 模拟⼀⽀⼯程团队
2026 年 3 ⽉ 12 ⽇,Y Combinator CEO Garry Tan 在 GitHub 上开源了他的 Claude Code 配置——Gstack。核⼼思路是⽤⼀组 SKILL.md ⽂件定义不同⾓⾊(CEO、设计师、⼯程经理、QA、安全官、发布⼯程师),让单个 Claude Code 实例在不同⾓⾊间切换,模拟⼀整⽀⼯程团队的协作。Tan 本⼈⽤这套配置,在运营 YC 的同时,每天兼职写出 1 万到 2 万⾏⽣产代码。48 ⼩时内 GitHub Stars 破万。
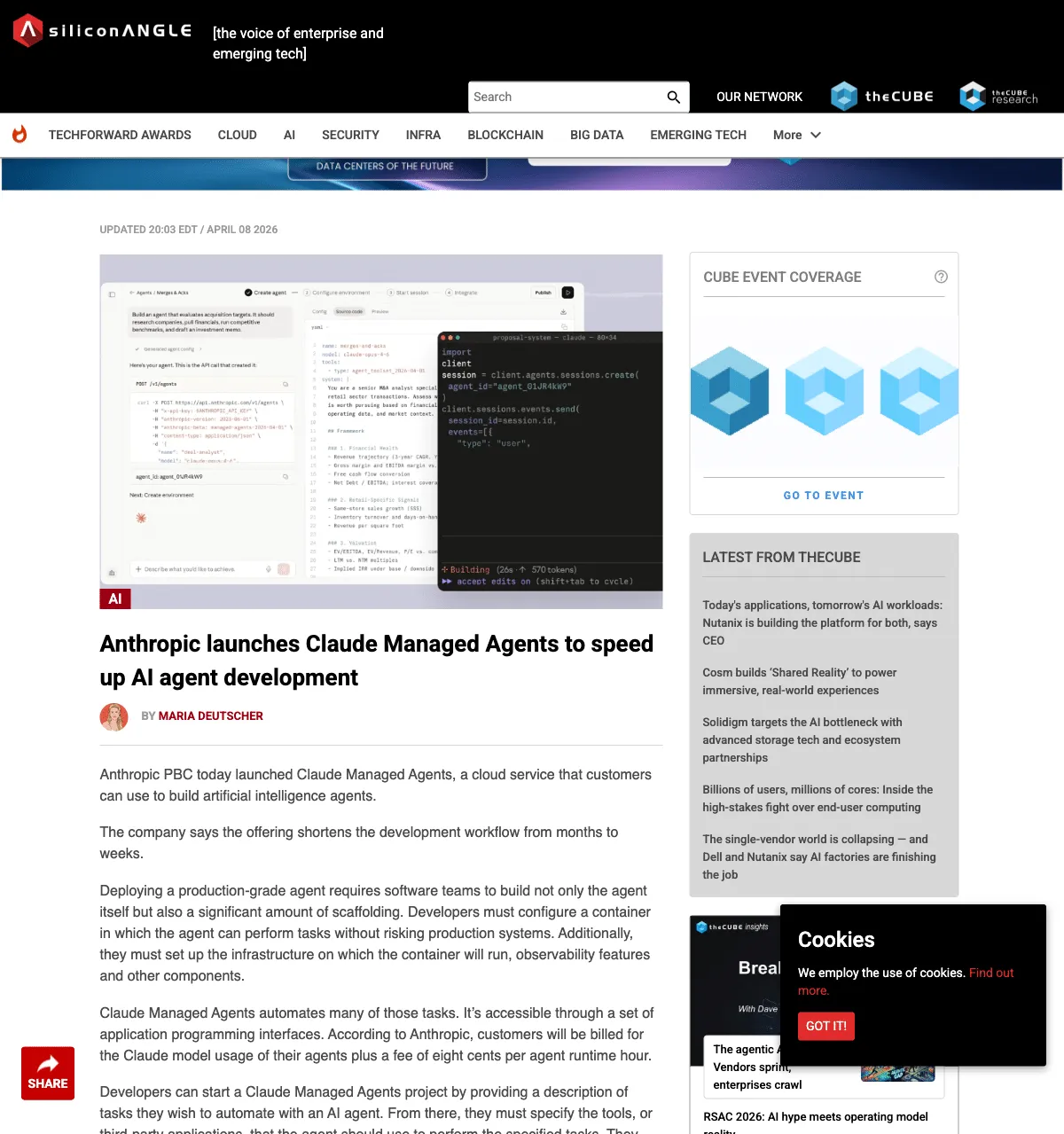
Claude Managed Agents:托管式 Agent 基础设施
2026 年 4 ⽉ 8 ⽇——就在昨天——Anthropic 推出了 Claude Managed Agents 平台的公开测试版。这是⼀套云托管的 Agent 基础设施 API,开发者⽆需⾃⼰搭建沙箱环境、状态管理和错误恢复机制,Anthropic 替你搞定这些"脏活累活"。定价是模型⽤量费⽤加上每⼩时 0.08 美元的 Agent 运⾏时费⽤。Notion、Rakuten(乐天)、Asana 是⾸批企业⽤户——Notion ⽤它让⼯程师直接在⼯作区内通过⾃定义 Agent 编写代码和⽣成演⽰⽂稿,Rakuten 在⼀周内为产品、销售、市场、财务、HR 五个部门部署了专属 Agent。
AutoHarness:让模型⾃⼰写约束规则
Google DeepMind 的研究团队提出了⼀个有趣的思路:既然 Harness 的核⼼是"约束",那能不能让 AI ⾃动⽣成这些约束?AutoHarness ⽤ Gemini-2.5-Flash 从⼯具的 schema(接⼜定义)出发,通过 Thompson 采样和树搜索,⾃动合成运⾏时约束代码。在 145 个 TextArena 游戏的测试中,它消除了所有⾮法操作,并且让 Gemini-2.5-Flash(⼩模型)的表现超过了更⼤的 Gemini-2.5-Pro。这篇论⽂已提交⾄ ICLR 2026 Recursive Self-Improvement Workshop。
Letta:OS 级记忆管理架构
Letta(前⾝是 MemGPT)将操作系统的内存管理思路搬到了 Agent 领域,设计了三层记忆架构:
- Core Memory(核⼼记忆,类⽐ RAM,始终在上下⽂中)
- Archival Memory(归档记忆,类⽐磁盘,存在向量数据库中可检索)
- Recall Memory(回溯记忆,完整对话历史的索引)
最关键的设计决策是:Agent 不是被动地接收上下⽂注⼊,⽽是主动调⽤函数在三层记忆之间搬运数据——它⾃⼰决定什么该记、什么该忘、什么该翻出来。
mem0:跨会话记忆的即插即⽤⽅案
mem0 则选了⼀条更"轻量化"的路。它提供⽤户级、会话级、Agent 级三个维度的记忆作⽤域,底层融合向量搜索、图关系和键值存储三种引擎。2026 年,mem0 成为 AWS Agent SDK(Strands)的独家记忆供应商,拿到了 2450 万美元融资和 48K GitHub Stars。对于想快速给现有 Agent 加上"跨会话记忆"能⼒的团队来说,mem0 可能是最省事的选择。
OpenClaw 最新更新:上下⽂管理全⾯开放
OpenClaw ⾃⾝也在 Harness ⽅向上持续演进。2026 年 3 ⽉ 7 ⽇发布的 v2026.3.7 版本引⼊了ContextEngine 插件槽位,开放了完整的⽣命周期钩⼦:bootstrap (初始化)、ingest (注⼊)、assemble (组装)、compact (压缩)、afterTurn (回合结束后处理),甚⾄包括prepareSubagentSpawn (⼦ Agent ⽣成前)和 onSubagentEnded (⼦ Agent 结束后)。开发者现在可以完全⾃定义上下⽂处理逻辑,⽽不需要修改 OpenClaw 的核⼼代码。
纵观这些项⽬,它们聚焦的领域各不相同:Gstack 做⾓⾊编排,Managed Agents 做基础设施托管,AutoHarness 做约束⾃动⽣成,Letta 和 mem0 做记忆管理,OpenClaw 做上下⽂引擎开放。每⼀个都是 Harness Engineering 在某个维度上的深⼊探索。
但有没有⼀个项⽬,试图把所有这些维度都做了?
¶ 1.5 集⼤成者登场:Hermes Agent
Hermes Agent 来⾃ NousResearch——⼀个在开源⼤模型微调领域深耕多年的 AI 研究团队。如果你关注 HuggingFace 的开源模型排⾏榜,你⼤概率见过 Hermes 这个名字:Nous-Hermes 系列微调模型曾在 ARC、HellaSwag、OpenBookQA 等多个基准上拿到过第⼀,最新的 Hermes 4 系列在RefusalBench 上超越了所有主流闭源和开源模型。这不是⼀个从天⽽降的团队——他们对"如何让模型表现更好"这件事,有着长期的⼯程积累。
核⼼开发者 teknium 是 NousResearch 的联合创始⼈,在 v0.8.0 这⼀个版本中就贡献了 179 个PR(Pull Request),占全部 209 个 PR 的 86%。这种深度投⼊带来了极⾼的开发节奏:
| 版本 | 发布日期 | 代号 | 核心特性 |
|---|---|---|---|
| v0.1.0 | 2026-02-25 | 首次发布 | 基础架构 |
| v0.2.0 | 2026-03-12 | — | 多平台网关、MCP 客户端、70+ 技能 |
| v0.3.0 | 2026-03-17 | 流式与插件 | 实时 token 流式输出、插件架构 |
| v0.4.0 | 2026-03-23 | — | OpenAI 兼容 API、安全加固 |
| v0.5.0 | 2026-03-28 | — | 157 PRs 全面迭代 |
| v0.6.0 | 2026-03-30 | — | MCP Server 模式 |
| v0.7.0 | 2026-04-03 | 韧性版 | 可插拔记忆、凭证池轮换 |
| v0.8.0 | 2026-04-08 | 智能版 | 后台任务通知、模型热切换、MCP OAuth 2.1 |
从 Hashimoto 命名 Harness Engineering(2 ⽉ 5 ⽇),到 Hermes Agent ⾸次发布(2 ⽉ 25⽇),仅隔 20 天。从⾸版到 v0.8.0(4 ⽉ 8 ⽇),42 天迭代了 8 个⼤版本。40K+ GitHub Stars,MIT开源协议。
为什么说它是"集⼤成者"
回头看上⼀节那些项⽬,每个都在 Harness 的某个维度上做出了深⼊探索。⽽ Hermes Agent 的野⼼是:不是做某⼀个⽅⾯,⽽是把 Harness 的所有维度都做了。
- ⼯具编排:47 个内置⼯具,按功能分成 20 个 Toolset(终端执⾏、浏览器操控、⽹页搜索、⽂件管理、视觉理解、语⾳交互、定时调度......),开箱即⽤
- 消息⽹关:14+ 消息平台内建⽹关——Telegram、Discord、Slack、WhatsApp、Signal、Email、Home Assistant、DingTalk(钉钉)、Feishu(飞书)、WeCom(企业微信)......⼀个Agent 同时活跃在所有平台
- 记忆系统:四层持久记忆架构(MEMORY.md + USER.md + SQLite FTS5 全⽂检索 + 8 种外部Provider 可插拔),每次对话都在积累经验
- 技能⾃⽣成:成功完成的复杂任务⾃动提炼为可复⽤技能,下次直接调⽤
- ⾃我进化:集成 DSPy(Stanford 提⽰词⾃动优化框架)+ GEPA(反思式提⽰词进化,Reflective Prompt Evolution),⾃动分析失败原因、⽣成改进变体、评估后提交最优⽅案。GEPA 是 ICLR 2026 的 Oral Paper,跨 6 个任务平均超越 GRPO(强化学习⽅法)6%,最⾼超越 20%,⽽所需的 rollout(推演)次数少 35 倍
- 国产模型原⽣⽀持:DeepSeek、Kimi(Moonshot)、MiniMax、智谱 GLM 通过直连 Provider 或 OpenRouter 接⼊,不需要翻墙
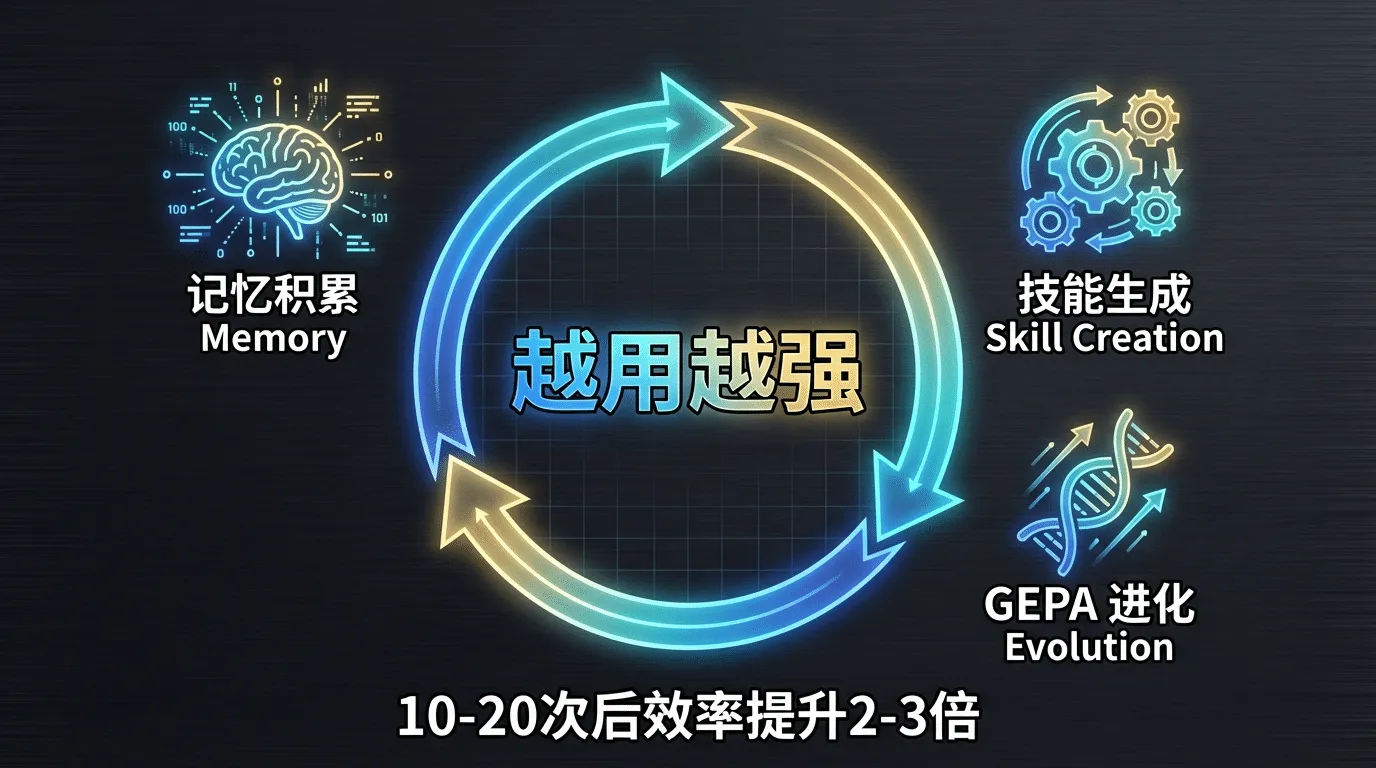
- 国内通信平台内建:飞书、钉钉、企业微信⽹关开箱即⽤,不需要⾃⼰写⼀⾏对接代码它的⼜号是 "The agent that grows with you"——越⽤越强的 Agent。这不是营销话术,⽽是由四层记忆 + 技能⾃⽣成 + GEPA 进化优化三套独⽴但协作的⼯程系统⽀撑的真实能⼒。官⽅数据显⽰,同类任务执⾏ 10-20 次后,Agent 的效率可以提升 2-3 倍。

Hermes Agent vs OpenClaw:同源但不同路
看到这⾥你可能会想:这两个项⽬不是差不多吗?都是开源、都接多种模型、都⽀持消息平台。但仔细看它们的"⾻骼",会发现根本是两种物种。OpenClaw 的⼜号是 "Your own personal AI assistant"——它的核⼼价值是做⼀个更好的聊天机器⼈:接⼊更多平台、⽀持更多模型、让你在任何设备上都能⽅便地和 AI 对话。它的 Dreaming 记忆系统、Task Flow 编排,本质上都是在让"对话体验"更顺滑。⽽ Hermes Agent 的⼜号是 "The agent that grows with you"——它的野⼼不是当聊天助⼿,⽽是做⼀个可以⾃我成长的 Agent 运⾏时。它有四层记忆系统(MEMORY.md + USER.md + SQLite FTS5 + 8 种外部 Provider),让 Agent 真正"记住"你的⼀切;有技能⾃⽣成机制,成功解决复杂任务后⾃动提炼为可复⽤的 Skill ⽂件;更有 GEPA 进化优化(ICLR 2026 Oral Paper),⽤反思式进化搜索⾃动改进⾃⼰的 Skill 和提⽰词。这套组合拳在开源 Agent 中独⼀⽆⼆。技术路线上,OpenClaw 更偏传统的 prompt-response 增强模式,通过插件和平台适配扩展能⼒边界;Hermes Agent 则是Harness Engineering 范式的实践者,强调 "Agent = Model + Harness"——模型之外的⼯具编排、状态管理、错误恢复、验证循环才是核⼼竞争⼒。⼀句话总结:OpenClaw 是"更好的聊天机器⼈",Hermes Agent 是"可以⾃我成长的 Agent 系统"。
¶ 2 Harness Engineering 底层原理
上⼀节我们认识了 Hermes Agent 这个"新物种"——⼀个越⽤越强的通⽤ Agent 运⾏时。但如果只知道它"很厉害",不理解它为什么厉害,我们就只是在盲⽬使⽤⼯具,⽽不是真正掌握它。
Hermes Agent 之所以能做到越⽤越强,背后有⼀套正在改变整个 Agent 领域的⼯程范式——Harness Engineering。这个概念在 2026 年 2 ⽉由 HashiCorp 联合创始⼈ Mitchell Hashimoto 正式命名,随后两个⽉内 OpenAI、Anthropic、Martin Fowler 站点先后发表深度分析,LangChain ⽤它在基准测试中实现了不换模型得分跳涨 13.7 个百分点的壮举。
这⼀节,我们要把 Harness Engineering 从概念层拆解到机制层——不仅理解它是什么,更要理解它为什么有效、怎么运作。这是整节课最"硬核"的部分,也是你理解 Hermes Agent 设计哲学的钥匙。
¶ 2.1 Agent = Model + Harness:⼀个公式改变认知
2026 年 2 ⽉ 5 ⽇,Mitchell Hashimoto——HashiCorp 联合创始⼈、Terraform 和 Vagrant 的创造者——发表了⼀篇题为 My AI Adoption Journey 的博⽂。这篇⽂章记录了他从 AI 怀疑论者到深度使⽤者的六个阶段,其中第五阶段,他⽤⼀个简洁的短语命名了⼀种全新的⼯程实践:Harness Engineering。

他给出的原始定义极其精炼:
"Anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again."
——每当你发现 Agent 犯了⼀个错误,就花时间⼯程化⼀个⽅案,确保它再也不会犯同样的错。
这句话看似简单,实则包含了⼀个深刻的认知转变:当 Agent 出错时,问题不在 Agent 本⾝,⽽在于它运⾏的环境——Harness——没有设计好。
什么是 Harness
Harness 直译是"挽具"——套在马⾝上⽤来引导⽅向、控制⼒量的装置。在 Agent 语境中,Harness 指的是模型之外的⼀切基础设施:
| Harness 组件 | 做什么 | 类比 |
|---|---|---|
| 工具编排(Tool Orchestration) | 决定 Agent 能调用哪些工具、以什么顺序 | 工匠的工具箱 |
| 上下文工程(Context Engineering) | 在正确的时间给 Agent 正确的信息 | 教练赛前给的战术板 |
| 状态管理(State Management) | 跨步骤、跨会话保持信息连续性 | 项目经理的会议纪要 |
| 错误恢复(Error Recovery) | 检测失败并自动重试或降级 | 飞机的备份系统 |
| 验证循环(Verification Loops) | 执行后检查结果是否符合预期 | 代码审查流程 |
| 安全防护(Safety Guardrails) | 限制 Agent 的行动边界 | 赛道的护栏 |
| 生命周期管理(Lifecycle Management) | 管理 Agent 的启动、运行、暂停、恢复 | 操作系统的进程调度 |
⼀个公式概括:
Agent = Model + Harness
Model 是⼤语⾔模型本⾝的能⼒——推理、⽣成、理解。Harness 是包裹在 Model 外⾯的整套⼯程系统——它决定了 Model 的能⼒能不能被稳定、可靠、可扩展地释放出来。
为什么这个公式重要
如果你觉得这只是⼀个定义问题,看⼀组数据。
2026 年 3 ⽉,LangChain 团队在 Terminal Bench 2.0 基准测试中做了⼀个实验:他们完全没有更换底层模型(始终使⽤ GPT-5.2-Codex),仅仅改进了 Harness——加⼊了四层中间件(后⾯会详细讲),结果得分从 52.8 跳到 66.5,提升了 13.7 个百分点,排名从 Top 30 之外⼀跃进⼊ Top 5。

这意味着什么?同⼀个模型,同⼀个任务,不改⼀⾏模型代码,仅仅优化 Agent 运⾏的"环境",性能就提升了 26%。相⽐之下,换⼀个更⼤的模型带来的提升往往不到 10%,⽽且成本翻倍。
深⼊理解:这就是为什么 Harness Engineering 正在成为 2026 年 Agent 领域最重要的⼯程范式——改 Harness 的投⼊产出⽐远超换更⼤的模型。对于开发者来说,提升 Agent 能⼒最有效的⽅式不是等下⼀代模型,⽽是⼯程化你现在的 Harness。
¶ 2.2 三条路殊途同归:Harness Engineering 的诞⽣故事
⼀个概念真正重要的信号不是有⼈提出了它,⽽是多个独⽴的团队⼏乎同时从不同⾓度发现了同⼀件事。Harness Engineering 的诞⽣恰恰符合这个模式——两个⽉内,⾄少六篇重量级⽂章从不同⽅向汇聚到同⼀个核⼼观点。
时间线
| 日期 | 谁 | 做了什么 | 视角 |
|---|---|---|---|
| 2026-02-05 | Mitchell Hashimoto | My AI Adoption Journey | 个人实践者——从 AI 怀疑论者到重度用户的六阶段旅程,第五阶段命名 Harness Engineering |
| 2026-02-11 | OpenAI(Ryan Lopopolo) | Harness Engineering: Leveraging Codex | 规模化生产——七名工程师用 Codex 生成 100 万行代码、1500 个 PR,零行手写代码 |
| 2026-02-17 | Birgitta Bockeler | Harness Engineering 初步备忘录(Martin Fowler 站点) | 软件工程理论——首次将 Harness 纳入控制论框架分析 |
| 2026-02-26 | NousResearch | 发布 Hermes Agent | 产品实践——把 Harness 理念做成开箱即用的开源产品 |
| 2026-03-24 | Anthropic(Prithvi Rajasekaran) | Harness Design for Long-running Apps | 深度分析——三 Agent 架构 + Generator-Evaluator 循环 |
| 2026-04-02 | Birgitta Bockeler | 完整版文章(Martin Fowler 站点) | 系统分类——Guides vs Sensors 框架,Harness 组件全分类 |

三条独⽴路径
仔细看这条时间线,你会发现三条独⽴的路径最终汇聚到了同⼀个认知:
- 路径⼀:个⼈实践(Hashimoto)。⼀个资深⼯程师在⽇常使⽤ Agent 的过程中,通过反复试错总结出了⼀种⽅法论:别怪 Agent 蠢,去优化它的运⾏环境。他给了两个具体做法——⼀是⽤AGENTS.md ⽂件记录 Agent 的常见错误和应对⽅案;⼆是编写脚本⼯具(截图、测试过滤等)作为Agent 的"外挂"。
- 路径⼆:规模化⽣产(OpenAI)。OpenAI 内部团队做了⼀个极端实验:⽤五个⽉时间,让Codex Agent ⽣成了 100 万⾏代码和 1500 个 PR,期间没有⼀⾏代码是⼈⼿写的。他们发现⼯程师的⾓⾊完全改变了——从"写代码的⼈"变成了"让 Agent 能够有效写代码的⼈"。他们称之为 Harness Engineer。
- 路径三:产品设计(NousResearch)。Hermes Agent 的发布时间(2026-02-26)恰好在Hashimoto 和 OpenAI 之后三周。NousResearch 没有发论⽂、没有写博客,⽽是直接把 Harness 思想做成了产品——四层记忆系统是上下⽂⼯程的产品化,GEPA 进化是反馈循环的产品化,47 个内置⼯具是⼯具编排的产品化。
当三个完全独⽴的团队从不同⾓度得出相同结论时,这个结论⼤概率不是偶然的。
Anthropic 的精辟概括
2026 年 3 ⽉ 24 ⽇,Anthropic ⼯程师 Prithvi Rajasekaran 发表了⼀篇深度分析,其中有⼀句话把 Harness 的本质说透了:
"Every component in a harness encodes an assumption about what the model can't do on its own."
——Harness 中的每⼀个组件,都编码了⼀个关于"模型⾃⾝做不到什么"的假设。

这句话有两层深意。
第⼀层很直⽩:Harness 是⽤来弥补模型缺陷的。⽐如模型会忘记上下⽂——所以我们加记忆系统;模型会犯低级错误——所以我们加 Linter 检查;模型⽆法⾃评——所以我们加独⽴评估 Agent。
第⼆层更微妙:这些假设会过期。当模型能⼒提升后,原本必要的 Harness 组件可能变得多余。Rajasekaran 特别指出,当 Opus 4.6 发布后,他们直接移除了之前为 Sonnet 4.5 设计的 Sprint 分解机制——因为更强的模型不再需要这种"⼿把⼿拆解任务"的辅助了。所以优秀的 Harness 不是⼀劳永逸的架构,⽽是需要随模型演进持续调整的活系统。
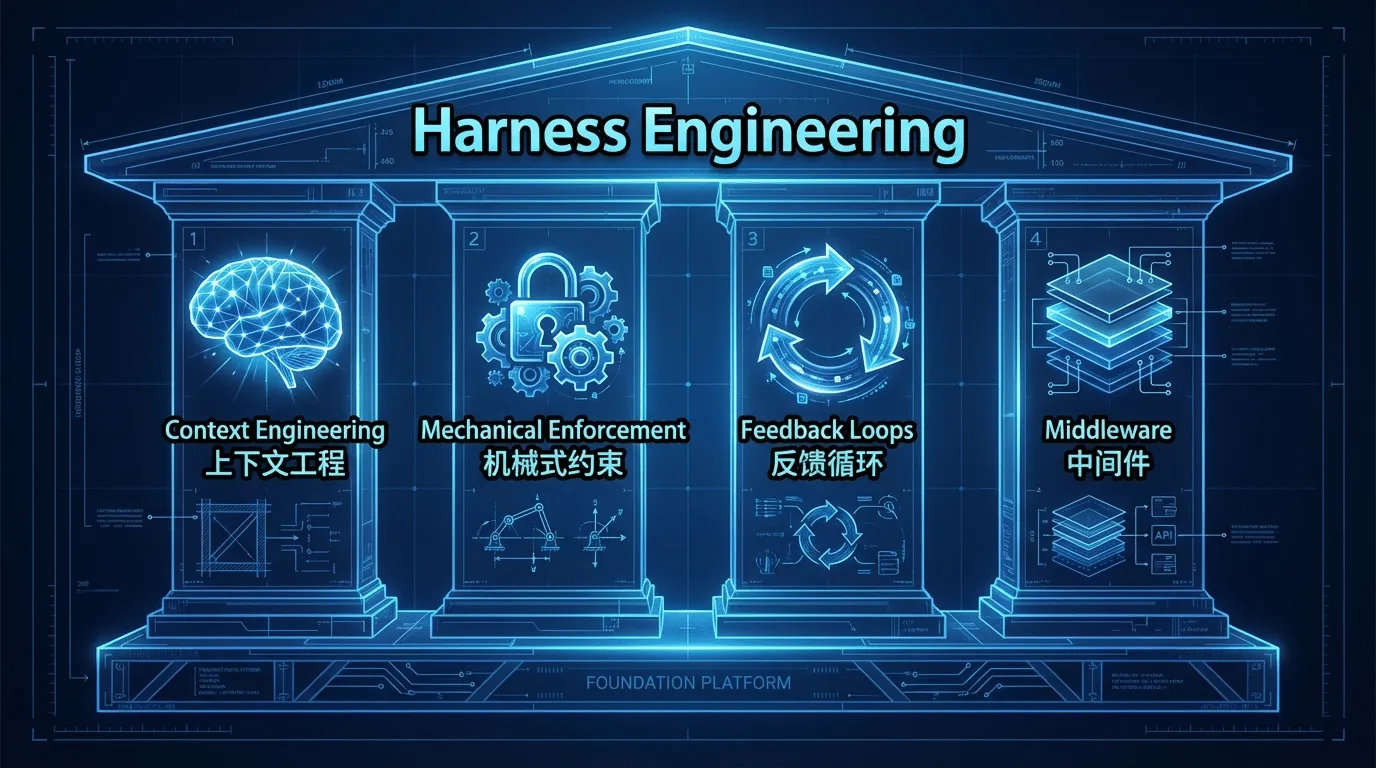
¶ 2.3 Harness 的核⼼机制
理解了"Harness 是什么"和"为什么重要"之后,我们进⼊最关键的部分:Harness 到底是怎么⼯作的? 它有哪些核⼼机制?这些机制如何协作?
综合 Hashimoto、OpenAI、Anthropic、LangChain 和 Bockeler 的⽂章,我们可以把 Harness的核⼼机制归纳为四个层⾯。
¶ 2.3.1 Context Engineering:精准上下⽂管理
如果要选⼀个 Harness 中最重要的单⼀机制,⼤部分从业者会选 Context Engineering(上下⽂⼯程)。原因很简单:从 Agent 的视⾓看,不在上下⽂窗⼜⾥的信息等于不存在。 你的架构⽂档写得再好,如果 Agent 看不到,就跟没写⼀样。
Context Engineering 解决的核⼼问题是:在正确的时间,把正确的信息,以正确的格式,放进Agent 的上下⽂窗口。
层级加载策略
最朴素的做法是"把所有信息⼀股脑塞给 Agent"——但上下⽂窗⼜有⼤⼩限制,信息太多反⽽会导致注意⼒稀释,Agent 找不到关键信息。成熟的 Harness 采⽤层级加载策略:Agent 只在当前阶段接触到当前阶段需要的信息。
以 OpenClaw(Claude Code)的三层结构为例,这是⽬前最成熟的 Context Engineering 实践之⼀:
| 层级 | 文件 | 加载时机 | 内容 |
|---|---|---|---|
| 第一层:全局上下文 | CLAUDE.md | 每次会话自动加载 | 项目级别的规则、约定、禁忌 |
| 第二层:技能上下文 | Skill 指令文件 | 执行特定任务时按需加载 | 该任务的具体操作步骤和约束 |
| 第三层:参考材料 | 参考文件/搜索结果 | 需要时动态获取 | 具体的 API 文档、示例代码、外部知识 |
LangChain 的做法更加⾃动化。他们实现了⼀个叫 LocalContextMiddleware 的中间件:Agent启动时,这个中间件会⾃动扫描当前⼯作⽬录和上下级⽬录、检测可⽤的⼯具链(Python 版本、包管理器等),把这些环境信息注⼊ Agent 的上下⽂。LangChain 发现,Agent 之前浪费了⼤量步骤去"搞清楚⾃⼰在哪⾥"——这个中间件直接省掉了这些⽆效探索。
Hermes Agent 中的上下⽂⼯程
Hermes Agent 的四层记忆系统本质上就是⼀套 Context Engineering ⽅案:
- MEMORY.md(短期记忆):当前会话的偏好和上下⽂
- USER.md(⽤户画像):跨会话的⽤户偏好积累
- SQLite FTS5(长期记忆):全⽂检索历史对话和经验
- 外部 Provider(扩展记忆):对接 8 种以上外部知识源
每次对话开始时,Hermes Agent 不是把所有记忆都倒进上下⽂,⽽是根据当前任务的语义相关性检索最相关的记忆⽚段,精准注⼊。这就是层级加载在产品中的具体实现。
重要提醒:Context Engineering 有⼀个反直觉的要点——信息太多和信息太少⼀样有害。
OpenAI 在 Harness Engineering ⽂章中的⼀条核⼼教训是:"Give Codex a map, not a 1,000-page instruction manual."——给 Agent ⼀张地图,⽽不是⼀本千页⼿册。过度加载上下⽂不仅浪费 token,还会稀释 Agent 的注意⼒,导致关键信息被淹没。
¶ 2.3.2 Mechanical Enforcement:机械式约束
Context Engineering 告诉 Agent"应该做什么",但 Agent 未必会听。Mechanical Enforcement(机械式约束)的思路完全不同:不是告诉 Agent"写好代码",⽽是⽤代码机械地定义什么是"好代码",然后强制执⾏。
⼀个直觉的类⽐:Context Engineering 是给厨师⼀本菜谱,Mechanical Enforcement 是在厨房⾥只放允许使⽤的⾷材——不管厨师想做什么,他只能⽤这些材料。
常见的机械式约束⼿段
| 约束类型 | 做什么 | 举例 |
|---|---|---|
| 静态分析(Linter) | 自动检测代码风格和简单错误 | ESLint 规则、Pylint 检查 |
| 类型检查(Type Checker) | 强制类型正确性 | TypeScript 编译、mypy 检查 |
| 架构约束(Structural Test) | 强制模块边界和依赖方向 | ArchUnit 测试、层级依赖检查 |
| 格式验证(Schema Validation) | 强制输出符合预定义格式 | JSON Schema、Pydantic 模型 |
| 权限白名单(Permission) | 限制 Agent 可以访问的资源 | 文件系统白名单、API 权限控制 |
| Pre-commit Hook | 在提交前拦截不合格的修改 | Husky + lint-staged |
关键洞察在于:这些约束是确定性的、不可绕过的。 Linter 不关⼼ Agent 有多"聪明",违反规则就是报错,没有商量余地。这种确定性恰恰是 LLM 最缺乏的——LLM 是概率性的、有时会"想当然",⽽机械式约束把"想当然"拦在了门外。
约束 = ⽣产⼒
⼀个常见误解是"约束会限制 Agent 的能⼒"。实际恰恰相反。NxCode 的分析指出:"Constraining the solution space makes agents more productive, not less."(约束解空间反⽽让 Agent 更⾼效。)
原因很直观:如果⼀个编码任务有 100 种可能的实现路径,其中 80 种会触发 Linter 错误、10 种不满⾜类型约束,Agent 只需要在剩下的 10 种中选择——探索空间缩⼩了 90%,速度⾃然更快、出错率也更低。
Hermes Agent 中的机械式约束
Hermes Agent 的 Toolset 权限系统是机械式约束的典型实现。管理员可以精确控制每个 Toolset的开关——⽐如禁⽤ code_execution ⼯具集就彻底阻⽌ Agent 执⾏代码,不是"建议"不执⾏,⽽是物理上不可能执⾏。这就是机械式约束和提⽰词约束的根本区别。
¶ 2.3.3 Feedback Loops & Verification:反馈闭环与验证
Context Engineering 确保 Agent 有正确的信息,Mechanical Enforcement 确保 Agent 不犯低级错误——但谁来确保 Agent 的最终输出真的达到了预期?
答案是 Feedback Loops(反馈闭环)。这也是 Harness 中最有"系统⼯程"味道的⼀环。
为什么 Agent ⽆法⾃评
Anthropic 在三 Agent 架构实验中发现了⼀个关键问题:模型对⾃⼰⼯作的评价⼏乎总是"满意"——即使输出质量很差。这种"⾃评偏差"是 LLM 的结构性缺陷:⽣成答案的模型和评估答案的模型是同⼀个,它天然倾向于认为⾃⼰的输出是合理的。
类⽐到⼈类世界:这就是为什么论⽂需要同⾏评审、代码需要 Code Review、财务报表需要外部审计——⾃⼰检查⾃⼰的⼯作,可靠性是有上限的。
所以,成熟的 Harness ⼀定包含外部化的验证系统——验证者和被验证者不是同⼀个 Agent。
四种验证模式
| 验证模式 | 机制 | 可靠性 | 速度 |
|---|---|---|---|
| 确定性测试 | 单元测试、集成测试、E2E 测试 | 最高 | 快 |
| 静态扫描 | 安全扫描、依赖审查、许可证检查 | 高 | 快 |
| Agent 互审 | 独立 Agent 评估另一个 Agent 的输出 | 中高 | 中 |
| 人类审查 | 人工检查关键节点 | 最高 | 慢 |
Anthropic 的 Generator-Evaluator 循环
Anthropic 在这⽅⾯做了最系统的实验。他们设计了⼀个受 GAN(对抗⽣成⽹络)启发的三 Agent 架构:
- Planner(规划者):将⽤户需求分解为可执⾏的任务列表
- Generator(⽣成者):逐个执⾏任务,⽣成代码和设计
- Evaluator(评估者):独⽴测试 Generator 的输出(⽤ Playwright 在真实浏览器中测试),按照预设标准评分,提供详细的改进意见
关键设计:Evaluator 被刻意校准为怀疑论者(skeptical),⽽不是"⿎励型评审"。Rajasekaran 特别提到:"Separating the agent doing the work from the agent judging it proves to be a strong lever."——让做事的 Agent 和评判的 Agent 分离,是⼀个强⼤的杠杆。
⼀个对⽐数据来⾃ Anthropic 的实验:不使⽤ Harness 的简单"提⽰-运⾏"模式,花费 $9 产出了⼀个残破的产品;使⽤三 Agent Harness 的结构化模式,花费 $200 产出了⼀个完整可⽤的应⽤。成本增加了 22 倍,但从"不可⽤"变成了"可⽤"——这才是真正的 ROI。
Hermes Agent 中的反馈闭环
Hermes Agent 的 GEPA(反思式提⽰词进化,Reflective Prompt Evolution)系统就是⼀个产品化的反馈闭环:每次技能执⾏的结果都被记录和评估,成功的模式被保留和强化,失败的模式被淘汰和改进。这不是⼀次性的验证,⽽是持续运⾏的进化压⼒——和⽣物进化的逻辑⼀样。
¶ 2.3.4 中间件模式:把 Harness 变成可组合的管道
前⾯三个机制回答了"做什么",中间件模式回答的是"怎么组织"——当你有上下⽂管理、机械约束、反馈循环这么多组件时,如何优雅地把它们组装在⼀起?
LangChain 给出了⽬前最清晰的答案:中间件管道(Middleware Pipeline)。
LangChain 的四层中间件架构
在 Terminal Bench 2.0 的实验中,LangChain 为他们的 DeepAgents 编码 Agent 实现了四层中间件,每⼀层解决⼀类具体问题:
Agent Request
↓
┌──────────────────────────────────┐
│ LocalContextMiddleware │ ← 启动时扫描环境,注入目录结构和工具链信息
├──────────────────────────────────┤
│ LoopDetectionMiddleware │ ← 追踪每个文件的编辑次数,超过 N 次则介入
├──────────────────────────────────┤
│ ReasoningSandwichMiddleware │ ← 不同阶段分配不同推理预算
├──────────────────────────────────┤
│ PreCompletionChecklistMiddleware │ ← 退出前强制验证,防止"虎头蛇尾"
└──────────────────────────────────┘
↓
Agent Response
逐层拆解:
| 中间件 | 解决什么问题 | 怎么做 |
|---|---|---|
| LocalContextMiddleware | Agent 不知道自己在哪里、有什么工具 | 启动时自动扫描 cwd 及上下级目录,检测 Python 版本、包管理器等,注入上下文 |
| LoopDetectionMiddleware | Agent 陷入"死循环"——反复修改同一个文件 | 追踪每个文件的编辑计数,超过阈值后注入"请换个思路"的引导 |
| ReasoningSandwichMiddleware | 推理预算分配不合理——全程最高推理会超时 | 规划阶段用最高推理,实现阶段用普通推理,验证阶段再拉回最高——"三明治"策略 |
| PreCompletionChecklistMiddleware | Agent 草草收工,不检查就退出 | 在 Agent 尝试退出时拦截,强制运行验证清单,未通过则继续工作 |
这个架构的优雅之处在于可组合性:每⼀层中间件是独⽴的、可插拔的。你可以根据具体场景⾃由组合——不需要 Loop 检测?去掉那⼀层就⾏。需要加安全扫描?插⼊⼀个新的SecurityScanMiddleware 即可。核⼼ Agent 逻辑完全不需要修改。
实⽤建议:LangChain 团队对这些中间件有⼀个坦诚的认知——他们承认这些 guardrails 是"当前模型局限性的临时补丁"(temporary patches for current model limitations)。随着模型能⼒提升,某些中间件可能变得不再必要。这和 Anthropic 的"假设编码"理论⼀脉相承:Harness 中的每个组件都是⼀个关于模型缺陷的假设,假设可能会过期。
Hermes Agent 的中间件思维
虽然 Hermes Agent 没有显式地使⽤"中间件"这个术语,但它的架构体现了同样的思想。它的 20 个 Toolset 可以独⽴启⽤/禁⽤(可组合性),技能系统⽀持按需加载(层级上下⽂),GEPA 进化系统在后台持续优化(反馈循环中间件)。本质上,Hermes Agent 是把中间件模式"包装"成了⼀个开箱即⽤的产品,⽽不是让⽤户⾃⼰去组装管道。
¶ 2.4 Guides 与 Sensors:Bockeler 的分类框架
前⾯我们从"机制"的⾓度理解了 Harness 的四⼤核⼼——但还缺⼀个统⼀的分类视⾓。2026 年 4 ⽉ 2 ⽇,Thoughtworks 杰出⼯程师 Birgitta Bockeler 在 Martin Fowler 站点发表了⼀篇系统性⽂章 Harness Engineering for Coding Agent Users,提出了⼀个简洁有⼒的分类框架:Guides(引导)与Sensors(感知)。
控制论视⾓
Bockeler 的洞察来⾃控制论(Control Theory)——⼀个研究"如何让系统⾏为符合预期"的⼯程学科。控制论把控制⼿段分为两类:
- 前馈控制(Feedforward):在系统⾏动之前⼲预,预防错误发⽣
- 反馈控制(Feedback):在系统⾏动之后检测,发现并纠正错误
映射到 Harness 上:
- Guides = 前馈控制——在 Agent ⾏动之前引导它⾛正确的⽅向
- Sensors = 反馈控制——在 Agent ⾏动之后检测输出是否合格
对⽐表
| Guides(引导) | Sensors(感知) | |
|---|---|---|
| 控制时机 | 行动前(预防) | 行动后(检测+纠正) |
| 核心问题 | "Agent 怎么做才对?" | "Agent 做的对不对?" |
| 典型手段 | AGENTS.md/CLAUDE.md 规则文件 项目引导脚本 LSP 代码智能提示 参考文档和技能指令 |
Linter/Type Checker 静态分析 测试套件(单元/集成/E2E) 架构适配性测试(ArchUnit) 独立 Agent 代码审查 |
| 执行方式 | 注入上下文(确定性或推理型) | 检查输出(确定性或推理型) |
| 失败代价 | Agent 走弯路,效率降低 | 缺陷流入下游,修复成本高 |
两个⼦维度
Bockeler 进⼀步把 Guides 和 Sensors 各分为两种执⾏类型:
- Computational(确定性的):由代码执⾏,速度快(毫秒级)、结果确定——⽐如 Linter、类型检查、格式验证
- Inferential(推理型的):由 LLM 执⾏,速度慢、结果不确定,但能处理语义级问题——⽐如Agent 审查代码的架构合理性
组合起来就是⼀个 2x2 矩阵:
| Computational(确定性) | Inferential(推理型) | |
|---|---|---|
| Guides | 引导脚本、LSP 提示 | AGENTS.md 指令、技能描述 |
| Sensors | Linter、测试套件 | Agent 代码审查、语义评分 |
Hermes Agent 中的 Guides 与 Sensors
⽤ Bockeler 的框架来审视 Hermes Agent,你会发现它两者兼备:
| 类型 | Hermes Agent 中的实现 |
|---|---|
| Computational Guide | Toolset 权限配置(确定性地限制 Agent 能用的工具) |
| Inferential Guide | 四层记忆系统注入的上下文(基于语义检索的相关经验) |
| Computational Sensor | 命令执行的退出码检测(非零退出码触发错误处理) |
| Inferential Sensor | GEPA 进化评估(LLM 评判技能执行的成功与否) |
深⼊理解:Bockeler 的框架之所以有价值,不仅因为它帮助分类——更因为它帮助发现盲区。如果你的 Harness 只有 Guides 没有 Sensors,Agent 可能"看起来在正确地⼯作"但输出质量⽆⼈把关。如果只有 Sensors 没有 Guides,Agent 会反复试错才能找到正确⽅向——每次试错都有时间和 token 成本。好的 Harness 两者兼备,前馈和反馈形成闭环。
¶ 2.5 与 Prompt Engineering、Context Engineering 的关系
"Harness Engineering 和 Prompt Engineering 是什么关系?和 Context Engineering 呢?"——这是很多⼈初次接触这个概念时的第⼀个问题。
答案是⼀个清晰的三层递进关系:
| 层级 | 名称 | 时期 | 核心关注 | 一句话定义 |
|---|---|---|---|---|
| 1 | Prompt Engineering | 2022-2024 | 指令措辞 | 如何说话让 AI 给出好答案 |
| 2 | Context Engineering | 2025 | 信息管理 | 如何喂信息让 AI 有足够的决策依据 |
| 3 | Harness Engineering | 2026 | 环境设计 | 如何造环境让 AI Agent 稳定、可靠地自主工作 |
⼀个直观的类⽐:
- Prompt Engineering = 给新员⼯写⼀封邮件,告诉他"把这件事做好"
- Context Engineering = 给新员⼯⼀个完整的 onboarding 包——项⽬⽂档、代码库、历史决策记录
- Harness Engineering = 给新员⼯设计整个⼯作环境——办公系统、审批流程、代码审查制度、导师制度、绩效评估体系
这三层是包含关系,不是替代关系。Harness Engineering 包含 Context Engineering,Context Engineering 包含 Prompt Engineering——就像操作系统包含⽂件系统,⽂件系统包含单个⽂件。每⼀层增加了新的维度,但没有消灭前⼀层。你仍然需要写好 prompt,仍然需要管理好context——只是仅仅做这些已经不够了。
换⼀种说法:
- Prompt 告诉 Agent 做什么
- Context 告诉 Agent 知道什么
- Harness 告诉 Agent 在哪⾥⼯作、⽤什么⼯具、怎么被检查、犯了错怎么办
当你理解了这个关系,就能明⽩为什么 2026 年的 Agent 领域在谈论 Harness ⽽不是更好的Prompt——因为在 Agent ⾃主执⾏多步骤复杂任务的场景下,⼀条再好的 prompt 也⽆法替代⼀套完整的运⾏环境。
¶ 2.6 诚实⾯对:概念仍在早期
在结束这⼀节之前,我们需要诚实地⾯对⼀个事实:Harness Engineering 是⼀个极其年轻的概念。
从 Hashimoto ⾸次命名(2026 年 2 ⽉ 5 ⽇)到今天(2026 年 4 ⽉),满打满算只有两个⽉。这意味着:
- 第⼀,没有统⼀标准。 Hashimoto 说的 Harness Engineering、OpenAI 说的 Harness Engineering、Bockeler 说的 Harness Engineering——虽然核⼼思想⼀致,但具体定义和范围并不完全相同。Hashimoto 侧重个⼈实践层⾯(AGENTS.md + 脚本⼯具),OpenAI 侧重⽣产流程层⾯(零⼿写代码的极端实验),Bockeler 侧重系统⼯程层⾯(Guides/Sensors 分类框架),Anthropic 侧重架构设计层⾯(Generator-Evaluator 循环)。
- 第⼆,成功样本有限。 LangChain 的 Terminal Bench 2.0 实验是⽬前最有说服⼒的定量数据——但这只是⼀个基准测试,不是⽣产环境。OpenAI 的"百万⾏零⼿写"实验很震撼,但那是在 OpenAI 内部、使⽤ OpenAI ⾃家模型——不是所有团队都能复制这个条件。
- 第三,与已有概念的边界模糊。 如果你是软件⼯程⽼⼿,会发现 Harness Engineering 的很多组件——测试驱动开发、CI/CD 管道、代码审查流程——都不是新东西。Harness Engineering 的创新到底在哪⾥?是真正的范式转换,还是给已有实践贴了个新标签?这个问题⽬前没有定论。
- 第四,可能被过度炒作。 任何两个⽉内从零到成为"年度最热概念"的东西,都有被炒作的风险。已经有⼈开始⽤"Harness Engineering"来包装各种已有的⼯程实践,就像⼏年前什么都叫"DevOps"⼀样。
但是。
当 Hashimoto(HashiCorp 创始⼈)、OpenAI(全球最⼤的 AI 公司之⼀)、Anthropic(Claude的创造者)、Bockeler(Martin Fowler 团队的杰出⼯程师)在两个⽉内从完全不同的⾓度阐述了同⼀个核⼼理念——"Agent 的可靠性取决于模型之外的⼯程系统"——这件事本⾝就值得认真对待。
⽆论这个概念最终叫什么名字、边界在哪⾥,它指向的底层洞察是真实的:在 Agent 时代,最重要的⼯程能⼒不是训练更好的模型,⽽是设计更好的运⾏环境。Hermes Agent 是这个洞察的⼀个产品化实践——当我们后⾯动⼿安装和使⽤它时,你会看到这些"底层原理"如何变成真实的产品功能。
¶ 参考来源
本节内容综合⾃以下⼀⼿来源(按时间排序):
- Mitchell Hashimoto, My AI Adoption Journey, 2026-02-05
- Ryan Lopopolo / OpenAI, Harness Engineering: Leveraging Codex in an Agent-first World, 2026-02-11
- Birgitta Bockeler, Harness Engineering — First Thoughts(Martin Fowler 站点备忘录), 2026-02-17
- NousResearch, Hermes Agent(GitHub 发布), 2026-02-26
- Prithvi Rajasekaran / Anthropic, Harness Design for Long-running Application Development, 2026-03-24
- LangChain, Improving Deep Agents with Harness Engineering, 2026-03
- Birgitta Bockeler, Harness Engineering for Coding Agent Users(Martin Fowler 站点完整⽂章), 2026-04-02
- Red Hat Developer, Harness Engineering: Structured Workflows for AI-assisted Development, 2026-04-07
¶ 3 认识 Hermes Agent
前两章我们从宏观到微观,理解了智能体⼤普及的背景和 Harness Engineering 的底层原理。现在,是时候正式"打开盒⼦"了——让我们⾛进 Hermes Agent 这个项⽬本⾝,从团队背景、项⽬数据、系统架构、⽤户反馈到版本迭代,做⼀次完整的、百科式的深度认识。
不急着动⼿装,先把地图看清楚。
¶ 3.1 Hermes Agent:越⽤越强的 Agent 运⾏时
它是什么
Hermes Agent 是 NousResearch 推出的开源 Agent 运⾏时框架——你不需要写⼀⾏代码,⼀⾏ curl 安装后通过 CLI 或消息平台直接使⽤,它会在使⽤过程中⾃动学习和成长。
这⾥有两个关键词需要拆开理解。
第⼀个是 "Agent 运⾏时"(Agent Runtime)。什么叫运⾏时?简单说,就是让 Agent 能跑起来的⼀整套基础设施——模型调⽤、⼯具执⾏、状态管理、错误恢复、安全防护、⽣命周期管理。和OpenClaw 等同类产品相⽐,Hermes Agent 更强调运⾏时层⾯的⼯程化:不只是"能执⾏任务",更是系统性地解决"如何让 Agent 持续、可靠、安全地运⾏"。它内置 47 个⼯具、⽀持 18+ 模型提供商、接⼊ 14+ 消息平台,终端命令执⾏、⽹页搜索、浏览器⾃动化、⽂件管理、视觉分析、语⾳合成、定时任务,开箱即⽤。

第⼆个是 "越⽤越强"(The agent that grows with you)。这不是⼀句营销⼜号,⽽是三套独⽴但协作的成长系统⽀撑的技术事实:
| 成长机制 | 做什么 | 怎么理解 |
|---|---|---|
| 四层记忆系统 | 记住你的偏好、环境、历史对话 | 越来越了解你的同事——知道你用什么编辑器、喜欢什么代码风格、常访问哪些服务器 |
| 技能自动生成(Skill Auto-Creation) | 把成功完成的复杂任务自动提炼为可复用技能 | 相当于给自己写了一本操作手册,下次遇到同类任务直接翻 |
| GEPA 进化优化 | 分析执行失败的原因,自动改进技能和提示词 | 每次做完复盘,调整下次的工作方法——而且是自动复盘 |
官⽅数据显⽰,10-20 次同类任务后,Agent 的执⾏速度可以提升 2-3 倍。这个提速不是来⾃更快的模型,⽽是来⾃积累的技能和记忆——Agent 不再每次从零开始思考"该怎么做",⽽是直接调⽤上次总结好的⽅法。
安装⽅式也值得⼀提:⼀⾏命令搞定。
curl -fsSL https://hermes-agent.nousresearch.com/install.sh | bash
不需要 Python 虚拟环境,不需要 Docker,不需要写任何配置⽂件。装完就有 hermes 命令可⽤,运⾏ hermes 即进⼊交互式终端。对于消息平台⽤户,配置好 API Token 后运⾏ hermes gateway 即可在飞书、钉钉、Telegram 等平台上与 Agent 对话。
GitHub 项⽬⼀览
让我们⽤数据说话。打开 Hermes Agent 的 GitHub 主页(github.com/NousResearch/hermes-agent),你会看到⼀组令⼈印象深刻的数字:
| 指标 | 数值 | 备注 |
|---|---|---|
| Stars | 38.4k+ | 截至 2026 年 4 月 9 日 |
| Forks | 5,100+ | 活跃的二次开发社区 |
| Watchers | 158 | 关注项目动态的开发者 |
| Contributors | 142+ | 社区贡献者(v0.2.0 时已有 63 位) |
| License | MIT | 最宽松的开源协议,商用无限制 |
| 主要语言 | Python 93.8% | 其余为 TeX 3.0%、BibTeX 1.1%、Shell 0.5%、Nix 0.4%、JavaScript 0.3% |
| 首次发布 | 2026 年 2 月 25 日(v0.1.0) | Harness Engineering 概念命名后仅 20 天 |
| 最新版本 | v0.8.0(2026 年 4 月 8 日) | "The Intelligence Release" |
| 迭代速度 | 41 天内 8 个版本(v0.1.0 → v0.8.0) | 平均每 5 天一个新版本 |
| 测试覆盖 | 3,289+ 测试用例 | 覆盖 Agent、Gateway、Tools、Cron、CLI 五大模块 |
增长速度对⽐:作为参考,LangChain 在 2022 年 10 ⽉⾸次发布后,⼤约⽤了⼀年多时间达到40K Stars。Hermes Agent 在不到两个⽉内就做到了同等规模。当然,2026 年的 AI 开源⽣态和 2022年不可同⽇⽽语——项⽬基数更⼤、传播更快。但即便考虑到时代因素,这个增速依然说明社区对"越⽤越强的 Agent"有着强烈的真实需求。
核⼼开发者:项⽬由 Teknium(@teknium1)主导开发,他同时也是 NousResearch 的联合创始⼈。在 v0.2.0 版本中 Teknium 贡献了 43 个 PR,涵盖核⼼架构、Provider Router、Sessions、Skills、CLI 和⽂档;到 v0.7.0 时累计贡献已达 179 个 PR。作为 Hermes 系列⼤模型的核⼼开发者,Teknium 对模型能⼒边界有着极为深刻的理解——这也解释了为什么 Hermes Agent 的 Harness 设计如此"懂模型"。
NousResearch 背景
要理解 Hermes Agent 为什么会是这个样⼦,就需要了解它背后的团队。
NousResearch(nousresearch.com)是⼀家独⽴的 AI 研究实验室,由 Jeffrey Quesnelle、Teknium 和 Shivani Mitra 等⼈于 2023 年联合创⽴,最初是⼀个志愿者驱动的开源社区。2024 年 1 ⽉完成了 520 万美元种⼦轮融资,由 Distributed Global 和 OSS Capital 联合领投。
NousResearch 在 AI 开源社区的名声,⾸先是靠⼤模型微调打下来的。他们的 Hermes 模型系列——从 Nous-Hermes-13B 到 Hermes 2、OpenHermes 2.5、Hermes 3,再到最新的 Hermes 4——长期占据 HuggingFace 开源模型排⾏榜前列。仅 Hermes、Hermes 2 和 OpenHermes 2.5 三个版本,累计下载量就超过 3,300 万次。2026 年发布的 Hermes 4 系列更是被 VentureBeat 报道为"在多个基准测试中超越 ChatGPT"的开源模型。
从"做模型"到"做 Agent 运⾏时"——这个跨越看似突兀,实则顺理成章。NousResearch 团队花了两年多时间微调和评估各种⼤模型,⽐任何⼈都清楚模型的能⼒边界在哪⾥:模型能做什么、不能做什么、什么时候会犯错、犯错的模式是什么。这恰好是 Harness Engineering 最需要的知识——回忆Anthropic 的那句话:"every component in a harness encodes an assumption about what the model can't do on its own." NousResearch 对模型局限性的深刻理解,直接转化为了 Hermes Agent 的Harness 设计。
换⼀个⾓度理解:做模型的⼈来做 Agent 运⾏时,就像造引擎的⼈来设计整辆车——他最清楚引擎的输出特性,所以能造出最匹配的传动系统和底盘。
¶ 3.2 Hermes Agent 架构全景
现在我们从外向内,拆解 Hermes Agent 的完整技术架构。这⼀节的信息密度较⾼,⽬标不是让你记住每⼀个组件,⽽是建⽴⼀张"我知道它有什么、在哪⾥"的索引地图——后续实操时随时可以回来查。
四⼤⼊⼜
⽤户与 Hermes Agent 交互有四个⼊⼜,覆盖从命令⾏到消息平台到 IDE 的全场景:
| 入口 | 代码位置 | 规模 | 适用场景 |
|---|---|---|---|
CLI(cli.py) |
交互式终端 UI | 约 8,500 行 | 开发者日常使用——直接在终端和 Agent 对话,支持多行编辑、斜杠命令自动补全、流式输出 |
Gateway(gateway/run.py) |
消息网关服务器 | 约 7,500 行 | 在飞书/钉钉/Telegram 等 14+ 平台上使用 Agent,单进程多渠道 |
ACP(acp_adapter/) |
编辑器集成 | stdio/JSON-RPC | VS Code、Zed、JetBrains 等 IDE 内直接调用 Agent(Agent Communication Protocol) |
| Cron(调度器) | 定时任务引擎 | JSON 任务存储 | 无人值守的定时任务——每天早上 9 点发新闻摘要、每小时检查服务器状态 |
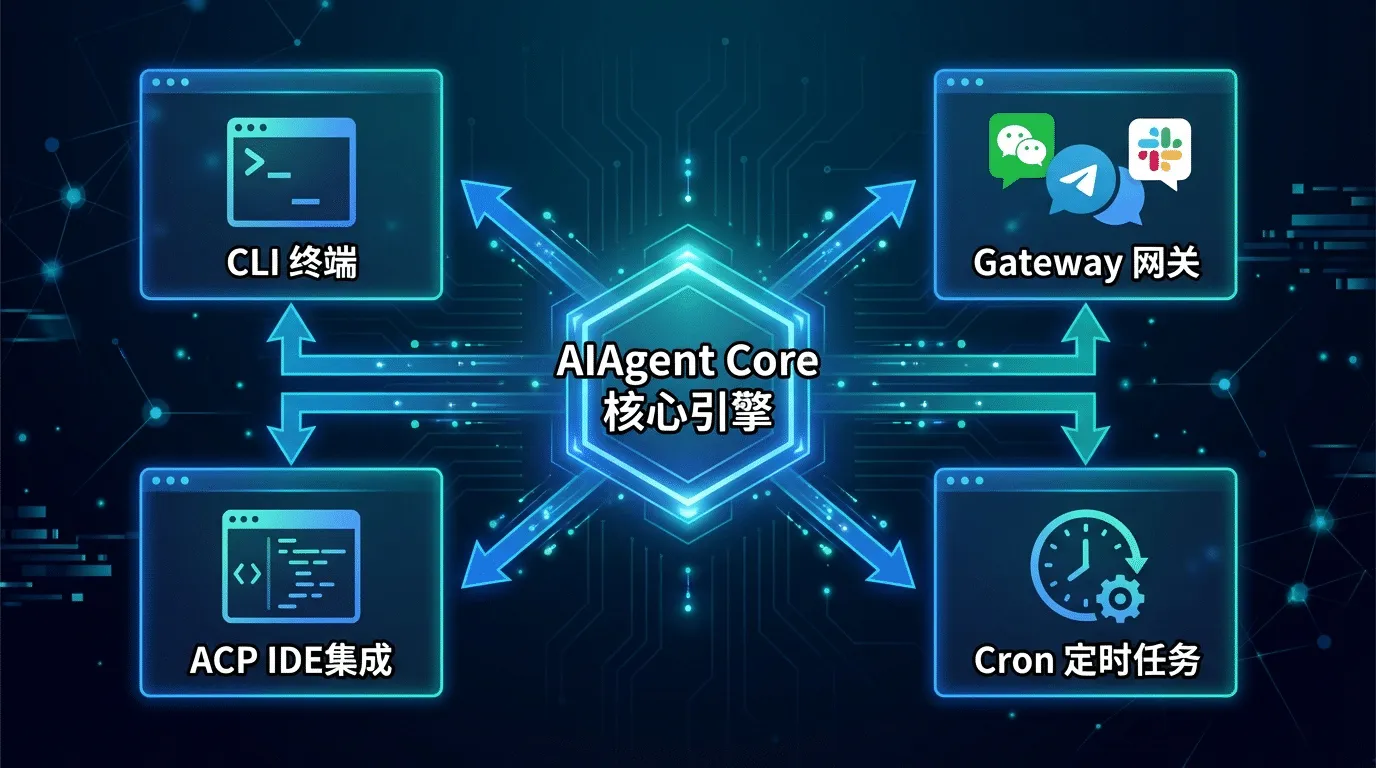
此外还有⼀个 Batch Runner(batch_runner.py ),⽤于 RL 训练的轨迹批量⽣成,⾯向研究者⽽⾮⽇常⽤户。
⼀个关键设计:四个⼊⼜共享同⼀个核⼼ Agent 引擎(AIAgent 类)。这意味着⽆论你从 CLI、飞书还是 VS Code 发起对话,Agent 的⾏为逻辑完全⼀致——相同的⼯具集、相同的记忆体系、相同的技能库。不存在"CLI 版功能⽐飞书版多"的情况。
核⼼编排层:AIAgent 类
所有⼊⼜最终都汇聚到核⼼编排层—— run_agent.py 中的 AIAgent 类(约 9,200 ⾏),它是整个系统的⼼脏:
Prompt Builder(提⽰词组装器)——从多个来源动态组装系统提⽰词:
| 来源 | 文件 | 作用 |
|---|---|---|
| 人格定义 | SOUL.md |
定义 Agent 的性格、说话风格、行为准则 |
| 工作记忆 | MEMORY.md |
Agent 自维护的长期事实记忆 |
| 用户画像 | USER.md |
用户偏好、环境、工作习惯 |
| 技能文档 | skills/ |
已安装的自定义技能的使用说明 |
| 项目上下文 | .hermes.md / AGENTS.md |
当前项目的特定约束和指导 |
| 工具指引 | 自动生成 | 模型专属的工具使用说明 |
补充解读
这是 Hermes Agent 的四层记忆+上下文系统的文件结构设计,核心作用是为AI Agent提供稳定、可复用、个性化的运行环境,属于Harness Engineering的核心实践之一:
- 分层设计逻辑:从「Agent自身」→「长期记忆」→「用户侧」→「任务侧」→「工具侧」,形成完整的上下文闭环,解决了AI Agent「记不住、不理解、不稳定」的核心痛点。
- 工程化价值:
SOUL.md统一Agent的行为风格,避免对话风格漂移;MEMORY.md实现Agent的自维护长期记忆,无需用户重复输入;USER.md沉淀用户习惯,实现个性化适配;skills/目录实现技能的可插拔、可复用;.hermes.md/AGENTS.md实现项目级约束,保障代码/任务符合团队规范;- 自动生成的工具指引,解决不同大模型工具调用格式不统一的问题。
- 设计亮点:将「引导型(Guides)」上下文工程落地为可维护的文件系统,同时结合推理型(Inferential)记忆检索,是确定性与灵活性的平衡。
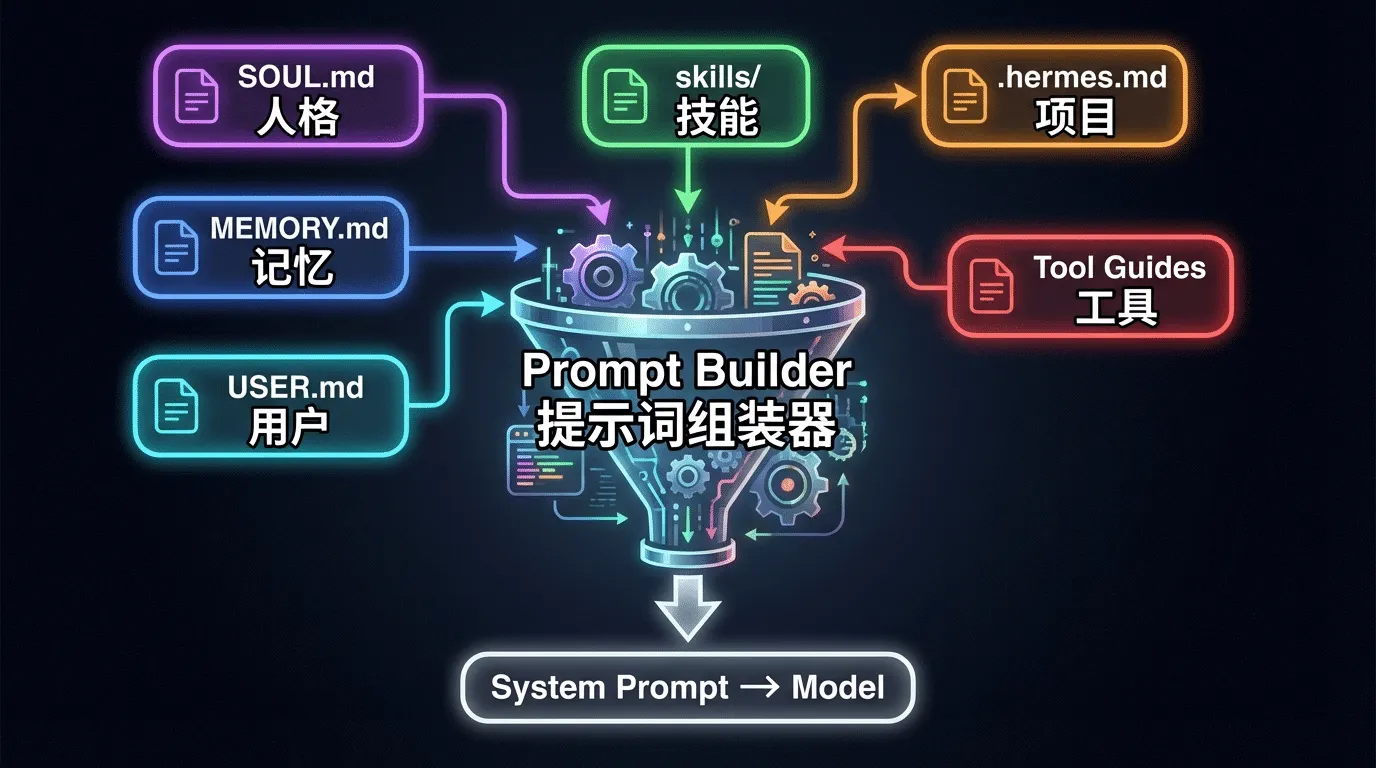
你可以把 Prompt Builder 想象成⼀个"⾏前准备清单"——每次 Agent 开始⼯作前,它会把所有需要知道的信息打包成⼀个系统提⽰词注⼊模型。这就是为什么 Hermes Agent 越⽤越懂你:
MEMORY.md 和 USER.md 在不断积累,每次对话的系统提⽰词都⽐上⼀次更丰富。
Provider Resolution(提供商解析器)——运⾏时动态选择模型。⽀持 18+ 提供商:Nous Portal、OpenRouter(200+ 模型)、OpenAI、Anthropic、Google AI Studio、DeepSeek、Kimi、MiniMax、智谱、Hugging Face 等。通过 resolve_runtime_provider() 函数实现多层凭证发现:显式指定 > 配置⽂件 > OAuth Token > 环境变量。⽀持 OAuth 设备流(Nous Portal)、凭证池轮换、和⾃动故障转移。⼀个 /model 命令即可在对话中途切换模型,⽆需重启。
Tool Dispatch(⼯具调度器)——47 个⼯具 x 20 个 Toolset 的统⼀调度中⼼。⼯具通过注册表模式(Registry Pattern)在导⼊时⾃注册,get_tool_definitions() 根据启⽤/禁⽤配置过滤可⽤⼯具,handle_function_call() 将模型的 JSON ⼯具调⽤请求桥接到 Python 处理函数。
Context Compressor(上下⽂压缩器)——当对话上下⽂超过阈值时⾃动触发,将中间对话轮次摘要化,防⽌长对话时上下⽂窗⼜爆满。会话有⾎统追踪(lineage tracking),压缩后的会话记录⽗/⼦关系。
三种 API 模式:chat_completions (OpenAI 兼容)、codex_responses (Codex 专⽤)、anthropic (Claude 原⽣ Messages API)。根据选择的模型⾃动切换,对⽤户透明。
⼯具系统详解
Hermes Agent 的⼯具系统是其作为"运⾏时框架"最直观的体现。47 个⼯具按功能分为 20 个Toolset(⼯具集),每个 Toolset 可以独⽴启⽤或禁⽤:
| Toolset | 典型工具 | 能力 |
|---|---|---|
| terminal | terminal |
在 6 种后端执行命令(Local/Docker/SSH/Daytona/Modal/Singularity) |
| file | read_file, patch |
文件读写、搜索、补丁 |
| web | web_search, web_extract |
网页搜索和内容提取 |
| browser | browser_navigate, browser_snapshot, browser_vision 等 11 个工具 |
完整的浏览器自动化——导航、截图、填表、点击 |
| vision | vision_analyze |
图像理解和分析 |
| image_gen | image_generate |
AI 图像生成 |
| tts | text_to_speech |
语音合成 |
| code_execution | execute_code |
沙箱化代码执行 |
| skills | 技能管理 | 创建、列出、编辑、删除技能 |
| memory | memory |
持久记忆操作 |
| session_search | session_search |
全文搜索历史会话 |
| cronjob | cronjob |
定时任务的增删改查 |
| delegation | delegate_task |
子 Agent 委派——生成隔离上下文的子 Agent 处理子任务 |
| todo | todo |
任务规划和追踪 |
| clarify | clarify |
向用户请求澄清 |
| moa | — | 多模型推理(Mixture of Agents) |
| homeassistant | ha_* |
智能家居控制 |
| rl | rl_* |
RL 训练环境交互 |

此外还有动态 MCP ⼯具集(mcp-<server>)——通过 MCP(Model Context Protocol)协议接⼊外部⼯具服务器,⽀持 stdio 和 HTTP 传输。
六种终端后端是 Hermes Agent ⼯具系统的⼀⼤亮点:
| 后端 | 适用场景 | 特点 |
|---|---|---|
| Local | 本机命令执行 | 最简单直接,适合个人开发 |
| Docker | 容器隔离执行 | 安全隔离,namespace 和硬化 |
| SSH | 远程服务器操作 | 管理远程机器 |
| Daytona | 云开发环境 | 支持休眠/唤醒,按需付费 |
| Modal | Serverless 执行 | 无服务器架构,自动伸缩 |
| Singularity | HPC 集群容器 | 适合 GPU 集群和学术计算 |
补充说明
这是 Hermes Agent 的
terminal工具集支持的6种命令执行后端,覆盖了从个人开发到企业级、科研级的全场景需求:
- 个人开发:优先用
Local,零配置直接用;- 安全隔离:选
Docker,避免污染本机环境;- 远程运维:用
SSH直接管理服务器;- 云端开发:
Daytona适合按需使用的云开发环境;- Serverless 场景:
Modal实现自动扩缩容的无服务器执行;- 高性能计算:
Singularity专为HPC/GPU集群设计,适配学术计算场景。
通过 config.yaml 中的 terminal.backend 配置或 TERMINAL_ENV 环境变量切换,对 Agent 完全透明。
MCP 集成与插件架构——v0.3.0 引⼊了插件系统,v0.8.0 进⼀步扩展。插件从三个位置发现:
~/.hermes/plugins/(⽤户级).hermes/plugins/(项⽬级)pip entry points(Python 包)
插件可以注册⼯具、Hook、CLI ⼦命令,接收请求级别的 API Hook(带 correlation ID),提⽰安装时的环境变量需求,以及 Hook 进会话⽣命周期事件(finalize/reset)。
记忆系统
记忆系统是 Hermes Agent "越⽤越强"的基⽯。它不是简单的"聊天记录存储",⽽是⼀个多层、多后端、可插拔的持久记忆体系。
四层记忆架构:
| 层 | 存储 | 内容 | 温度 |
|---|---|---|---|
| MEMORY.md | Markdown 文件 | Agent 自维护的长期事实记忆——你的开发环境、偏好、项目约定 | 热(每次对话注入系统提示词) |
| USER.md | Markdown 文件 | 用户画像——沟通风格、工作习惯、技能水平 | 热 |
| SQLite FTS5 | 本地数据库 | 全部历史会话的全文搜索索引 + LLM 摘要 | 冷(按需检索) |
| External Memory Providers | 可插拔后端 | v0.7.0 后支持 8 种外部记忆后端 | 冷/热视配置而定 |
补充解读
这是 Hermes Agent 的四层记忆系统设计,核心是通过「热记忆+冷记忆」的分层架构,解决AI Agent的长期记忆问题:
- 热记忆(Hot Memory):
MEMORY.md和USER.md是每次对话自动注入的高频上下文,保障Agent始终记住用户偏好、项目规则,避免重复提问;- 冷记忆(Cold Memory):
SQLite FTS5是按需检索的历史会话库,用全文检索+LLM摘要,在需要时召回历史信息,不占用上下文窗口;- 可插拔扩展:
External Memory Providers支持对接外部记忆后端(如向量数据库、Notion、飞书等),适配企业级、多端同步的记忆需求;- 工程化亮点:用简单的Markdown文件作为热记忆载体,兼顾了可读性、可维护性和大模型的上下文适配性,同时用SQLite实现高效的冷记忆检索,是轻量与性能的平衡。

前两层(MEMORY.md、USER.md)是"热"记忆——每次对话开始时 Prompt Builder 会⾃动将它们注⼊系统提⽰词,Agent 天然就"知道"这些信息。SQLite FTS5 是"冷"记忆——Agent 通过session_search ⼯具按需检索历史会话,类似于翻阅笔记本。
8 种外部 Memory Provider(v0.7.0+):
| Provider | 特点 |
|---|---|
| Honcho | 辩证用户建模——不是简单存储,而是通过辩证推理(dialectic reasoning)主动分析用户的偏好、目标、行为模式 |
| Mem0 | AI 原生记忆层 |
| OpenViking | 向量记忆后端 |
| Hindsight | 语义/图检索混合记忆 |
| Holographic | 全息记忆后端 |
| RetainDB | 持久化记忆数据库 |
| ByteRover | 字节级记忆 |
| Supermemory | 超级记忆后端 |
补充解读
这是 Hermes Agent v0.7.0+ 支持的 8 种可插拔外部记忆后端,对应上一张表的
External Memory Providers层,覆盖了从用户建模、向量检索、混合检索到持久化存储的全场景记忆需求:
- Honcho:核心亮点是主动式用户建模,区别于传统的被动存储,通过辩证推理主动分析用户行为,实现更精准的个性化适配;
- Mem0:AI 原生记忆层,专为大模型设计的轻量记忆方案,适配快速迭代的Agent场景;
- OpenViking:标准向量记忆后端,基于向量数据库实现语义检索;
- Hindsight:语义+图检索的混合架构,兼顾语义理解和关系型记忆的召回;
- Holographic/Supermemory:高阶记忆后端,支持更复杂的全息、超级记忆场景;
- RetainDB:持久化数据库,保障记忆数据的长期稳定存储;
- ByteRover:字节级记忆,实现底层数据级的记忆存储与检索。
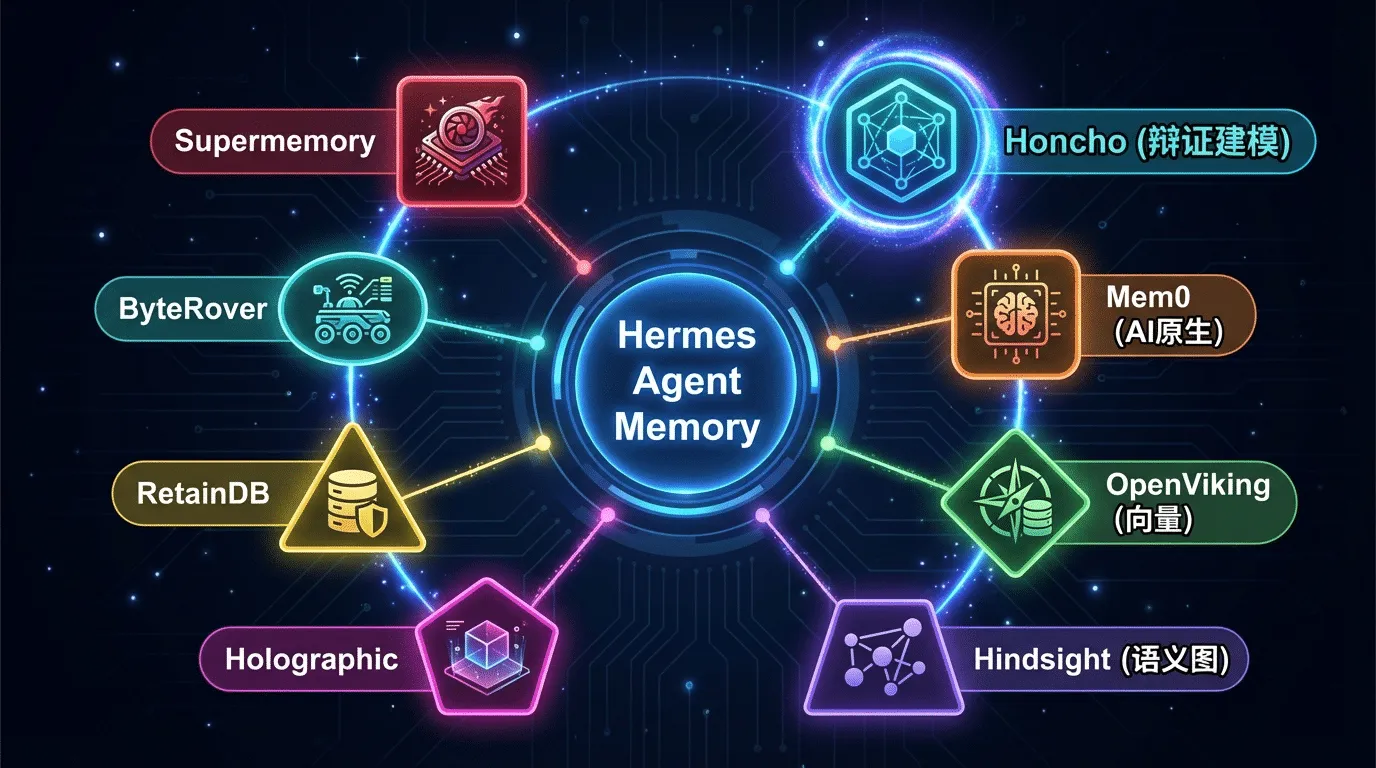
其中 Honcho 值得特别关注。普通的记忆系统是"你告诉我什么我记什么",Honcho 则更进⼀步——它在每次对话结束后主动分析对话内容,推导出关于⽤户的"结论"(conclusions):你的偏好、习惯、⽬标、沟通风格。这些结论随时间积累,Agent 对你的理解会越来越深⼊,甚⾄超越你明确告诉它的信息。
实⽤建议:Honcho 提供了很强⼤的⽤户建模能⼒,但有⼀个坑——它默认是关闭的。尽管Hermes Agent 的⼜号是"越⽤越强",但最核⼼的⽤户建模组件需要你⼿动在 config.yaml 中启⽤。这是⽬前社区反馈最集中的吐槽点之⼀。Lesson 2 案例 C 会⼿把⼿带你配置。
Gateway ⽹关架构
Gateway 是 Hermes Agent 连接外部世界的桥梁——它让 Agent 不只是⼀个终端⼯具,⽽是⼀个随时可触达的 AI 助⼿。
三层架构:
Platform Layer(平台适配层)
├─ Telegram Adapter
├─ Discord Adapter
├─ Slack Adapter
├─ WhatsApp Adapter
├─ Signal Adapter
├─ Feishu/Lark Adapter ← ⻜书
├─ DingTalk Adapter ← 钉钉
├─ WeCom Adapter ← 企业微信
├─ Matrix Adapter
├─ Mattermost Adapter
├─ Email (IMAP/SMTP) Adapter
├─ SMS (Twilio) Adapter
├─ Home Assistant Adapter
├─ BlueBubbles Adapter
└─ Webhook Adapter(通⽤ HTTP 接⼊)
Orchestration Layer(编排层)
├─ Authorization(Allowlist + DM Pairing)
├─ Session Routing(per-chat 会话隔离)
├─ Message Delivery(平台专属消息格式转换)
└─ Hook System(可扩展钩⼦)
Agent Layer(Agent 层)
└─ AIAgent(与 CLI 完全相同的核⼼引擎)
关键设计决策:
- 单进程多渠道:启动⼀个 hermes gateway 进程,即可同时服务飞书、钉钉、Telegram 等所有已配置平台。不需要每个平台单独部署⼀个实例。
- per-chat 会话管理:每个聊天(chat/channel/DM)维护独⽴的会话状态和记忆,不同⽤户之间完全隔离。
- 跨平台记忆共享:虽然会话是隔离的,但 MEMORY.md 和 USER.md 是共享的。你在 Telegram上教会 Agent 的偏好,在飞书上同样⽣效。
- 平台专属消息格式转换:delivery.py 模块⾃动将 Agent 的 Markdown 输出转换为各平台的原⽣富⽂本格式——Telegram 的 HTML、Slack 的 Block Kit、飞书的卡⽚消息等。
完整的 14+ 平台列表:
| 平台 | 引入版本 | 备注 |
|---|---|---|
| Telegram | v0.2.0 | 长轮询 + Webhook 双模式 |
| Discord | v0.2.0 | 支持语音频道 |
| Slack | v0.2.0 | v0.6.0 加入多 Workspace OAuth |
| v0.2.0 | 通过 WhatsApp Business API | |
| Signal | v0.4.0 | 端到端加密 |
| v0.2.0 | IMAP/SMTP | |
| Home Assistant | v0.2.0 | 智能家居集成 |
| DingTalk(钉钉) | v0.4.0 | 企业版机器人 |
| SMS | v0.4.0 | 通过 Twilio |
| Mattermost | v0.4.0 | 自托管团队聊天 |
| Matrix | v0.4.0 | v0.8.0 升级为 Tier 1:反应、已读回执、富文本、房间管理 |
| Webhook | v0.4.0 | 通用 HTTP 接入,对接任意系统 |
| Feishu/Lark(飞书) | v0.6.0 | 国际版 Lark 和国内版飞书均支持 |
| WeCom(企业微信) | v0.6.0 | 企业内部沟通 |
补充说明
这是 Hermes Agent Gateway 支持的全平台消息接入后端,覆盖了个人社交、企业办公、智能家居、通用系统等全场景:
- v0.2.0 首批支持:Telegram/Discord/Slack/WhatsApp/Email/Home Assistant,完成基础社交与办公场景覆盖
- v0.4.0 扩展支持:Signal/钉钉/SMS/Mattermost/Matrix/Webhook,补充加密通信、企业场景、通用接入
- v0.6.0 企业级完善:飞书/企业微信,适配国内企业办公生态,同时完善Slack多Workspace OAuth
- v0.8.0 功能升级:Matrix 升级为 Tier 1 核心支持,强化消息交互能力
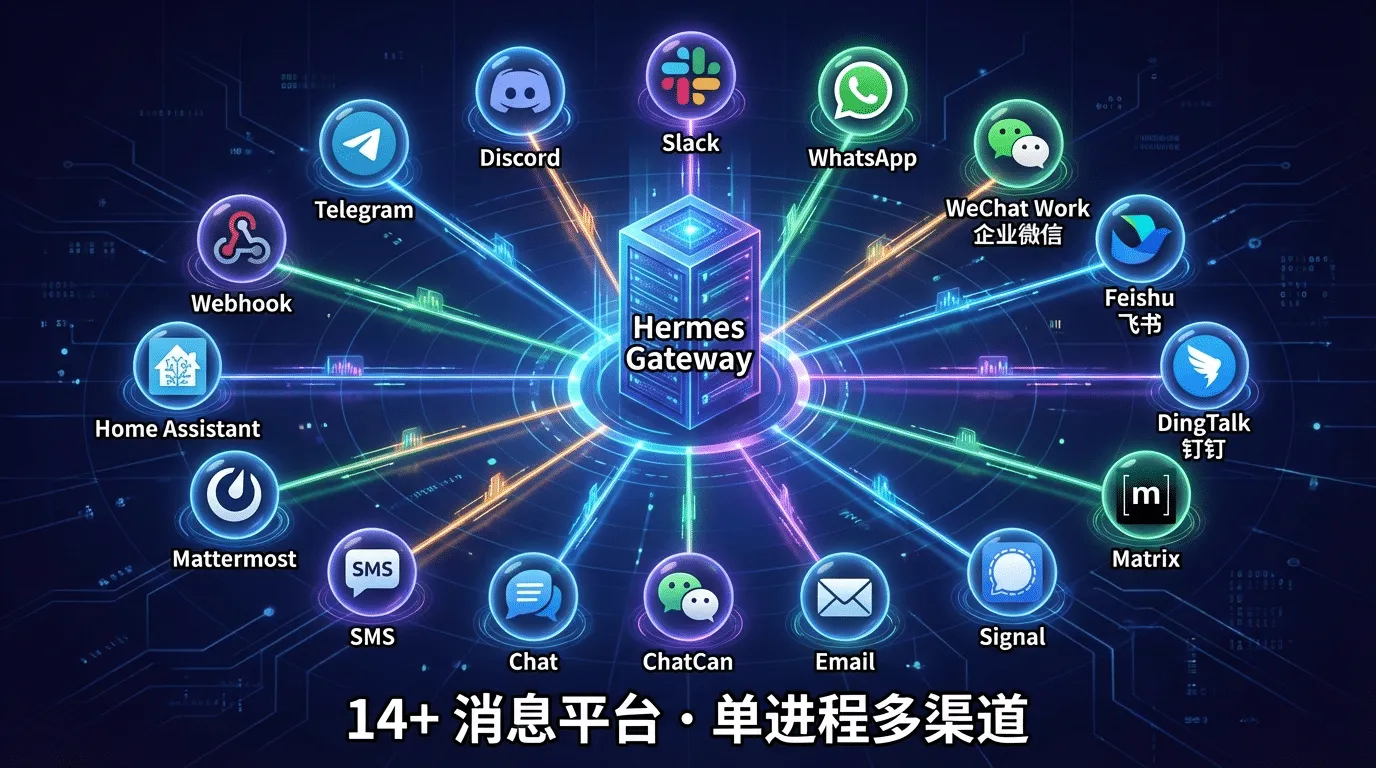
注:个⼈微信(WeChat)⽬前不在官⽅⽀持列表中。社区有第三⽅ Bridge ⽅案,但稳定性参差不齐。
Skill 系统与 GEPA ⾃演化
如果说记忆系统让 Agent "记住经验",那 Skill 系统就让 Agent "把经验变成能⼒",⽽ GEPA 则让Agent "⾃动优化这些能⼒"。三者组合在⼀起,构成了"越⽤越强"最核⼼的闭环。
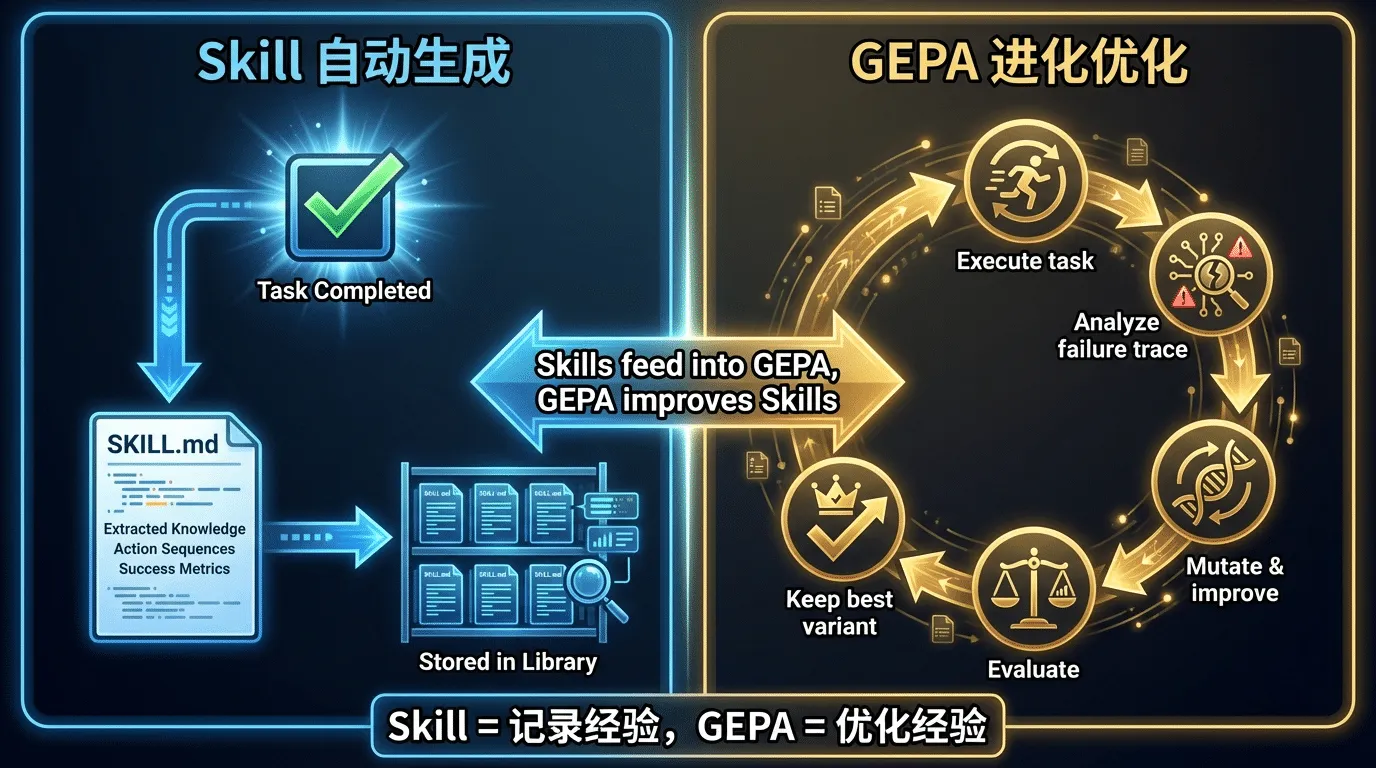
技能⾃动⽣成(Skill Auto-Creation)
当你让 Hermes Agent 完成⼀个复杂任务(⽐如"分析这个 GitHub 仓库的代码质量并⽣成报告"),如果任务成功完成,Agent 会⾃动将这个过程提炼为⼀个可复⽤的技能(Skill),保存在~/.hermes/skills/ ⽬录下。
技能遵循 agentskills.io 开放标准——⼀个简单的⽂件夹结构,核⼼是⼀个 SKILL.md ⽂件,包含 YAML 元数据和 Markdown 格式的操作步骤、注意事项、验证⽅法。这意味着:
- Hermes Agent 创建的技能可以被其他兼容 agentskills.io 的 Agent 平台使⽤
- 你可以⼿动编辑技能⽂件来微调 Agent 的⾏为
- 社区可以共享和交换技能(实际上已经有⼈在做了——awesome-hermes-agent 列表中收录了⼤量社区技能)
技能的加载采⽤渐进式披露(progressive disclosure):启动时只加载技能的名称和描述(⼏个token),完整的技能指令在使⽤时按需加载,最⼩化 token 消耗。
Hermes Agent 内置了 70+ 个 bundled 和 optional skills,覆盖 15+ 个类别——从代码分析、数据处理到系统管理、内容创作。
GEPA 进化优化(Reflective Prompt Evolution)
GEPA(反思式提⽰词进化,Reflective Prompt Evolution)是 Hermes Agent 最具学术深度的组件。它基于 Stanford ⼤学的 DSPy 框架(提⽰词⾃动优化框架),核⼼论⽂ "GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning"(Agrawal et al.)被接收为 ICLR 2026 Oral Paper ——这是顶级机器学习会议上仅约 1% 的论⽂能获得的殊荣。
GEPA 的核⼼思路:
- 执⾏任务 → 记录完整的执⾏轨迹(trace),包括每⼀步的输⼊、输出、错误信息、性能数据
- 反思分析 → 不是简单地看"成功还是失败"(那是 RL 的做法),⽽是⽤ LLM 阅读完整轨迹,理
解为什么失败——是提⽰词不够清晰?是⼯具选择错误?是步骤遗漏? - 进化搜索 → ⽤⾃然语⾔反馈进⾏多⽬标进化搜索,⾃动变异和改进技能的提⽰词和代码
- 验证评估 → 在测试任务集上评估改进后的技能,只保留真正变好的变异
论⽂数据:GEPA 在所有任务和模型上平均超越 MIPROv2(DSPy 之前的优化器)13%,在 MATH 基准测试上⽤ DSPy ChainOfThought 程序达到 93% 准确率(未优化基线为 67%)。
实际使⽤成本:每次优化运⾏ $2-10 的 API 调⽤费⽤,不需要 GPU。技能作为 DSPy 模块被包装,纯⽂本形式,易于变异,可直接测量效果。
独⽴仓库 NousResearch/hermes-agent-self-evolution 提供了完整的实现。
¶ 3.3 ⽤户社区与真实反馈
官⽅⽂档告诉你⼀个项⽬"能做什么",但只有真实⽤户才能告诉你它"实际做得怎样"。我们从多个渠道收集了社区反馈,好的坏的都给你看。
Reddit 社区反馈
Reddit 的 r/LocalLLaMA 和 r/AIAgents 社区是 Hermes Agent 讨论最活跃的地⽅。⼏组有意思的数据和观点:
迁移⽤户的体验对⽐(OpenClaw → Hermes):
- 多位⽤户反馈,执⾏同⼀个终端任务,OpenClaw 需要 50+ 次⼯具调⽤(tool calls),⽽Hermes Agent ⽤ 5 次就完成了,速度快了约 2.5 分钟。原因是 Hermes Agent 的 terminal ⼯具覆盖⾯更⼴(⼀次调⽤可以执⾏多步操作),⽽ OpenClaw 的⼯具设计更细粒度。
- 但也有⽤户指出:OpenClaw 的细粒度控制在审计和调试时更有优势——你能清楚看到 Agent 每⼀步做了什么。Hermes 的"⼤步快⾛"风格有时会让出错时难以定位问题。
Token 消耗的真相:
- ⼀位 Reddit ⽤户做了精确测量,发现 Hermes Agent 每次 API 调⽤中 73% 是固定开销——光是列出所有可⽤⼯具的 schema 就要烧掉约 14,000 tokens,还没读你的消息就花了这么多。这在使⽤按 token 计费的模型时是⼀个需要注意的成本因素。
实⽤建议:可以通过 config.yaml 中的 toolsets.disabled 配置关闭不需要的⼯具集来降低固定开销。⽐如你不⽤浏览器⾃动化,关掉 browser toolset 可以省下不少 token。
开发者评价
DEV.to 社区评价:
- "Hermes Agent: A Self-Improving AI Agent That Runs Anywhere" — ⽂章重点赞了跨平台⼀致性和技能⾃⽣成机制
- ⼀位评测者在 v0.5.0 上测试:11 分钟完成安装,2 ⼩时内 Agent ⾃动创建了 3 个技能⽂档,⽤这些技能完成同类研究任务时速度提升 40%
Medium 长⽂评测:
- "The Quiet Shift in AI Agents: Why Hermes Is Gaining Ground Beyond OpenClaw" — 重点分析了Hermes 在"记忆 + 技能 + 进化"三维度上的差异化优势
- "ElizaOS vs. OpenClaw vs. Hermes: What Actually Matters in 2026" — 三⽅对⽐中 Hermes 在⾃演化和安全性维度领先(零 Agent CVE),但在⽣态规模上落后于 OpenClaw
⾮技术⽤户体验:
- ⼀位⾃称"⾮技术⽤户"的评测者写道:"this one feels like it was made for people like me"——安装简单(⼀⾏命令),任务配置是"if-then"逻辑⽽⾮真正的编程
- 另⼀位⽤户 1 ⼩时内就⽤ Hermes Agent 搭建了⼀个"⾃动收集 Reddit 和 X 上 Top 5 热门 AI 开源话题"的定时报告系统
已知问题和坑
社区反馈中被提到最多的问题,我们直接列出来,省得你踩:
| 问题 | 严重程度 | 现状 |
|---|---|---|
| Honcho 默认关闭 | 高——直接影响"越用越强"的体验 | 需手动在 config.yaml 中启用 |
| Token 固定开销高 | 中——使用按量计费模型时费用明显 | 可通过禁用不需要的 toolset 缓解 |
| 文档不足 | 中——官方文档覆盖面不错但深度不够 | 社区在不断补充第三方教程 |
| 多 Agent 协作弱 | 中——只有 delegate_task,无真正多 Agent 通信 | 在路线图中(GitHub Issue #344) |
| 破坏性版本变更风险 | 中——迭代太快,版本间不保证完全兼容 | 建议锁定版本使用 |
| Skills 自动创建不可控 | 低——Agent 自动创建的技能不一定符合预期 | OpenClaw 的做法是需要用户确认才创建 |
补充解读
这是 Hermes Agent 当前版本(v0.8.0)的已知问题与风险清单,按严重程度分级:
- 高优先级问题:
Honcho 默认关闭是核心体验痛点,该模块是实现Agent"越用越强"的关键,需手动开启才能生效;- 中优先级问题:
Token 开销高:可通过裁剪工具集优化成本,适合按量计费大模型用户;文档深度不足:官方基础文档完善,但进阶用法依赖社区补充;多Agent协作弱:仅支持基础子任务委派,无完整多Agent通信架构,已在开发路线图中;版本兼容性风险:项目迭代极快(41天8个版本),版本间存在不兼容变更,生产环境建议锁定版本;- 低优先级问题:
技能自动创建不可控属于体验优化项,参考OpenClaw的用户确认机制可规避风险。
社区⽣态
围绕 Hermes Agent 已经形成了⼀个活跃的社区⽣态:
awesome-hermes-agent——社区策展的资源列表,收录了 80+ 个项⽬:
| 类别 | 数量 | 代表项目 |
|---|---|---|
| 官方资源 | 8 | 核心仓库、文档站、self-evolution |
| 社区技能 | 8 | 跨平台技能库(380+ Stars) |
| agentskills.io 生态 | 10 | Chainlink 官方技能、安全审计技能 |
| 插件 | 7 | 目标管理、Agent 桥接、模型选择、成本控制 |
| 工具和 UI | 10+ | Mission Control(3,700+ Stars)、Hermes Workspace(500+ Stars) |
| 部署方案 | 4 | Docker、Nix、WSL、云部署 |
| 多 Agent 编排 | 4 | 跨 Agent 桥接、Swarm |
| 领域应用 | 10+ | 机器人、区块链、法律、创意写作、DevOps |
补充解读
这是 Hermes Agent 围绕核心项目构建的完整生态矩阵,覆盖从官方到社区、从工具到应用的全链路:
- 生态分层逻辑:从「核心资源」→「技能生态」→「插件工具」→「部署方案」→「领域应用」,形成完整的Agent开发与使用闭环;
- 核心亮点:
- 技能生态繁荣:社区技能+agentskills.io平台,沉淀了大量可复用技能,实现"即插即用";
- 工具UI完善:Mission Control(3.7k+ Stars)等UI工具,降低了普通用户的使用门槛;
- 部署灵活:支持Docker/Nix/WSL/云部署等4种方案,适配个人、企业、云端全场景;
- 领域覆盖广:从区块链、DevOps到法律、创意写作,实现多行业的Agent落地;
- 工程化价值:该生态将Harness Engineering从概念落地为可复用的工具链、技能库、部署方案,是AI Agent工程化的典型实践。
成熟度分布:约 15 个项⽬达到 Production 级别,40 个处于 Beta,25 个处于 Experimental 阶段。整体⽣态还很年轻,但增速很快。
¶ 3.4 OpenClaw vs Hermes Agent:两个通⽤ Agent 的不同侧重
很多同学的第⼀个问题是:"我已经在⽤ OpenClaw 了,Hermes Agent 跟它是什么关系?要替换吗?"
答案很简单:不是替换,是互补。两者解决的是完全不同的核⼼问题。
核⼼定位对⽐
OpenClaw 是⽬前最流⾏的通⽤个⼈ AI 助⼿——346K Stars、20+ 消息渠道、44K+ 技能、50+ 平台⽀持。它的核⼼抽象是 "多渠道消息⽹关 + 个⼈助⼿":把所有平台连起来,让⼀个 AI 助⼿⽆处不在。
Hermes Agent 同样是⼀个通⽤ Agent,但它的侧重点完全不同:不只是"帮你做事",更是"在做事的过程中学习并持续变强"。47 个⼯具、14+ 平台、四层记忆、技能⾃⽣成、GEPA 进化优化——它的核⼼抽象是 "Harness ⼯程化的 Agent 运⾏时"。
⼀句话区分:OpenClaw 侧重"连接⼀切",Hermes Agent 侧重"越⽤越强"。
七维度对⽐表
| 维度 | OpenClaw | Hermes Agent |
|---|---|---|
| 核心侧重 | 多渠道个人AI助手(连接一切) | Harness 工程化Agent运行时(越用越强) |
| 上手方式 | 多平台部署 + 渠道接入 | 一行 curl 安装,零代码启动 |
| 渠道覆盖 | 20+ 渠道(WhatsApp/Telegram/Slack/飞书/微信/邮件等) | 14+ 平台内建网关(Telegram/Discord/Slack/飞书/钉钉/企微等) |
| 记忆与成长 | 会话记忆 + 用户偏好存储 | 四层记忆(MEMORY.md + USER.md + SQLite FTS5 + 8种外部Provider)+ 技能自生成 + GEPA进化 |
| 多Agent协作 | 多Agent架构成熟 | 仅子Agent委派(隔离上下文),完整多Agent在路线图 |
| 工具生态 | 核心工具链 + 44K+ 社区技能 | 47个工具 × 20个Toolset(终端/浏览器/搜索/文件/视觉/语音/调度等) |
| 自演化能力 | 无自动进化机制(技能需用户手动编写和确认) | DSPy + GEPA自动进化(ICLR 2026 Oral Paper),$2-10/次 |
补充解读
这是两款主流AI Agent项目的核心能力对比表,清晰展现了两者的定位差异与技术特点:
- 定位差异
- OpenClaw:主打「多渠道个人AI助手」,核心是连接各类平台,以成熟的多Agent架构和海量社区技能为核心优势,适合需要跨平台统一助手的用户。
- Hermes Agent:主打「Harness工程化Agent运行时」,核心是通过环境设计让Agent稳定自主工作,以四层记忆、自动技能生成、GEPA自动进化为核心,实现「越用越强」的体验。
- 关键能力对比
- 上手门槛:Hermes Agent零代码一键安装,对新手更友好;OpenClaw需多平台部署,更适合有一定技术基础的用户。
- 记忆与成长:Hermes Agent的四层记忆+自动进化机制,是其核心差异化优势,能主动学习用户习惯、优化技能;OpenClaw仅支持基础记忆,技能需手动创建。
- 多Agent协作:OpenClaw架构成熟,支持完整多Agent通信;Hermes Agent仅支持基础子任务委派,完整多Agent能力在开发路线中。
- 工具生态:OpenClaw以社区技能为核心,技能数量庞大;Hermes Agent以内置工具集为核心,覆盖全场景开发需求。
- 自演化能力:Hermes Agent基于ICLR 2026论文的GEPA自动进化,是技术亮点,但有一定成本;OpenClaw无自动进化,需用户手动确认。
- 选型建议
- 个人开发、追求Agent自主成长、零代码上手:优先选 Hermes Agent
- 多平台统一助手、成熟多Agent协作、海量社区技能:优先选 OpenClaw
注:对⽐数据基于 OpenClaw 当前版本与 Hermes Agent v0.8.0,来源为各⾃官⽅⽂档和 GitHub 仓库。
真实⽤户怎么说
Reddit 社区有⼀组有意思的迁移数据:多位⽤户反馈,执⾏同⼀个终端任务,OpenClaw 需要 50+ 次⼯具调⽤(tool calls),⽽ Hermes Agent ⽤ 5 次就完成了,速度快了约 2.5 分钟。
但这不是说 Hermes Agent"更好"——这只是说明两者的设计哲学不同。OpenClaw 侧重细粒度控制和可审计性,Hermes Agent 侧重执⾏效率和⾃主性。⼯具调⽤粒度也不同:OpenClaw 倾向精细控制,Hermes Agent 的单个 terminal ⼯具覆盖⾯更⼴。
诚实承认各⾃的短板
Hermes Agent 的短板:
-
多 Agent 协作是弱项。当前只有 delegate_task (⽣成隔离的⼦ Agent,不能互通),真正的多 Agent 架构还在路线图上(GitHub Issue #344)。如果你的场景需要多个 Agent 协作分⼯,OpenClaw 的⽅案⽬前成熟得多。
-
渠道覆盖⾯略窄于 OpenClaw。OpenClaw ⽀持 20+ 消息渠道(含个⼈微信、WhatsApp),Hermes Agent 当前为 14+ 平台,部分渠道仍在开发中。
-
⽣态体量差距⼤。OpenClaw 有 346K Stars 和 44K+ 社区技能,Hermes Agent 的 40K Stars 和 80+ 社区项⽬在规模上不在⼀个量级。
OpenClaw 的相对弱项:
- ⾃演化能⼒缺失。没有类似 GEPA 的⾃动进化机制,技能需要⽤户⼿动编写和维护,Agent 不会从失败中⾃动学习改进。
- 持久记忆体系较浅。有会话记忆和⽤户偏好存储,但缺少 Hermes Agent 那样的多层持久记忆体系(四层记忆 + 跨会话全⽂搜索 + 8 种外部 Provider + Honcho 辩证建模)。
- Harness ⼯程化程度不够。OpenClaw 更像⼀个"功能集合",Hermes Agent 更像⼀个"架构体系"。
什么场景⽤哪个
| 你的场景 | 推荐工具 | 原因 |
|---|---|---|
| 多渠道消息接入(WhatsApp/个人微信/邮件等) | OpenClaw | 渠道覆盖面最广,50+ 平台原生支持 |
| 需要 Agent 越用越强、自动积累经验 | Hermes Agent | 技能自生成 + GEPA 进化 + 四层持久记忆 |
| 终端深度自动化(47 个工具覆盖终端/浏览器/视觉/语音) | Hermes Agent | 工具覆盖面和终端后端选择最丰富 |
| 飞书/钉钉 AI 助手 | 两者均可 | 都原生支持飞书/钉钉 |
| 需要 Agent 从失败中自动学习改进 | Hermes Agent | GEPA 进化优化是独有能力 |
| 需要成熟的多 Agent 协作 | OpenClaw | Hermes 在此维度尚处早期 |
| 需要最大的社区生态和技能市场 | OpenClaw | 346K Stars + 44K+ 技能 |
| 两者都想用 | 两者并行 | OpenClaw 管连接,Hermes Agent 管成长,互不冲突 |
补充解读
这是 OpenClaw 与 Hermes Agent 的场景化选型指南,基于两款产品的核心定位差异,给出了明确的选择建议:
- 核心选型逻辑
- OpenClaw 优势场景:多渠道接入、成熟多Agent协作、海量社区技能,主打「连接一切」的个人AI助手;
- Hermes Agent 优势场景:终端自动化、自动成长进化、持久记忆,主打「越用越强」的工程化Agent运行时;
- 通用场景:飞书/钉钉等国内企业平台,两款产品均原生支持,可按需选择。
- 高阶方案:两者并行
指南给出了最优组合方案:用 OpenClaw 负责多平台消息接入,用 Hermes Agent 负责Agent的记忆、技能与自动进化,两者互补不冲突,同时享受两款产品的核心优势。- 选型建议总结
- 个人开发、追求Agent自主成长、终端自动化:选 Hermes Agent
- 多平台统一助手、成熟多Agent、海量技能:选 OpenClaw
- 全场景需求:两者并行部署,实现能力互补
⼀句话总结:OpenClaw 强在"连接⼀切",Hermes Agent 强在"越⽤越强"。不是⼆选⼀,是各取所长。
¶ 【参考】3.5 Hermes 的四⼤ Harness 层级
理解了 Hermes Agent 的技术架构之后,我们⽤⼀个更⾼层的框架来理解它——四⼤ Harness 层级。这个框架把 Hermes Agent 的所有能⼒组织成四个递进的层次,每⼀层都在解决"模型⾃⼰做不了什么"的不同维度。
四层架构表

| 层级 | 名称 | 解决什么问题 | 核心能力 | Lesson 2 对应案例 |
|---|---|---|---|---|
| L1 | Agent 运行时基座 | 模型不能直接操作终端/文件/网页 | 47 个工具 × 20 Toolset + 6 种终端后端 + CLI | 案例 A:Terminal Agent |
| L2 | 消息网关 (Gateway) | 模型不能直接连接飞书/钉钉 | 14+ 消息平台适配器 + per-chat 会话管理 | 案例 B:飞书 AI 助手 |
| L3 | 持久记忆 | 模型没有跨会话记忆 | MEMORY.md + USER.md + SQLite FTS5 + 8 种外部 Provider |
案例 C:持久记忆 |
| L4 | Skill 自主进化 | 模型不会从经验中自动提炼方法 | 技能自动生成 + GEPA 进化优化(ICLR 2026) | 案例 D:Skill 自进化 |
补充解读
这是 Hermes Agent 核心的 四层 Harness 架构设计,完整定义了让AI Agent稳定、可靠、自主工作的工程化分层方案:
- 分层逻辑:从「基础能力」→「多端接入」→「长期记忆」→「自主进化」,逐层解决大模型Agent的核心痛点,形成完整的运行环境闭环。
- 各层核心价值
- L1 运行时基座:解决大模型「不能直接操作物理世界」的问题,通过47个工具+多终端后端,让Agent能直接操作终端、文件、浏览器等,是Agent的能力底座;
- L2 消息网关:解决大模型「不能直接连接企业IM平台」的问题,通过14+平台适配器,让Agent能在飞书/钉钉等平台直接使用;
- L3 持久记忆:解决大模型「没有跨会话记忆」的问题,通过四层记忆系统,让Agent记住用户偏好、项目规则,实现个性化;
- L4 自主进化:解决大模型「不会从经验中学习」的问题,通过技能自生成+GEPA进化优化,让Agent自动从成功/失败中学习,实现「越用越强」。
- 工程化亮点:该架构将Harness Engineering从概念落地为可复用的分层系统,每一层都对应明确的问题、能力与实战案例,是AI Agent工程化的标准参考架构。
为什么是这四层
这四层不是随意划分的。回忆 Anthropic 的那句话:
"Every component in a harness encodes an assumption about what the model can't do on its own."
(Harness 中的每⼀个组件,都编码了⼀个关于"模型⾃⼰做不了什么"的假设。)
每⼀层都对应着模型能⼒的⼀个缺口:
- L1 填补执⾏缺⼜:再聪明的模型,不能亲⾃运⾏⼀条 git push 命令。运⾏时基座给模型装上了"⼿脚"。
- L2 填补连接缺⼜:模型不能主动给你发飞书消息。消息⽹关让 Agent 从终端⾛进你的⽇常沟通⼯具。
- L3 填补记忆缺⼜:每次新会话,模型不记得你是谁、之前聊过什么。持久记忆让 Agent 从"⾦鱼"变成"⽼同事"。
- L4 填补学习缺⼜:模型不会⾃动总结"上次这个任务我怎么做的,下次做更快"。Skill ⾃主进化让Agent 真正"越⽤越强"。
从 L1 到 L4,每⼀层都是在上⼀层基础上的递进。没有 L1 的⼯具执⾏能⼒,L2 的消息⽹关⽆从发挥;没有 L3 的记忆积累,L4 的技能进化缺乏数据基础。
四层递进:从"能⽤"到"越⽤越强"
如果你只⽤ L1(Terminal Agent),Hermes Agent 就是⼀个功能丰富的终端 AI 助⼿——有⽤,但和很多⼯具差别不⼤。
加上 L2(Gateway),它变成了⼀个随时可触达的 AI 助⼿——不⽤打开终端,在飞书⾥就能和它对话。
加上 L3(Memory),它变成了⼀个了解你的 AI 助⼿——记得你的开发环境、编码偏好、常⽤⼯具链。
加上 L4(Skill Evolution),它变成了⼀个会成长的 AI 助⼿——今天做过的复杂任务,明天变成⼀键复⽤的技能。
这四层叠加在⼀起,就是 "The agent that grows with you" 的完整含义。
重要提醒:本章只建⽴四⼤层级的概念地图,帮你理解 Hermes Agent 的整体架构。每个层级的详细机制——如何配置记忆 Provider、如何触发 Skill ⾃动⽣成、如何部署飞书⽹关——全部在Lesson 2 中通过四个动⼿案例逐⼀展开。现在只需记住这张地图,不需要深⼊每⼀层的细节。
¶ 【参考】3.6 版本迭代与发展路线
Hermes Agent 的版本迭代速度,即便在 2026 年快节奏的 AI 开源世界中也是令⼈瞠⽬的。41 天内 8 个版本(v0.1.0 → v0.8.0),平均每 5 天⼀个正式发布。让我们快速浏览这条时间线,理解项⽬的进化轨迹。
版本发布时间线
| 版本 | 发布日期 | 主题 | 关键更新 |
|---|---|---|---|
| v0.1.0 | 2026-02-25 | Foundation Release | 初始发布——核心 Agent 引擎、CLI、基本工具链,内部基础版本 |
| v0.2.0 | 2026-03-12 | Platform Release | 里程碑式版本:216 个 PR、63 位贡献者;Telegram/Discord/Slack/WhatsApp/Signal/Email/HomeAssistant 七大平台、MCP 集成、70+ 技能、ACP 编辑器集成、3,289 测试用例 |
| v0.3.0 | 2026-03-17 | Streaming & Plugins | 统一流式输出、插件架构、Anthropic 原生 Provider、智能审批、语音模式、并发工具执行、Honcho 记忆集成 |
| v0.4.0 | 2026-03-23 | Platform Expansion | OpenAI 兼容 API 服务器、6 个新平台适配器(Signal/DingTalk/SMS/Mattermost/Matrix/Webhook)、4 个新 Provider、MCP OAuth2.1、200+ Bug 修复 |
| v0.5.0 | 2026-03-28 | Hardening Release | 供应链安全审计、50+ 安全修复、HuggingFace Provider、Modal SDK、Nix flake、插件生命周期 Hook |
| v0.6.0 | 2026-03-30 | Multi-Instance Release | Profile 多实例系统、MCP Server 模式、Docker 容器、Provider 故障链、飞书/Lark 支持、企业微信支持、Slack 多 Workspace OAuth |
| v0.7.0 | 2026-04-03 | Resilience Release | 可插拔记忆 Provider(8 种后端)、凭证池轮换、Camofox 反检测浏览器、内联 diff 预览、深度安全修复;168 个 PR、46 个 Issue 解决 |
| v0.8.0 | 2026-04-08 | Intelligence Release | 后台任务自动通知、在线模型切换、自优化 GPT/Codex 引导、Google AI Studio 原生 Provider、MCP OAuth2.1 PKCE + OSV 恶意软件扫描、集中日志、插件扩展、Matrix Tier 1 |
补充解读
这是 Hermes Agent 从 v0.1.0 到 v0.8.0 的完整迭代历史,清晰展现了项目的快速演进路线:
- 迭代速度:41天内完成8个大版本迭代,平均每5天发布一个新版本,是AI Agent领域迭代极快的开源项目。
- 版本演进逻辑
- v0.1.0-v0.2.0:完成基础能力与多平台接入,从核心引擎到14+消息平台,奠定项目基础;
- v0.3.0-v0.4.0:完善插件架构、流式输出、平台扩展,补充企业场景与通用接入;
- v0.5.0-v0.6.0:强化安全、多实例、Docker部署,适配企业级生产环境;
- v0.7.0-v0.8.0:完善记忆系统、自动优化、安全防护,向「越用越强」的智能Agent演进。
- 核心里程碑
- v0.2.0:首个里程碑版本,完成平台生态与工具链的基础建设;
- v0.7.0:引入可插拔记忆后端,实现Agent的持久化与个性化;
- v0.8.0:智能版本,强化自动优化、多模型支持与安全能力,是当前最新稳定版。
迭代速度意味着什么
这个迭代速度值得从两⾯来看。
好的⼀⾯:
- 项⽬⽣命⼒极强。41 天 8 个版本,每个版本都不是⼩修⼩补⽽是实质性功能发布。v0.2.0 ⼀次性拿出 7 ⼤平台、70+ 技能和 3,289 个测试⽤例,这是⾮常⾼的⼯程产出效率。
- 社区参与度⾼。仅 v0.2.0 就有 63 位贡献者贡献了 216 个 PR,这对⼀个不到两个⽉的项⽬来说⾮常罕见。
- 主题清晰递进。从基础(v0.1-0.2)→ 流式和插件(v0.3)→ 平台扩展(v0.4)→ 安全加固(v0.5)→ 多实例(v0.6)→ 弹性(v0.7)→ 智能化(v0.8),每个版本有明确的主题和定位。
需要注意的⼀⾯:
- ⾼速迭代 = 教程容易过时。你今天看到的博客教程可能基于 v0.3.0,⽽你安装的是 v0.8.0,配置项和⾏为可能已经变了。这也是本课程锁定 v0.8.0 的原因之⼀。
- 破坏性变更风险。项⽬还在 v0.x 阶段(未到 v1.0),意味着不保证向后兼容。版本间的配置格式、API 接⼜、⼯具⾏为都可能发⽣变化。
- ⽣态早期。awesome-hermes-agent 中 80+ 个项⽬⾥只有约 15 个达到 Production 级别,⼤多数还在 Beta 或 Experimental 阶段。
¶ 【参考】4 模型、⼯具与版本详解
前⾯三章我们从宏观背景到 Harness 原理再到 Hermes Agent 全景完成了认知建设。这⼀章是实⽤速查表——模型提供商的详细配置、⼯具系统的完整清单、v0.8.0 的核⼼亮点,每⼀项都是你上⼿实操时需要翻阅的参考。
¶ 4.1 模型提供商⽀持清单(v0.8.0)
Hermes Agent 不绑定任何特定模型——它兼容所有 OpenAI-compatible API,原⽣⽀持 18+ 模型提供商。对国内⽤户⽽⾔,最重要的信息是:国产四⼤模型(DeepSeek / Kimi / MiniMax / 智谱)均有原⽣⽀持,API 端点在国内,⽆需翻墙。
云端 API 提供商
| 提供商 | 环境变量 | 国内可用性 | 备注 |
|---|---|---|---|
| DeepSeek | DEEPSEEK_API_KEY |
直连可用 | 本课程默认模型,性价比最高 |
| Kimi (Moonshot) | KIMI_API_KEY |
直连可用 | 128K 超长上下文 |
| MiniMax | MINIMAX_API_KEY |
直连可用 | v0.8.0 新增 TTS(Text-to-Speech,文字转语音)Provider(speech-2.8) |
| 智谱(z.ai / GLM) | GLM_API_KEY |
直连可用 | Z.ai 端点自动探测(v0.8.0) |
| Nous Portal | OAuth(开放授权协议)授权 | 需翻墙 | Hermes 系列模型原生托管,含免费 MiMo v2 Pro |
| OpenRouter | OPENROUTER_API_KEY |
需翻墙 | 200+ 模型聚合(Claude / GPT-5 / Gemini 等) |
| OpenAI | OPENAI_API_KEY |
需翻墙 | GPT-5 / o-series / Codex 系列 |
| Anthropic | ANTHROPIC_API_KEY |
需翻墙 | Claude 系列 |
| Google Gemini | GOOGLE_API_KEY |
需翻墙 | v0.8.0 新增原生 Google AI Studio 集成 |
| Hugging Face | HF_TOKEN |
需翻墙 | 17+ Inference Providers |
| GitHub Copilot | GH_TOKEN |
需翻墙 | 通过 Device Code Flow 认证 |
| 阿里(DashScope / Qwen) | DASHSCOPE_API_KEY |
直连可用 | 通义千问系列 |
| xAI (Grok) | XAI_API_KEY |
需翻墙 | v0.8.0 新增 Prompt Caching |
补充解读
这是 Hermes Agent 支持的全模型提供商列表与配置说明,覆盖了国内外主流大模型,同时标注了国内可用性与核心特性:
- 国内用户友好选型
- 直连可用(无需翻墙):DeepSeek、Kimi、MiniMax、智谱、阿里通义千问,其中 DeepSeek 是项目默认推荐,性价比最高;
- 核心优势:国内模型均原生适配,无需额外代理,同时支持超长上下文、语音合成等特色能力。
- 国际模型支持
- 覆盖OpenAI、Anthropic、Google、xAI等国际主流模型,同时支持OpenRouter聚合200+模型,适配全场景需求;
- v0.8.0 新增Google AI Studio原生集成、Prompt Caching等能力,持续完善国际模型支持。
- 工程化亮点
- 统一Provider抽象层,实现多模型无缝切换,用户可按需选择模型;
- 国内模型直连适配,解决了国内用户的模型接入痛点;
- 环境变量配置,简化了模型密钥的管理与部署。
本地 / ⾃托管模型
| 方案 | 说明 | 适用场景 |
|---|---|---|
| Ollama | 本地运行开源模型,零配置 | 隐私优先、离线使用 |
| vLLM | 高性能推理服务器 | 团队共享 GPU 推理 |
| llama.cpp | 轻量级 CPU/GPU 推理 | 资源受限环境 |
| LM Studio | 桌面 GUI + 本地 API | 不想碰命令行的用户 |
| 任何 OpenAI-compatible | 自定义 base_url |
企业内部模型服务 |
补充解读
这是 Hermes Agent 支持的本地/私有模型部署方案,覆盖了从个人到企业的全场景本地模型需求,核心是通过OpenAI兼容协议,让Agent无缝对接各类本地模型:
- 方案选型逻辑
- 个人离线使用:优先选 Ollama,零配置一键运行开源模型,隐私性拉满;
- 团队共享GPU:选 vLLM,高性能推理服务器,适合团队共享GPU资源;
- 资源受限环境:选 llama.cpp,轻量CPU/GPU推理,适配低配置设备;
- 零命令行用户:选 LM Studio,图形化界面+本地API,无需敲命令;
- 企业内部服务:选 OpenAI兼容方案,自定义
base_url,对接企业内部模型服务。- 工程化价值
- 统一抽象层,让Agent同时支持云模型与本地模型,实现「云+端」全场景适配;
- 支持企业内部模型,满足数据安全与合规要求;
- 零配置本地运行,降低了普通用户的使用门槛。
- 核心亮点:通过OpenAI兼容协议,实现了对所有本地模型的无缝接入,无需修改核心代码,是开源Agent工程化的标准实践。
多 Provider ⽹关
| 网关 | 说明 |
|---|---|
| LiteLLM Proxy | 统一 100+ Provider 的接口和密钥管理 |
| OpenRouter | 自动跨 Provider fallback 和成本优化 |
补充解读
这是 Hermes Agent 支持的两款模型网关方案,用于优化多模型接入、密钥管理与高可用能力:
- LiteLLM Proxy
- 核心能力:统一100+大模型提供商的API接口与密钥管理,让Agent通过统一格式调用任意模型,简化多模型管理;
- 适用场景:企业级多模型统一管理、密钥集中管控,降低多模型接入的复杂度。
- OpenRouter
- 核心能力:自动跨模型故障转移(fallback)与成本优化,当某模型不可用时自动切换其他模型,同时按成本最优选择模型;
- 适用场景:高可用Agent服务、成本敏感场景,保障服务稳定性与成本可控。
- 工程化价值
- 两款网关分别解决了「多模型统一管理」和「高可用+成本优化」两大企业级痛点,与Hermes Agent的多Provider架构完美适配;
- 结合之前的云模型、本地模型方案,形成了完整的「模型-网关-运行时」全链路架构,覆盖从个人到企业的全场景需求。
需要我把这张网关方案表和之前所有的Hermes Agent相关表格,**整合成一份完整的项目技术文档(含架构、部署、配置、生态、竞品对比)**吗?
模型切换⽅式
通过 hermes model 命令或 v0.8.0 新增的 /model 会话内热切换即可完成,⽆需修改代码或重启 (Lesson 2 Lab 中会实际操作):
# 查看当前模型
hermes model
# 切换到 DeepSeek
hermes model deepseek
# 会话中热切换(v0.8.0,模型 ID 可能随版本更新⽽变化)
/model claude-sonnet-4-6
注:国内⽤户的最佳实践是⽇常使⽤ DeepSeek(性价⽐⾼、响应快),遇到复杂推理任务时通过 /model 临时切换到 Claude 或 GPT-5。Nous Portal 的免费 MiMo v2 Pro 可⽤于辅助操作(压缩、摘要等),进⼀步降低成本。
数据来源:Hermes Agent 官⽅⽂档 — AI Providers,版本 v0.8.0。
¶ 4.2 47 个⼯具 x 20 Toolset 全景图(v0.8.0)
Hermes Agent 内置 47 个⼯具,分属 20 个 Toolset。每个 Toolset 可以在启动时按需启⽤或禁⽤(hermes chat --toolsets 'web,terminal' ),也可以在 config.yaml 中为不同平台(CLI / Telegram / Discord 等)配置不同的⼯具组合。
以下按功能分区列出全部 Toolset。标注了本课程重点使⽤的⼯具,帮助你建⽴全景认知。
¶ Hermes Agent v0.8.0 工具集完整速查表
¶ 一、基础能力区
| Toolset | 工具 | 功能一句话 | 课程重点 |
|---|---|---|---|
terminal |
terminal、process |
执行终端命令 + 进程管理,支持 6 种后端(本地/Docker/SSH/Daytona/Modal/Singularity) | 重点 |
file |
read_file、patch |
文件读取与差异补丁编辑 | - |
browser |
browser_navigate、browser_snapshot、browser_vision、browser_scroll、browser_click、browser_type、browser_select、browser_tabs、browser_wait、browser_execute、browser_console 等 11 个工具 |
完整的浏览器自动化——导航、截图、填表、点击,集成 Camofox 反指纹检测浏览器,基于 Firefox | - |
web |
web_search、web_extract |
网页搜索和内容提取 | - |
code_execution |
execute_code |
通过 RPC(远程过程调用)执行 Python 脚本,v0.8.0 支持远程后端 | - |
¶ 二、记忆与成长区
| Toolset | 工具 | 功能一句话 | 课程重点 |
|---|---|---|---|
memory |
memory |
记忆读写(add/replace/remove),Agent 自主维护的核心记忆 | 重点 |
session_search |
session_search |
SQLite FTS5(全文搜索引擎)跨会话全文搜索,~10ms 检索 10k+ 会话 | 重点 |
skills |
skills |
技能搜索、加载与管理——Agent「越用越强」的载体 | 重点 |
¶ 三、自动化与调度区
| Toolset | 工具 | 功能一句话 | 课程重点 |
|---|---|---|---|
cronjob |
cronjob |
自然语言定义定时任务(「每天晚上 10 点备份数据库」) | 重点 |
send_message |
send_message |
跨 14+ 平台的消息投递 | 重点 |
delegation |
delegate_task |
子 Agent 委派——生成隔离上下文的子 Agent 处理子任务 | - |
todo |
todo |
任务规划和追踪(创建 / 追踪 / 完成) | - |
¶ 四、多模态区
| Toolset | 工具 | 功能一句话 | 课程重点 |
|---|---|---|---|
vision |
vision_analyze |
图像理解和分析(截图理解、图表解读、OCR 光学字符识别) | - |
image_gen |
image_generate |
AI 图像生成 | - |
tts |
text_to_speech |
语音合成,v0.8.0 新增 MiniMax TTS Provider | - |
¶ 五、高级与扩展区
| Toolset | 工具 | 功能一句话 | 课程重点 |
|---|---|---|---|
clarify |
clarify |
任务不明确时主动向用户提问(而非硬猜) | - |
moa |
moa |
多模型推理(Mixture of Agents)——多模型混合生成并综合 | - |
homeassistant |
ha_* 系列 |
智能家居控制(灯光、温度、设备状态) | - |
rl |
rl_* 系列 |
RL 训练环境交互(关联 tinker-atropos) | - |
MCP |
动态注册的 mcp_<server>_<tool> |
Model Context Protocol 扩展——无限可扩展的工具生态 | - |
¶ 六、课程重点工具速查
本课程重点使用以下 6 个 Toolset,对应 Lesson 2 的四大案例:
| Toolset | Lesson 2 对应案例 | 核心演示场景 |
|---|---|---|
terminal |
案例 A:终端 Agent | 让 Agent 分析开发环境、管理文件、执行部署 |
memory + session_search |
案例 C:持久记忆 | 展示 Agent 如何跨会话记住信息 |
cronjob + send_message |
案例 B:飞书 IM Agent | 定时任务 + 消息推送 = 7×24 自主工作 |
skills |
案例 D:Skill 自主进化 | 观察 Agent 自动提炼可复用技能 |
¶ 补充说明
注:完整工具列表可通过
hermes tools命令查看。Toolset 的启用/禁用支持按会话配置,你可以为不同场景创建不同的工具组合。
数据来源:Hermes Agent 官方文档 — Tools,版本 v0.8.0。
¶ 4.3 v0.8.0 核⼼亮点速览
v0.8.0(代号 "The Intelligence Release")于 2026 年 4 ⽉ 8 ⽇发布,距上个⼤版本 v0.7.0 仅 5 天。本次更新包含 209 个合并 PR、82 个已解决 Issue,18 位社区贡献者参与。如果说 v0.7.0 让 Hermes Agent 从"实验性"⾛向"企业级"(安全加固、凭证轮换、沙箱),那 v0.8.0 让它在"智能化"上跃升了⼀个台阶。
以下挑出三个对⽇常使⽤感知最强的亮点详述,其余以要点列表呈现。
亮点⼀:会话中模型热切换(/model 命令)
痛点:之前想换个模型试试,需要退出当前会话、修改配置、重新启动。对话上下⽂全部丢失。
v0.8.0 ⽅案:在 CLI、Telegram、Discord、Slack 以及所有 Gateway 平台上,⼀条命令即可在会话中切换模型和 Provider,对话上下⽂保持不变。
/model deepseek # 切到 DeepSeek
/model claude-sonnet # 遇到复杂推理,临时切 Claude
/model mimo-v2-pro # 简单任务切回免费模型
技术细节:
- Aggregator-aware resolution:优先通过 OpenRouter / Nous Portal 聚合路由,⾃动跨 Provider fallback
- Telegram / Discord 交互式 picker:内联按钮选择模型,⽀持分页浏览
--global持久化:/model deepseek --global将选择保存到配置⽂件
实际⽤法:⽇常聊天⽤ DeepSeek(便宜),遇到复杂推理任务临时切到 Claude 或 GPT-5,⼀条命令完成,不⽤退出会话。
亮点⼆:免费 MiMo v2 Pro(Nous Portal)
痛点:Agent 的辅助操作(上下⽂压缩、视觉处理、摘要提取等)虽然不是主对话,但也在消耗 API 额度,⽇积⽉累成本可观。
v0.8.0 ⽅案:Nous Portal 提供⼩⽶ MiMo v2 Pro 模型的免费访问,专门⽤于这些辅助操作。主对话继续⽤你选择的模型(DeepSeek / Claude / GPT-5),后台的辅助调⽤⾛免费通道。
成本影响:对于⽇常使⽤场景,辅助操作⼤约占总 token 消耗的 20-30%。这部分归零后,Hermes Agent 的⽇常使⽤成本进⼀步降低——配合 DeepSeek 作为主模型,⽉均成本可以控制在⼏元⼈民币级别。
亮点三:后台任务⾃动通知(notify_on_complete )
痛点:让 Agent 在后台跑⼀个长耗时任务(模型训练、测试套件、部署构建),然后 Agent 要么反复轮询浪费 token,要么⼲脆"忘了"有任务在跑。
v0.8.0 ⽅案:新增 notify_on_complete 功能。后台任务完成时系统主动回调通知 Agent,Agent 可以做到真正的 fire-and-forget——"你去跑这个测试套件,跑完告诉我结果,我先做别的事"。
为什么重要:这是 Agent ⾃主性的关键⼀步。以前 Agent 处理长任务的⽅式和⼈类⼀样低效(隔⼀会⼉查⼀下),现在它可以真正地并⾏处理多件事,被动等待通知⽽不是主动轮询。
其他 v0.8.0 改进要点
Provider 层:
- Google AI Studio(Gemini)原⽣集成,⾃动上下⽂长度检测
- GPT / Codex 系列 5 种 tool calling 失败模式⾃动修复
- xAI(Grok)Prompt Caching ⽀持
- ⾮ agentic 模型警告(识别不⽀持 tool calling 的模型)
安全层:
- MCP OAuth 2.1 PKCE(Proof Key for Code Exchange,授权码交换证明密钥)认证——安全连接企业内部 MCP Server
- OSV(Open Source Vulnerabilities,开源漏洞数据库)恶意软件扫描——⾃动检测 MCP 扩展包已知漏洞
- SSRF(Server-Side Request Forgery,服务端请求伪造)防护、定时攻击缓解、tar 遍历防护
平台层:
- Matrix 升级为 Tier 1 ⽀持(reactions、已读回执、富⽂本)
- Slack / Telegram 危险命令审批改为原⽣按钮(不⽤打字 /approve 了)
- 基于活跃度的超时——长时间运⾏但持续活跃的任务不再被误杀
插件系统:
- CLI ⼦命令注册
- Request-scoped API hooks(带 correlation ID)
- Session lifecycle hooks(
on_session_finalize/on_session_reset)
记忆层:
- 新增 Supermemory Provider(语义图谱 + context fencing)
- Profile-scoped 记忆隔离
- Shared thread sessions 默认启⽤
⽂档与质量:
- 全⾯⽂档审计,修复 40+ 差异
- 57 个失败 CI(持续集成,代码提交后⾃动运⾏的测试流程)测试修复
- 3 个新教程(Docker setup / 本地 LLM 指南 / Signal 配置)
数据来源:Hermes Agent v0.8.0 Release Notes。
到这⾥,我们已经从概念、架构、⽣态、实⽤参考四个维度完成了对 Hermes Agent 的全⾯认识。纸上得来终觉浅——接下来,让我们动⼿把它装到你的机器上。
¶ 5 动⼿实操
¶ 5.1 三条命令跑通你的第⼀个 Agent
前⾯我们花了不少篇幅建⽴认知框架——Harness Engineering 的理论、OpenClaw 的对⽐、项⽬⽣态的全景。现在,是时候动⼿了。
接下来我们要做三件事:安装 Hermes Agent v0.8.0、配置 DeepSeek 国内直连、跟 Agent 进⾏第⼀次真正的中⽂对话。整个过程不需要翻墙,不需要写代码,不需要提前安装 Python 或 Node.js ——安装脚本会⾃动搞定⼀切。
注:本节所有操作在 macOS(Mac Mini M4)上执⾏并截图。Linux ⽤户操作完全相同,Windows ⽤户需要先安装 WSL2。
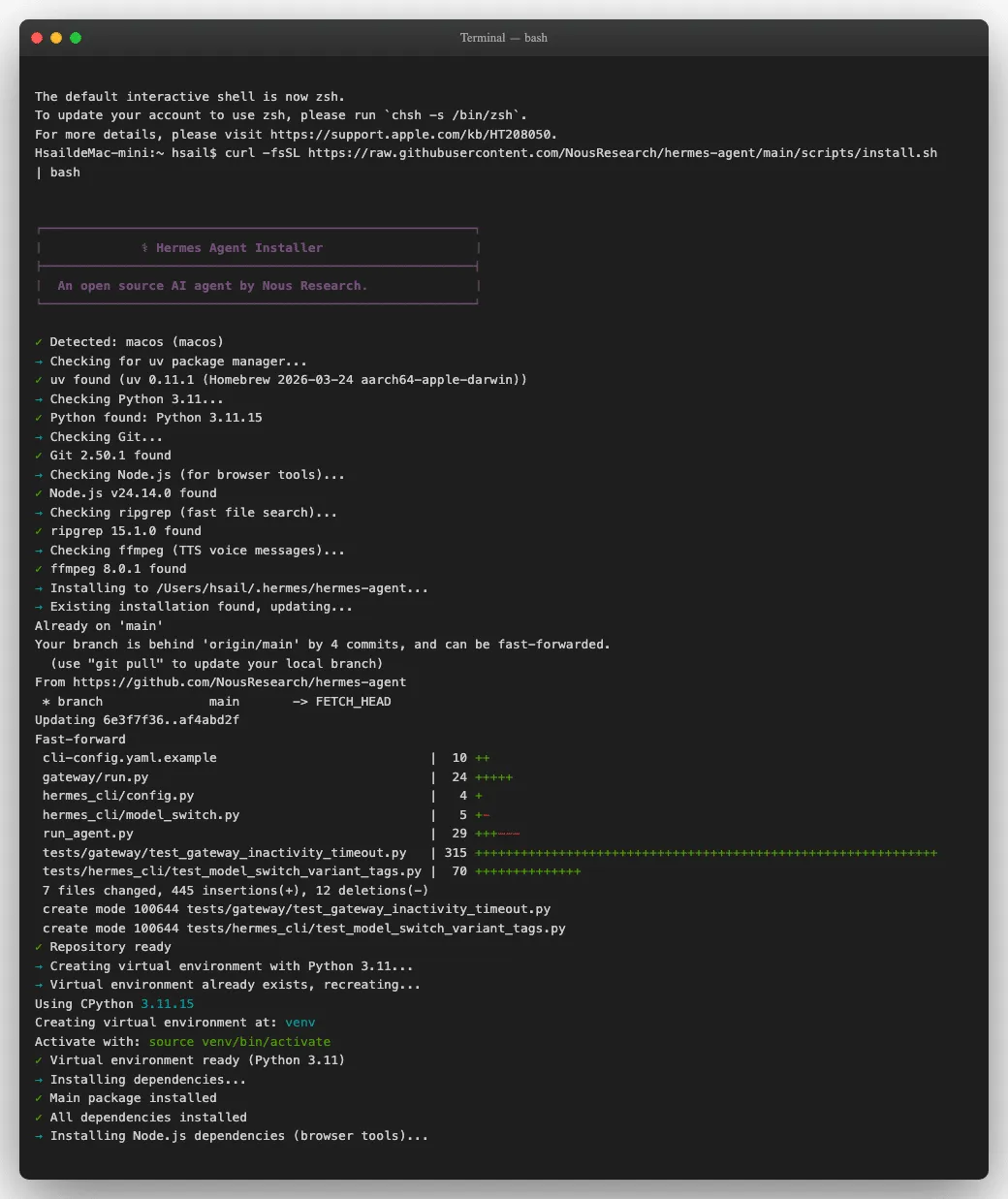
第⼀步:⼀⾏命令安装
打开你的终端,输⼊这⾏命令:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermesagent/main/scripts/install.sh | bash
按下回车后,你会看到⼀个颇有仪式感的安装横幅——"Hermes Agent Installer / An open source AI agent by Nous Research":
安装脚本会⾃动检测你的系统环境,逐项确认需要的依赖:
| 依赖 | 用途 | 安装脚本的处理 |
|---|---|---|
| uv | Python 包管理器(替代 pip) | 自动安装 |
| Python 3.11 | Hermes Agent 核心运行环境 | 自动安装 |
| Node.js v22 | 浏览器自动化等前端工具 | 自动安装 |
| ripgrep | 高速文件搜索 | 自动安装 |
| ffmpeg | 语音消息转换 | 自动安装 |
| Git | 代码仓库管理 | 需提前安装(macOS 自带) |
补充说明
这是 Hermes Agent 一键安装脚本的依赖清单,核心特点:
- 零配置安装:除 Git 外,所有依赖(
uv/Python 3.11/Node.js v22/ripgrep/ffmpeg)均由安装脚本自动完成,用户无需手动配置,真正实现「一行curl安装,零代码启动」;- 依赖分工明确:
uv:替代传统pip,实现极速Python包管理,提升安装与依赖管理效率;Python 3.11:项目核心运行环境,保障Agent引擎稳定运行;Node.js v22:支撑浏览器自动化等前端能力;ripgrep:提供高速文件搜索,优化会话检索性能;ffmpeg:处理语音消息转换,支撑TTS等多模态能力;Git:代码仓库管理,用于项目拉取与更新,macOS系统自带,其他系统需提前安装。- 工程化亮点:通过自动化安装脚本,彻底降低了项目的上手门槛,让普通用户无需处理复杂的环境配置,即可快速部署Agent。
你不需要⼿动安装以上任何⼀项——安装脚本会检测已有的版本,缺什么补什么。整个过程⼤约 5-10 分钟。
如果安装在 "Installing Node.js dependencies" 这⼀步卡住了——别慌。这⼀步需要下载浏览器引擎(约 200MB),在国内⽹络环境下可能需要 10-15 分钟。安装脚本有容错机制,即使这⼀步下载失败也不影响核⼼功能,浏览器⼯具会在⾸次使⽤时⾃动重试。
安装完成后,重新加载终端配置:
source ~/.zshrc # macOS 默认 shell
# 或者 source ~/.bashrc(如果你⽤ bash)
第⼆步:确认安装成功
运⾏版本检查命令:
hermes --version
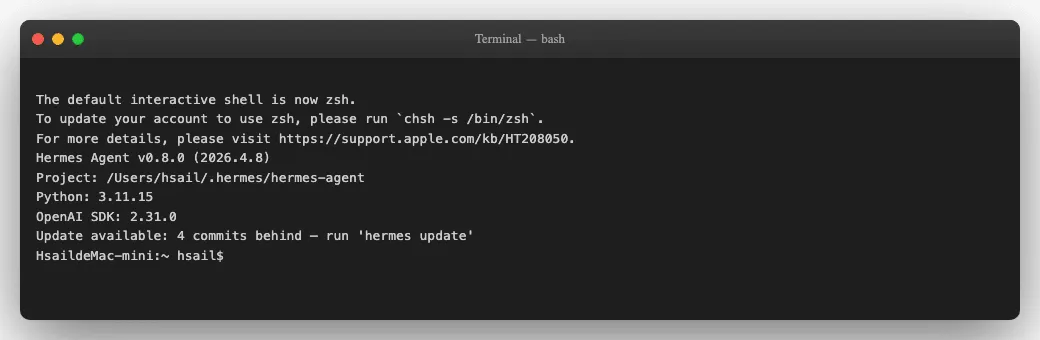
你应该看到类似这样的输出:
Hermes Agent v0.8.0 (2026.4.8)
Project: /Users/你的⽤户名/.hermes/hermes-agent
Python: 3.11.15
OpenAI SDK: 2.31.0
确认版本号是 v0.8.0,就说明安装成功了。如果提⽰ "Update available",暂时忽略——我们整个课程锁定这个版本。
接下来跑⼀遍环境体检:
hermes doctor
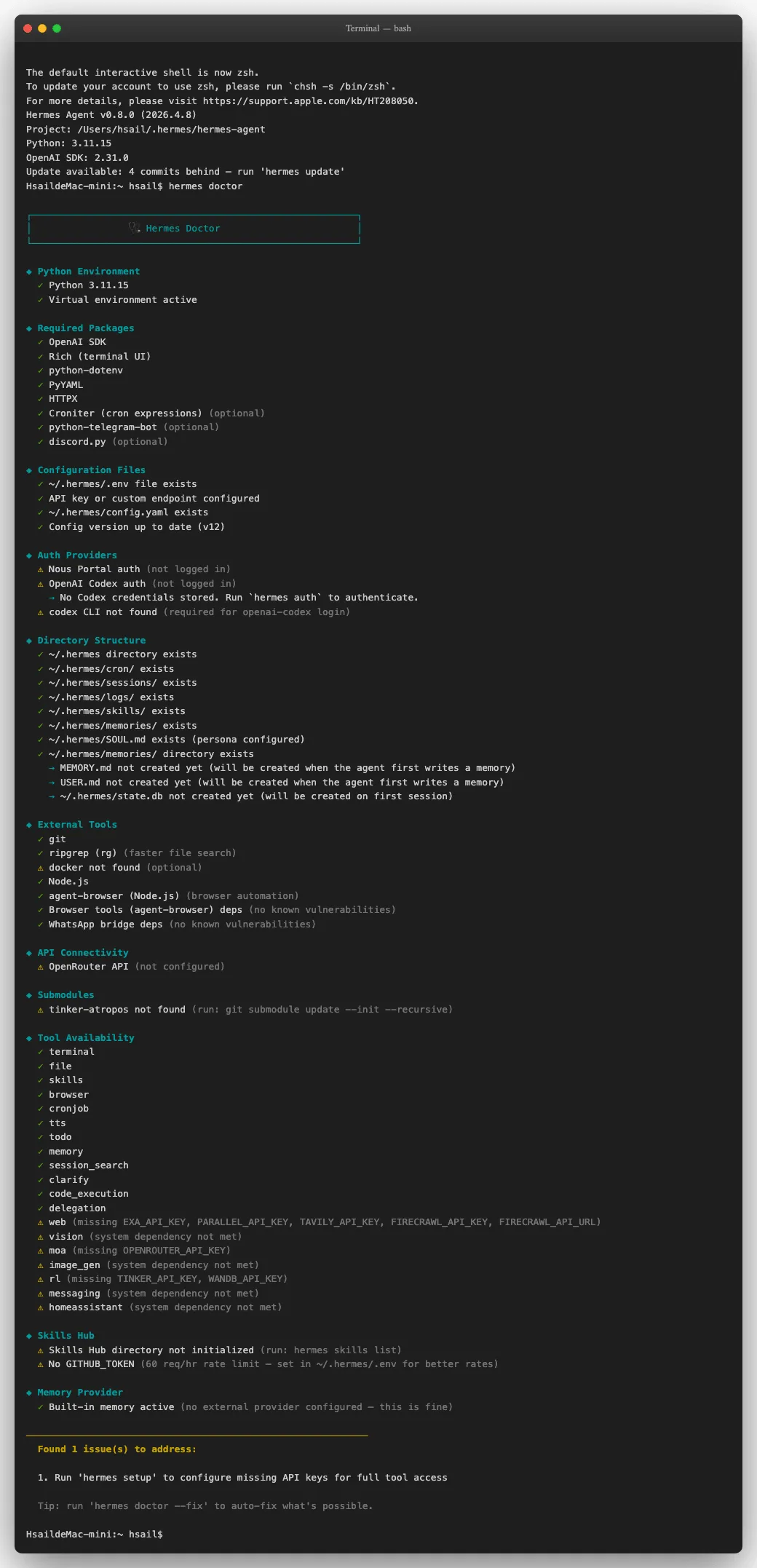
hermes doctor 会对 Hermes Agent 的所有组件做⼀次全⾯体检,分成 11 个⼤类逐项检查。重点关注以下⼏项:
| 检查项 | 预期状态 | 说明 |
|---|---|---|
| Python Environment | ✓ 全绿 | Python 3.11 + 虚拟环境激活 |
| Required Packages | ✓ 全绿 | OpenAI SDK、Rich、HTTPX 等核心包 |
| Configuration Files | ✓ 全绿 | .env 和 config.yaml 存在 |
| Directory Structure | ✓ 全绿 | ~/.hermes 目录结构完整 |
| Tool Availability | ✓ 核心工具全绿 | terminal / file / skills / browser / memory |
补充解读
这是 Hermes Agent 安装完成后的环境自检清单,用于验证部署是否成功:
- 检查项分层逻辑:从「运行环境」→「依赖包」→「配置文件」→「目录结构」→「工具可用性」,逐层验证Agent的运行基础,确保所有核心组件正常工作;
- 核心检查项说明
- Python Environment:验证Python 3.11版本与虚拟环境激活状态,是Agent的运行基础;
- Required Packages:验证OpenAI SDK、Rich、HTTPX等核心依赖包安装完整;
- Configuration Files:验证
.env(密钥配置)与config.yaml(项目配置)文件存在,是Agent启动的必要条件;- Directory Structure:验证
~/.hermes目录结构完整,包含记忆、技能、日志等核心目录;- Tool Availability:验证
terminal/file/skills/browser/memory等核心工具集可用,是Agent能力的核心保障。- 工程化亮点:通过自动化自检,让用户快速确认部署状态,无需手动排查环境问题,降低了项目的运维门槛。
你可能会看到⼀些黄⾊警告(⚠),⽐如 "Docker not found" 或 "OpenRouter API not configured"——这些都是可选功能,不影响核⼼使⽤。只要 Python 环境、核⼼包、配置⽂件、⽬录结构这四⼤类全绿,就可以放⼼进⼊下⼀步。
第三步:配置 DeepSeek 国内直连
Hermes Agent ⽀持 18+ 模型提供商,但对国内⽤户来说,最推荐的⾸选是 DeepSeek——完全不需要翻墙,API 稳定,价格亲民(100 万 tokens 约 1 元⼈民币)。
配置只需要三条命令:
# 1. 设置默认模型为 DeepSeek Chat
hermes config set model.default deepseek-chat
# 2. 设置模型提供商为 DeepSeek
hermes config set model.provider deepseek
# 3. 在 .env ⽂件中写⼊ API Key
echo 'DEEPSEEK_API_KEY=你的API Key' >> ~/.hermes/.env
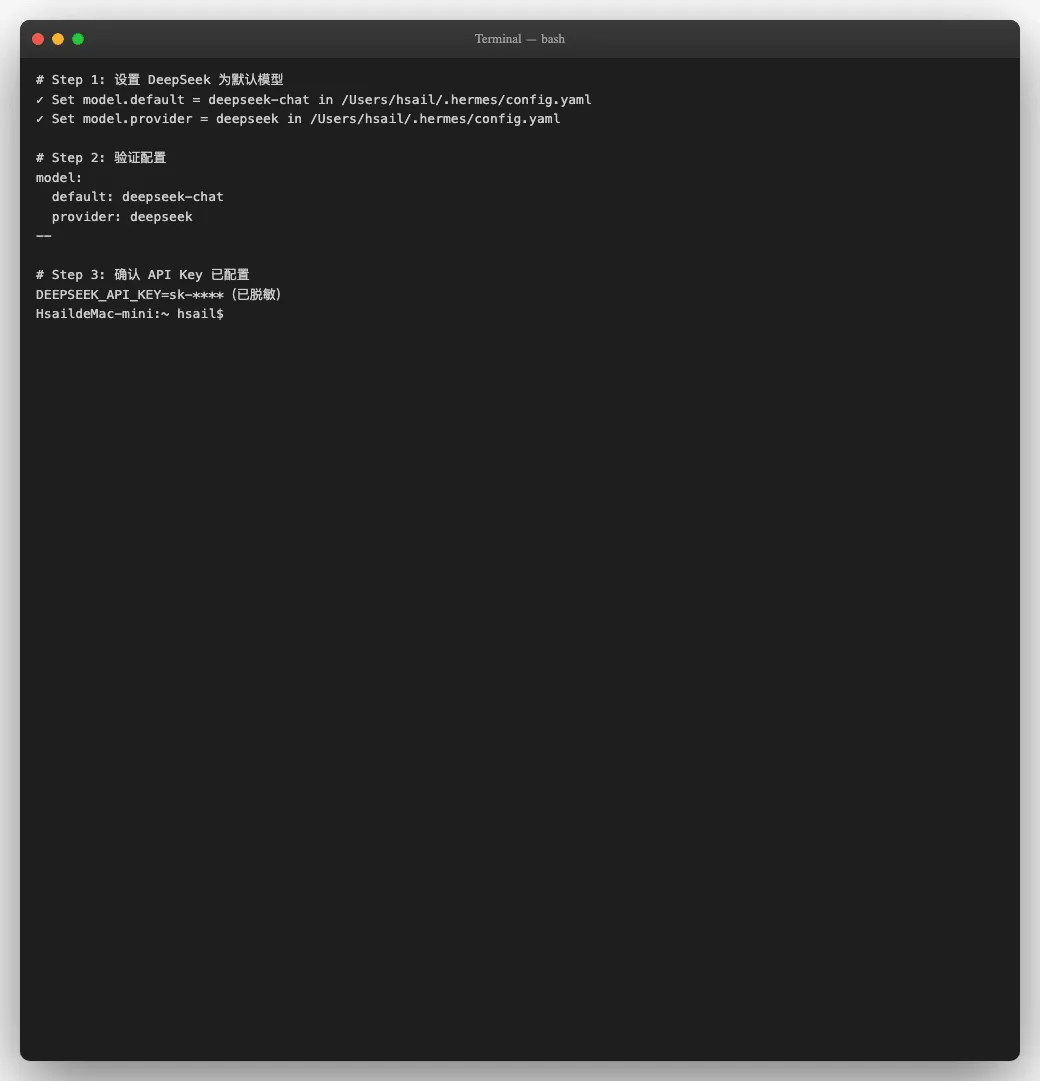
三条命令执⾏完毕,config.yaml 中的 model.default 变为 deepseek-chat ,model.provider 变为 deepseek ,.env 中已写⼊ API Key。
如何获取 DeepSeek API Key
如果你还没有 DeepSeek 的 API Key,获取步骤如下:
- 使⽤⼿机号注册/登录(⽀持 Google 账号登录)
- 进⼊"API Keys"页⾯,点击"创建 API Key"
- 复制⽣成的 Key(格式类似
sk-xxxxxxxxxxxxxxxx)
新注册⽤户通常有免费额度,⾜够完成本课程所有实验。
Watch-out:如果你之前使⽤过其他模型提供商(如 OpenRouter),config.yaml 中可能残留
base_url配置。这个遗留配置会⼲扰 DeepSeek 直连。遇到配置后⾏为异常时,运⾏hermes config set model.base_url ''清除它。
见证时刻:第⼀次中⽂对话
⼀切就绪,现在来跟 Hermes Agent 进⾏第⼀次对话。我们不做⽆聊的 "Hello World"——让 Agent 做⼀件有实际价值的事情:
hermes chat -q '帮我分析⼀下当前的开发环境——装了什么编程语⾔、什么包管理器、磁盘还剩多少空间'
按下回车的瞬间,你会看到 Hermes Agent 标志性的 ASCII 启动画⾯:
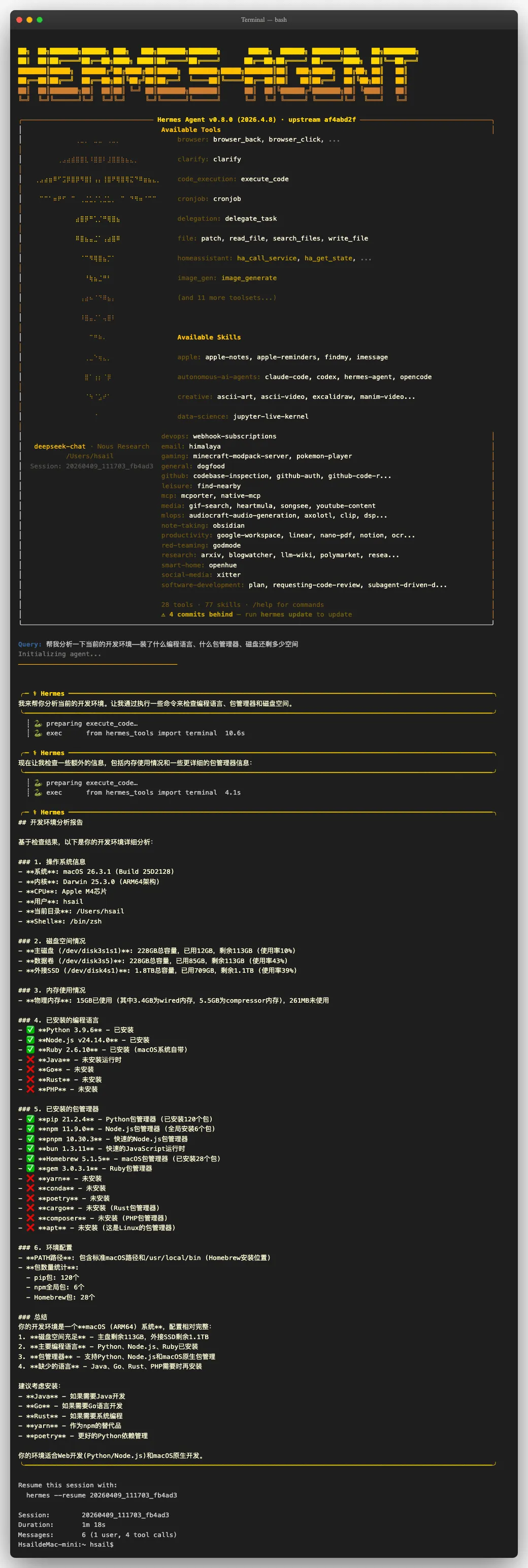
让我们⼀起看看发⽣了什么:
启动画⾯——巨⼤的 "HERMES-AGENT" ASCII 字符画,加上版本号 v0.8.0 和当前使⽤的模型 deepseek-chat 。⾯板右侧列出了 28 个可⽤⼯具和 77 个可安装技能。这不是⼀个简单的聊天机器⼈——这是⼀个装备齐全的 Agent。
Agent 开始⼯作——收到我们的中⽂提问后,Agent ⾸先回复:"我来帮你分析当前的开发环境。让我通过执⾏⼀些命令来检查编程语⾔、包管理器和磁盘空间。" 然后它主动调⽤了 terminal ⼯具( execute_code ),在你的机器上真实执⾏了系统命令。
第⼀次⼯具调⽤(10.6 秒)——Agent 调⽤ terminal ⼯具,执⾏了⼀系列系统命令来检测编程语⾔和磁盘空间。
第⼆次⼯具调⽤(4.1 秒)——Agent 判断信息还不够完整,主动发起了第⼆次⼯具调⽤,补充检查了内存使⽤和更详细的包管理器信息。
最终报告——Agent 输出了⼀份结构化的中⽂开发环境分析报告:
| 分析维度 | 我们实验中的结果 |
|---|---|
| 操作系统 | macOS 26.3.1 (Apple M4) |
| 磁盘空间 | 主盘剩余 113GB(228GB 总容量) |
| 编程语言 | ✅ Python / ✅ Node.js / ✅ Ruby |
| 包管理器 | ✅ pip / ✅ npm / ✅ pnpm / ✅ bun / ✅ Homebrew |
整个对话耗时 1 分 18 秒,Agent 共调⽤了 4 次⼯具。从输⼊⼀⾏中⽂到得到⼀份完整的系统分析报告——这就是 Agent 运⾏时的⼒量。
注:你在⾃⼰的机器上跑会看到不同的结果——这正是 Agent 的价值所在:它不是在背诵固定答案,⽽是真实地在你的系统上执⾏命令,分析你的实际环境。
Hermes Agent 的对话⽅式全览
hermes chat -q 只是冰⼭⼀⾓。Hermes Agent 围绕⼀个 AIAgent 核⼼类,同时服务五种⼊口,覆盖从个⼈终端到团队协作再到 IDE 集成的全场景。
| 对话方式 | 说明 | 示例命令 |
|---|---|---|
| 交互式终端(默认) | 全功能 TUI,支持多行编辑、斜杠命令自动补全、流式工具输出 | hermes 或 hermes chat |
| 快速提问(Non-interactive) | 单次提问直接返回,适合脚本调用和自动化 | hermes chat -q "用 Python 写一个快排" |
| 指定模型 | 覆盖默认模型,临时切换 | hermes chat -m "anthropic/claude-sonnet-4" |
| 指定 Provider | 强制走某个模型提供商 | hermes chat --provider deepseek |
| 指定工具集 | 只启用部分工具,减少 token 开销 | hermes chat -t "web,terminal" |
| 预加载技能 | 启动时加载特定 Skill | hermes chat -s github-pr-workflow |
| 会话恢复 | 恢复上次或指定会话的完整上下文 | hermes -c 或 hermes -r <session_id> |
| Git Worktree 隔离 | 在独立 worktree 中工作,适合并行任务 | hermes -w -q "Fix issue #123" |
| YOLO 模式 | 跳过所有危险命令审批提示 | hermes --yolo |
| 静默模式(Programmatic) | 抑制 banner/spinner/工具预览,适合程序集成 | hermes chat -Q -q "查询天气" |
| 消息网关 | 接入 14+ 平台(Telegram/Discord/Slack/飞书/钉钉等) | hermes gateway |
| ACP Server (IDE 集成) | 作为 Agent Client Protocol 服务器运行,接入 VS Code/Zed/JetBrains | hermes acp |
| MCP Server | 将 Hermes 暴露为 MCP 服务器,供其他 MCP 客户端调用 | hermes mcp serve |
| Cron 定时任务 | 自然语言配置定时任务,Agent 按计划自动执行 | hermes cron create |
| Webhook 驱动 | 外部事件触发 Agent 执行 | hermes webhook subscribe |
| Batch 轨迹生成 | 批量生成 Agent 交互轨迹,用于 RL 训练数据集 | batch_runner.py(研究用途) |
⼏个值得注意的细节:第⼀,全局标志 -c 、 -w 、 --yolo 等可以直接挂在 hermes 后⾯⽽不必写 hermes chat ,⽐如 hermes -c 等价于 hermes chat -c 。第⼆,会话中可以⽤ /model斜杠命令热切换模型,⽆需退出重进——在 Telegram 和 Discord 上甚⾄提供内联按钮选择器。第三, -Q ( --quiet )静默模式是程序化集成的关键:它抑制所有装饰性输出,只返回 Agent 的纯⽂本回复,⽅便管道拼接和脚本解析。
这⼀步完成后你拥有了什么
恭喜,你现在拥有了⼀个完整可⽤的 Hermes Agent v0.8.0 环境:
- 安装就绪:所有依赖⾃动配置完成
- 国内直连:DeepSeek 模型⽆需翻墙
- 端到端验证:Agent 已成功完成⼯具调⽤ + 中⽂对话
从现在开始,你可以随时打开终端输⼊ hermes 启动交互式对话,让 Agent 帮你做⽂件管理、信息搜索、代码分析等各种任务。在 Lesson 2 中,我们将深⼊探索 Hermes Agent 的四⼤核⼼能⼒——飞书集成、持久记忆、Skill ⾃动⽣成——每⼀个都会让你对 Agent 运⾏时有更深的理
解。
动⼿安装完成后,我们已经亲⾝体验了 Hermes Agent 的基本能⼒。在结束本节课之前,让我们把视⾓拉⾼⼀层——把 Hermes Agent 放进整个 Agent 技术⽣态中,看看它和 LangChain、Google ADK、Claude Code 这些名字到底是什么关系。
¶ 6 Agent 技术⽣态定位
¶ 6.1 两⼤阵营:通⽤智能体 vs Agent 开发框架
LangChain、Google ADK、Claude Code、Manus、Hermes Agent——这些名字都跟 Agent 有关,但它们解决的问题截然不同。与其按产品逐个介绍,不如⽤⼀条更清晰的线来划分:你需不需要写代码?
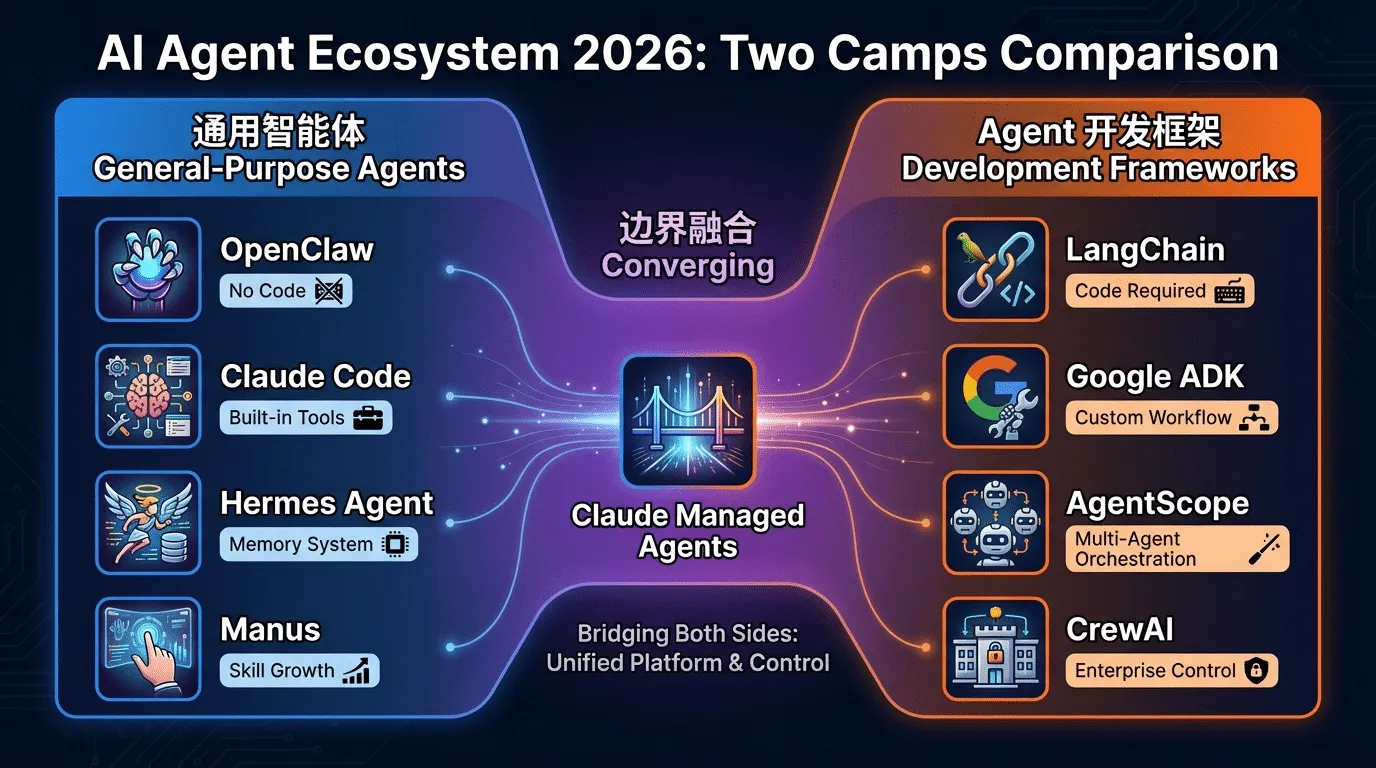
通⽤智能体(也叫 Agent Runtime)——安装即⽤,⾃然语⾔交互。OpenClaw、Claude Code、Hermes Agent、Manus 都属于这⼀阵营。它们内置⼯具⽣态和记忆系统,通过 Skill / Agent Team / 插
件扩展能⼒。Claude Code 的 Agent Teams 模式已经可以让多个 Agent 共享任务列表、并⾏协作——早已超越了"编码助⼿"的定位。
Agent 开发框架——提供组件和编排能⼒,需要写代码构建定制 Agent。LangChain / LangGraph、Google ADK、AgentScope、CrewAI 属于这⼀阵营。LangGraph ⽤有向图定义状态机来精确控制流程,Google ADK 提供多语⾔⽀持和原⽣ Vertex AI 集成。它们的受众是开发者,产出的是Agent 应⽤。
| 维度 | 通用智能体 | Agent 开发框架 |
|---|---|---|
| 上手方式 | 安装即用,自然语言交互 | 写 Python / TS 代码定义 Agent |
| 代码量 | 0(配置为主) | 50 - 500+ 行起步 |
| 扩展机制 | Skill / 插件 / Agent Team | 自定义 Tool / Chain / Graph |
| 适合谁 | 所有人(含非开发者) | 有编程能力的开发者 |
| 典型场景 | 日常助手、IM 集成、自动化 | 企业级工作流、定制 Agent 产品 |
¶ 6.2 通⽤智能体时代,还需要学开发框架吗?
通⽤智能体越来越强——Hermes Agent 的技能⾃⽣成让 Agent 越⽤越聪明(10-20 次同类任务后效率提升 2-3 倍),Claude Code Agent Teams 可以并⾏多个⼦ Agent 协作。既然"开箱即⽤"已经这么能⼲,为什么还要费劲去写 LangGraph?
答案取决于场景。⽇常使⽤,通⽤智能体⾜够了——消息平台集成、⽂件管理、信息搜索、代码分析,Hermes Agent 加 OpenClaw 就能搞定。但⽣产级应⽤,开发框架仍然不可替代。LangChain 2026 年⾏业报告显⽰ 57% 的受访企业已将 Agent 部署到⽣产环境,这些系统需要精确流程控制、跨系统状态持久化、合规审计和安全策略——通⽤智能体⽬前做不到这种深度定制。
简单判断:⽤ Agent 做事,选通⽤智能体;造 Agent 产品,⽤开发框架。
¶ 6.3 边界正在融合:Claude Managed Agents 的启⽰
2026 年 4 ⽉ 8 ⽇,Anthropic 发布了 Claude Managed Agents——这个产品代表了两⼤阵营融合的趋势。
传统 Agent 开发,你不仅要写逻辑,还要搞定容器编排、状态管理、错误恢复、可观测性。Claude Managed Agents 的做法是:Anthropic 负责所有基础设施,你只写 Agent 核⼼逻辑。 ⾃动隔离容器、管理状态、编排⼯具调⽤、错误恢复,甚⾄⽀持 Agent 派⽣⼦ Agent。Notion、Rakuten、Asana 已是⾸批⽤户,定价为 token 费⽤加每⼩时 0.08 美元运⾏时。
以前的选择是:要么⽤现成通⽤智能体,要么从头搭建⼀切。Managed Agents 创造了中间地带——写 Agent 逻辑,不写基础设施代码。Google ADK 的 Vertex AI 托管部署、LangChain 与 NVIDIA
的企业平台,⾛的都是同⼀⽅向。
¶ 6.4 选择建议:你应该学什么?
| 你的目标 | 建议路径 |
|---|---|
| 提高日常工作效率 | 先学通用智能体(本课程重点)。Hermes Agent + OpenClaw 覆盖绝大多数个人场景 |
| 构建定制 Agent 产品 | 两者都学。先用通用智能体理解能力边界,再用 LangGraph 或 Google ADK 做精确编排 |
| 深度理解 Agent 工程化 | 从 Harness Engineering 入手(本课程核心方法论),再选框架深入实践 |
补充解读
这是一份AI Agent学习路径的精准选型指南,针对不同目标给出了清晰的学习路线:
- 目标1:提高日常工作效率(个人用户首选)
- 核心方案:直接学习通用智能体(Hermes Agent + OpenClaw),零代码、开箱即用,快速提升日常工作、开发、自动化效率,覆盖绝大多数个人场景;
- 优势:无需编程基础,安装即用,快速见效。
- 目标2:构建定制Agent产品(企业/开发者)
- 核心方案:通用智能体 + 开发框架结合学习;
- 步骤:先用Hermes Agent等通用智能体理解Agent的能力边界与使用场景,再用LangGraph/Google ADK等开发框架做精确编排,搭建定制化Agent产品;
- 优势:兼顾易用性与灵活性,从产品视角理解Agent,再落地开发。
- 目标3:深度理解Agent工程化(技术专家/架构师)
- 核心方案:从Harness Engineering(本课程核心方法论)入手,先掌握Agent工程化的核心设计思想,再深入学习开发框架与实践;
- 优势:从底层原理理解Agent的设计逻辑,构建可落地、可扩展的Agent系统,是Agent架构师的核心能力。
- 学习路径总结
- 个人用户:直接学通用智能体(Hermes Agent)
- 企业开发者:通用智能体 → 开发框架
- 技术专家:Harness Engineering → 开发框架
⼀个务实的标准:如果需求能⽤⾃然语⾔描述清楚,通⽤智能体⼤概率能搞定;如果需要画流程图定义 Agent ⾏为,该上开发框架了。 这门课从 Hermes Agent 切⼊,正是因为它能让你最快地从"了解Agent"变成"⽤好 Agent"——⽽ Harness Engineering 的思维⽅式,⽆论将来⽤什么⼯具都能迁移。
数据来源:各产品 GitHub 仓库及官⽅⽂档。LangChain / LangGraph / Google ADK / AgentScope / Hermes Agent。